Google Patents AI That Processes Language Using Far Less Computing Power
Attention mechanisms are what make modern AI models like GPT actually work — but they're brutally expensive to run at scale. Google's patent describes a way to make them dramatically cheaper by using a mathematical shortcut called locality-sensitive hashing.
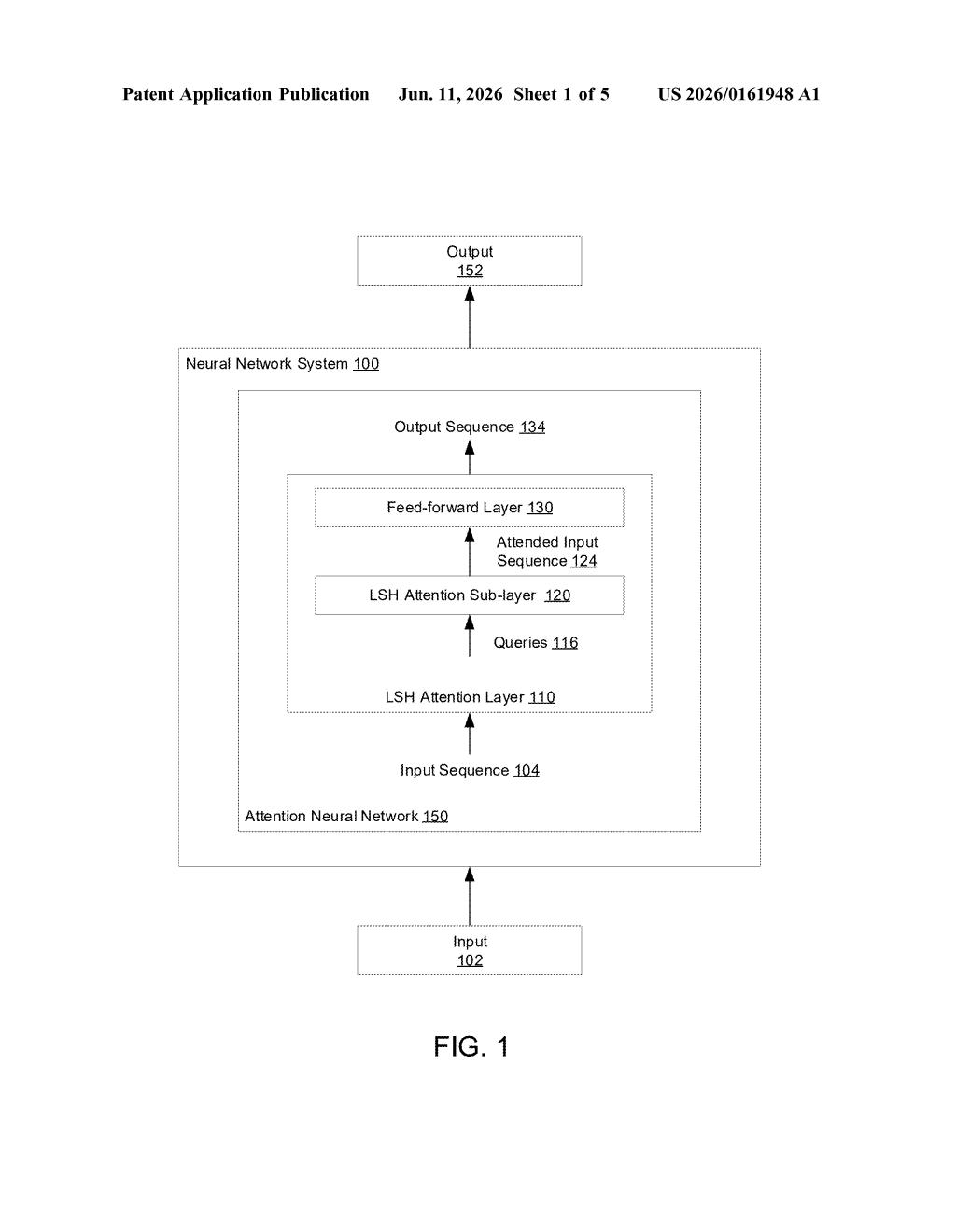
How Google's hashing trick shrinks AI memory costs
Imagine you're trying to find your closest friends in a city of a million people. The obvious approach — comparing yourself to every single person — works, but it takes forever. A smarter move: sort everyone into neighborhoods first, then only compare yourself to people nearby. That's roughly what this Google patent does for AI.
AI attention layers are the part of modern models that let the system figure out which words (or pixels, or tokens) are most relevant to each other. The problem is that comparing every piece of information against every other piece gets exponentially expensive as inputs get longer. Google's approach uses a technique called locality-sensitive hashing (LSH) to sort similar inputs into buckets first, so the model only pays attention within each bucket — not across the entire input.
The result is an attention system that can handle much longer inputs without the compute bill spiraling out of control. This is the kind of plumbing work that quietly makes larger, more capable AI models practical to actually build and deploy.
How LSH groups queries without comparing everything
Standard attention mechanisms (the core of transformer-based AI models) work by computing a relevance score between every query and every key in an input sequence. That's an O(n²) operation — double the input length, quadruple the cost. For long documents or high-resolution images, this becomes a serious bottleneck.
Google's patent replaces that exhaustive comparison with locality-sensitive hashing (LSH) — a technique where similar vectors are probabilistically mapped to the same hash bucket. Think of it like a sorting hat: inputs that are mathematically similar get assigned the same group, so the model only needs to run attention within those groups rather than across the full sequence.
The system works as follows:
- Each query in the input sequence receives one or more hash values computed by an LSH function
- Queries with matching hash values are grouped into LSH groupings (buckets of similar items)
- Attention is computed only within each bucket, drastically reducing the number of comparisons
- The results are reassembled into an attended input sequence — the same output format as a standard attention layer
The architecture uses multiple rounds of hashing to reduce the chance that truly similar queries end up in different buckets by accident. This is essentially the Reformer architecture, a well-known Google Research contribution first published in 2020.
What this means for running large AI models cheaply
The core bottleneck for scaling AI models is compute — specifically, the quadratic cost of standard attention. Any technique that makes attention cheaper without tanking accuracy is valuable infrastructure, because it directly determines how long an input a model can realistically process. Longer context windows mean models can read entire books, codebases, or legal documents in one pass rather than chunking them.
For you as an end user, this kind of patent is what sits behind features like "summarize this entire PDF" or "chat with your whole email history." It's not a product announcement — it's the engineering foundation that makes those products feasible. Google has been working on efficient attention for years, and this filing suggests they're continuing to formalize and protect that groundwork.
This is a patent on the Reformer, Google's 2020 efficient-attention paper, filed five years later. The core independent claim has been canceled, which is a notable flag — it suggests the patent office already pushed back on the broadest version of the claims. What's left may be narrower procedural protection around a well-known technique. Academically interesting architecture; legally, worth watching with skepticism.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.