Google Patents a Way to Double How Many AI Queries a Single Chip Can Handle
Google has patented a framework that promises to squeeze twice as many AI queries per chip out of retrieval-augmented generation systems — the same architecture powering AI-assisted search and enterprise knowledge tools.
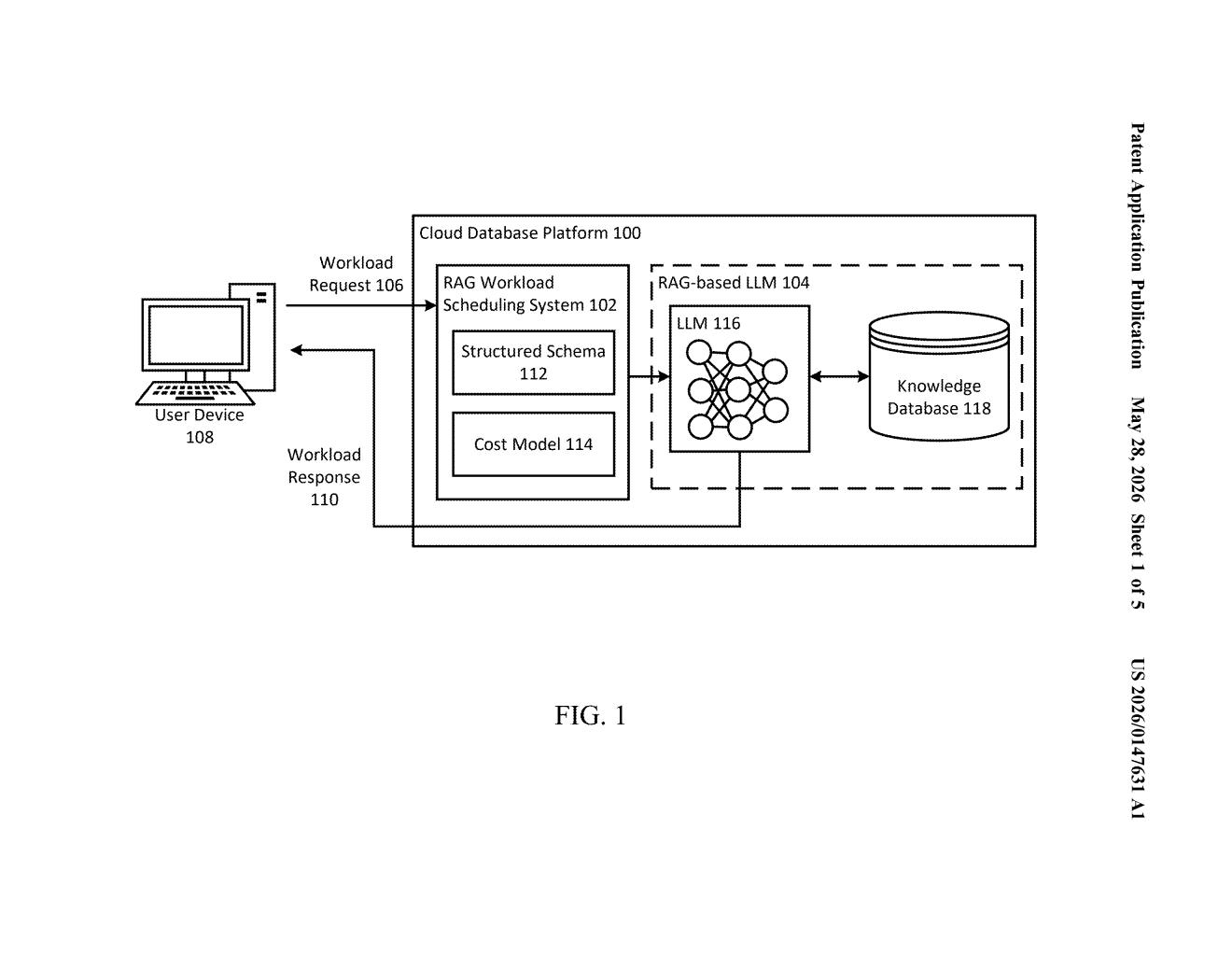
What Google's RAG speed-doubling system actually does
Imagine you're asking an AI assistant a question, and behind the scenes it has to rifle through a massive document library to find relevant facts before crafting an answer. That process — called retrieval-augmented generation, or RAG — is how most serious AI tools avoid making things up. But running it efficiently is surprisingly hard, because not every question needs the same resources.
Google's patent describes a system that looks at an incoming query, figures out exactly what kind of RAG setup it needs, and picks the most efficient configuration to answer it — all within whatever hardware budget is available. Instead of running every query through the same one-size-fits-all pipeline, this framework matches the job to the right tool.
The payoff, according to the filing, is up to a 2× improvement in how many queries a single chip can handle per second. That's a meaningful efficiency gain — it means you can serve twice as many users on the same hardware, or cut your compute costs roughly in half.
How Google's schema converts workloads into optimal RAG configs
The patent introduces two interlocking pieces: a structured schema for describing RAG configurations, and an optimization framework that uses that schema to pick the best setup for a given workload.
The schema is the key innovation. Today's RAG pipelines vary enormously — some retrieve a handful of document chunks, some retrieve thousands; some do re-ranking passes, some don't; some use dense vector search, others hybrid approaches. Google's schema creates a unified way to represent all of these variations as a configuration space (think of it like a structured menu of all possible RAG setups).
When a query arrives, the system:
- Converts the workload request into a point in that configuration space
- Reads the available resource constraints (e.g., how much memory, how many chips)
- Selects the RAG configuration that best balances quality and efficiency
- Runs inference and returns the response
The filing claims this approach outperforms RAG systems built as extensions on top of existing LLM serving infrastructure (the standard way most companies build RAG today) — because those systems weren't designed with RAG's unique retrieval-plus-generation workload pattern in mind. Google's framework treats RAG as a first-class workload, not an afterthought bolted onto a language model server.
What this means for the cost of running AI search at scale
For companies running RAG at scale — cloud providers, enterprise AI vendors, anyone paying GPU bills — a 2× throughput gain is not a small number. It means the same infrastructure handles twice the traffic, which translates directly into cost savings or headroom to serve more users without adding hardware.
More broadly, this patent signals that Google sees RAG efficiency as a distinct engineering problem worth solving at the infrastructure level, not just at the model level. As RAG becomes the default architecture for grounding LLMs in real data — search, customer support, document analysis — whoever owns the most efficient serving layer has a real competitive advantage. This filing suggests Google is building that layer deliberately.
This is solidly useful infrastructure work from Google's systems research side. A 2× QPS-per-chip claim is credible and meaningful — not marketing fluff — and the core insight (that RAG workloads need their own serving primitives, not LLM-serving extensions) is the kind of thing that takes years to ship but quietly defines who wins in cloud AI economics. Worth tracking.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.