Patent: AI Decides When to Pull Your Personal Data Before Answering
Most AI assistants treat every question the same way. Google is patenting a system that first asks: 'Does answering this question well require knowing something about this specific person?' — and then acts accordingly.
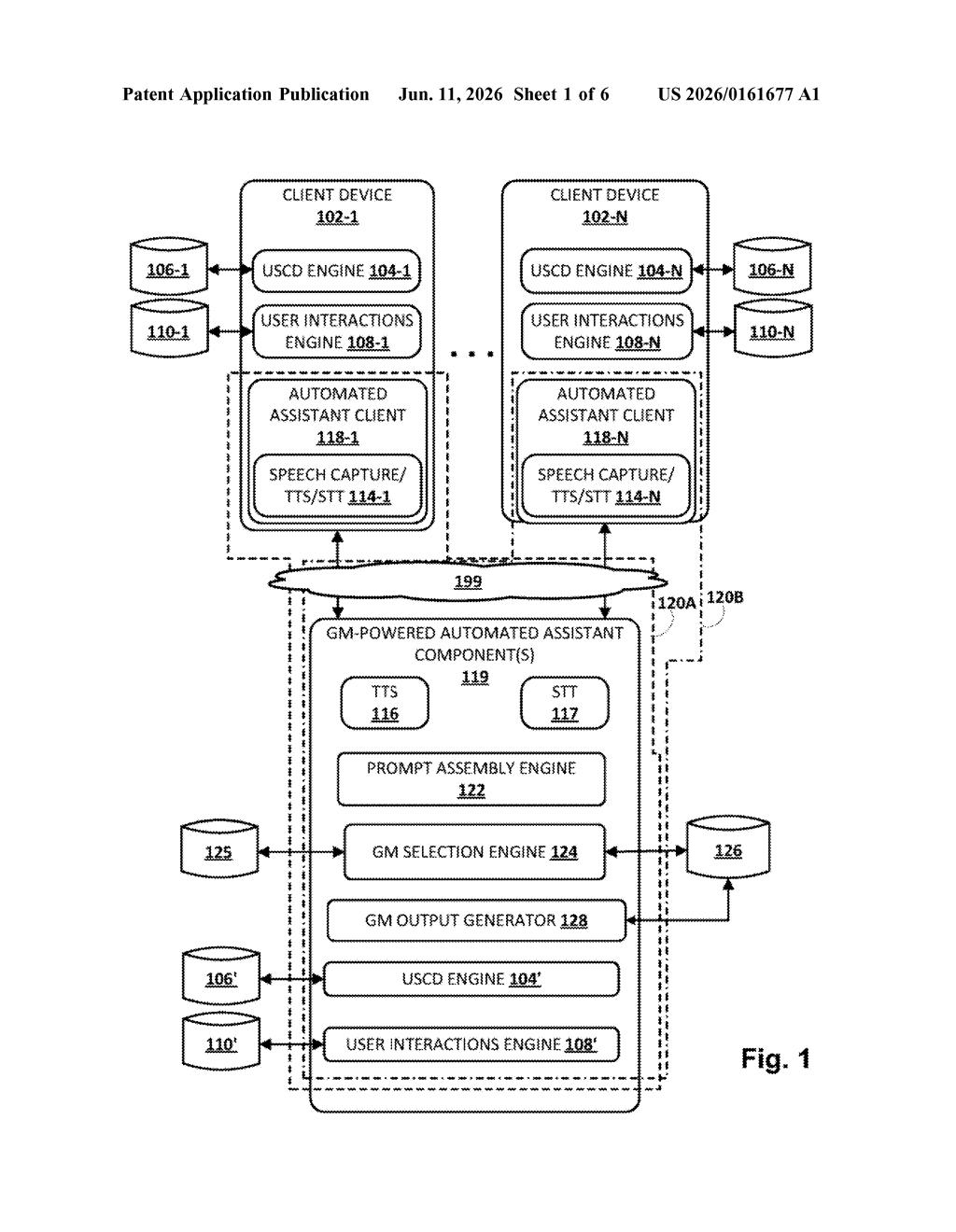
How Google's AI decides to use your personal data
Imagine asking your AI assistant something like, 'What should I have for dinner tonight?' A generic AI gives you a generic answer. But if the AI knows you're vegetarian, that you cooked pasta twice this week, and that you tend to prefer quick meals on Fridays — the answer gets a lot more useful. The catch is that pulling in all that personal context for every question wastes time and can actually make responses worse.
Google's patent describes a system that acts as a gatekeeper. Before the AI answers your question, it checks whether your personal history is actually relevant. If it is, the system pulls in either a compact summary of what it's learned about you over time, or the raw records of your past interactions — or both.
The key detail here is that Google isn't just storing your chat history and pasting it in wholesale. The system can build a condensed profile of you from that history, so the AI can be informed by your habits and preferences without needing to re-read every conversation you've ever had.
How the system builds and applies user-specific context
The patent describes a two-stage process. First, incoming queries are evaluated to decide whether Retrieval Augmented Generation (RAG) — a technique where an AI looks up relevant information before answering — is even necessary. Not every question benefits from personal context, and checking when to skip it keeps things fast and accurate.
When the system decides personal context is useful, it has two sources to draw from:
- Personal RAG data: raw records of a user's past interactions with devices — essentially the unprocessed history of what you've done, asked, or told the AI.
- User-specific conditioning data (USCD): a distilled profile built over time from that raw history — think of it like a compressed summary of your habits, preferences, and recurring needs.
The prompt sent to the generative model is then assembled with the original question plus whichever of these two data sources is appropriate. The model generates its answer conditioned on (meaning, shaped and informed by) that personal context.
The separation of raw history from a condensed profile is the technically interesting part. It means the system can choose the right level of detail — sometimes a full diary entry helps; sometimes a personality sketch is enough.
What this means for Google's Gemini and AI assistants
For users, this is the plumbing behind AI assistants that actually remember you without feeling creepy about it. A system that only reaches for your personal data when it's genuinely useful is less likely to feel intrusive — and more likely to give answers that feel relevant rather than lucky.
For Google specifically, this kind of selective personalization is central to making Gemini competitive as a daily-use assistant. The patent suggests Google is thinking carefully about the tradeoff between personalization and performance — building infrastructure that can scale personal AI without turning every interaction into a deep dive through someone's life history.
This is real, useful infrastructure work — the kind of unglamorous system design that separates an AI assistant you trust from one you forget about. The key idea, separating when to personalize from how much to personalize, is a genuinely sensible approach to a problem that most AI assistants currently handle clumsily. Worth watching as a signal of where Google's assistant strategy is heading.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.