Google Patents a Fix That Warns Its AI When Your Words Were Misheard
Every voice assistant has the same embarrassing flaw: when speech-to-text garbles your words, the AI underneath just runs with the gibberish. Google's new patent proposes a fix — tell the LLM upfront that the text it's reading might be wrong, and hand it a cheat sheet of common mistakes.
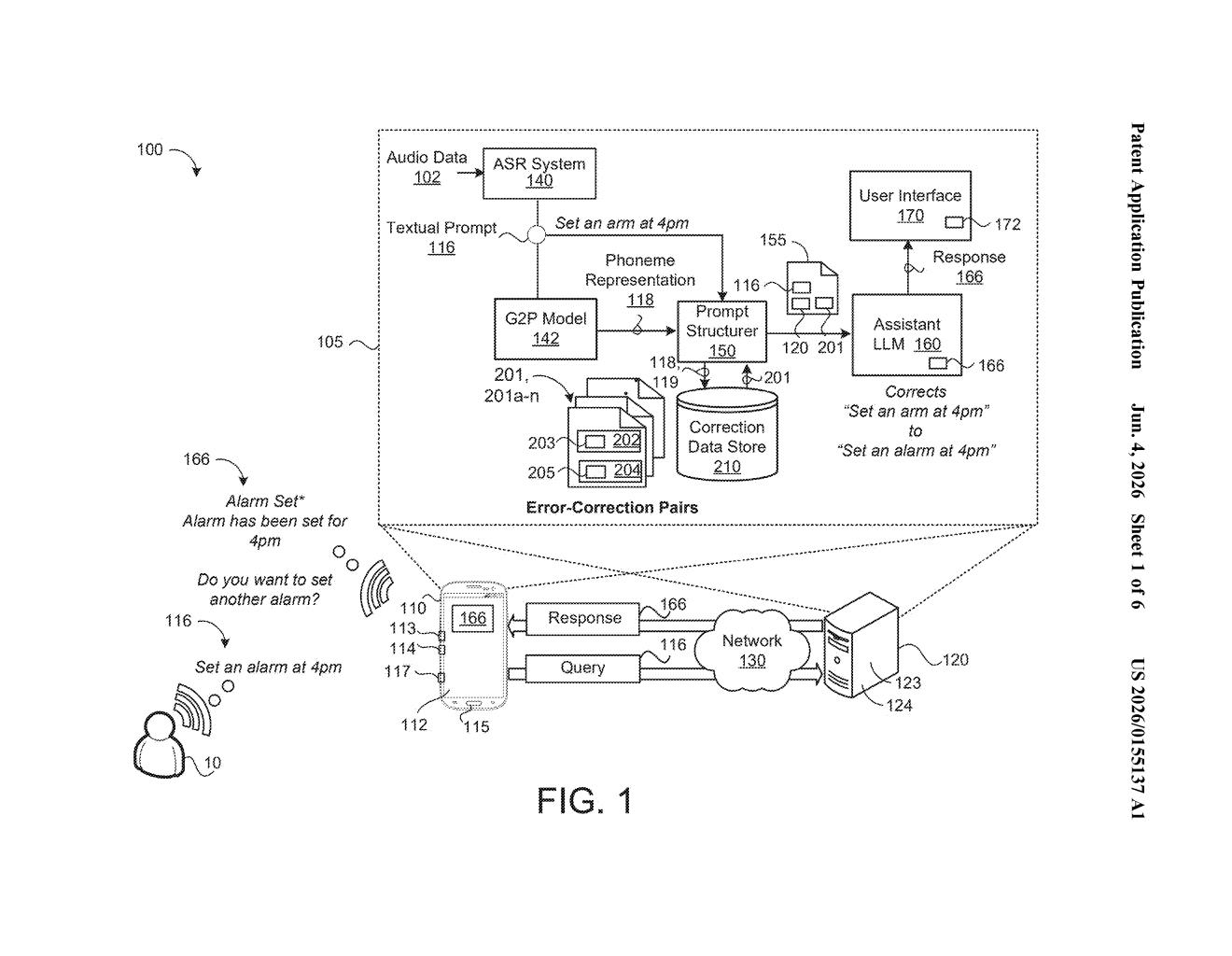
What Google's speech-error-aware AI assistant actually does
Imagine you ask your phone's assistant, "Set a timer for fiteen minutes" — but the speech-to-text mishears it as "fight teen minutes." A normal AI assistant sees that nonsense and either fails or answers something completely off-base.
Google's patent describes a layer that sits between the voice recognition system and the AI assistant. When your voice is transcribed, the system doesn't just pass the text along — it also sends a heads-up note saying, in effect, "this came from speech-to-text and might contain errors." Alongside that warning, it includes a list of known misrecognition pairs: phrases that often get garbled and what they were probably supposed to say.
The result is an AI that's been primed to read between the lines of what it was handed. Instead of tripping over a weird transcription, it can make a reasonable guess at what you actually said and answer accordingly.
How the misrecognition awareness prompt gets structured
The patent describes a pipeline where an automatic speech recognition (ASR) system — the software that turns your spoken words into text — hands its output to a large language model (LLM)-powered assistant like Google Assistant or Gemini.
The key addition is a "speech misrecognition awareness prompt" that gets constructed and attached to the transcribed text before the LLM ever sees it. This prompt has two parts:
- An awareness message: A plain-language note telling the LLM that the input came from an ASR system and may contain transcription errors.
- Error-correction pairs: A structured list of known or likely misrecognized phrases alongside their probable intended corrections (e.g., "fight teen" → "fifteen").
The LLM then processes the original transcribed text but does so conditioned on (meaning, with awareness of) the misrecognition context — similar to how you might read a message differently if a friend warned you beforehand that autocorrect had mangled it. The patent doesn't specify exactly where the error-correction pairs come from, but they likely draw on logged ASR error patterns or device-specific misrecognition data.
What this means for voice assistants that mishear you
Voice assistants have improved dramatically, but the handoff between speech-to-text and the AI reasoning layer is still a weak link. When transcription fails, the downstream AI has no idea — it treats garbled output as intentional input. This patent addresses that gap by making the error a first-class piece of context rather than an invisible failure.
For Google Assistant and Gemini, this could meaningfully improve reliability in noisy environments, for accented speakers, or for technical vocabulary that ASR systems routinely butcher. If this approach ships, you'd notice it as fewer "I didn't understand that" failures and more situations where the assistant correctly infers what you meant even when the transcript was wrong.
This is a genuinely practical idea — it's essentially prompt engineering applied to a real-world reliability problem. The elegance is that it doesn't require retraining the ASR or the LLM; it just changes what context you hand the model. Whether it works well in practice depends heavily on how the error-correction pairs are sourced and kept fresh, which the patent doesn't fully answer.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.