Google Patents a Two-AI System Where One Model Edits the Other's Answers
What if an AI's first answer was just a draft — and a second AI quietly rewrote the rough parts before you ever saw them? That's exactly what this Google patent describes.
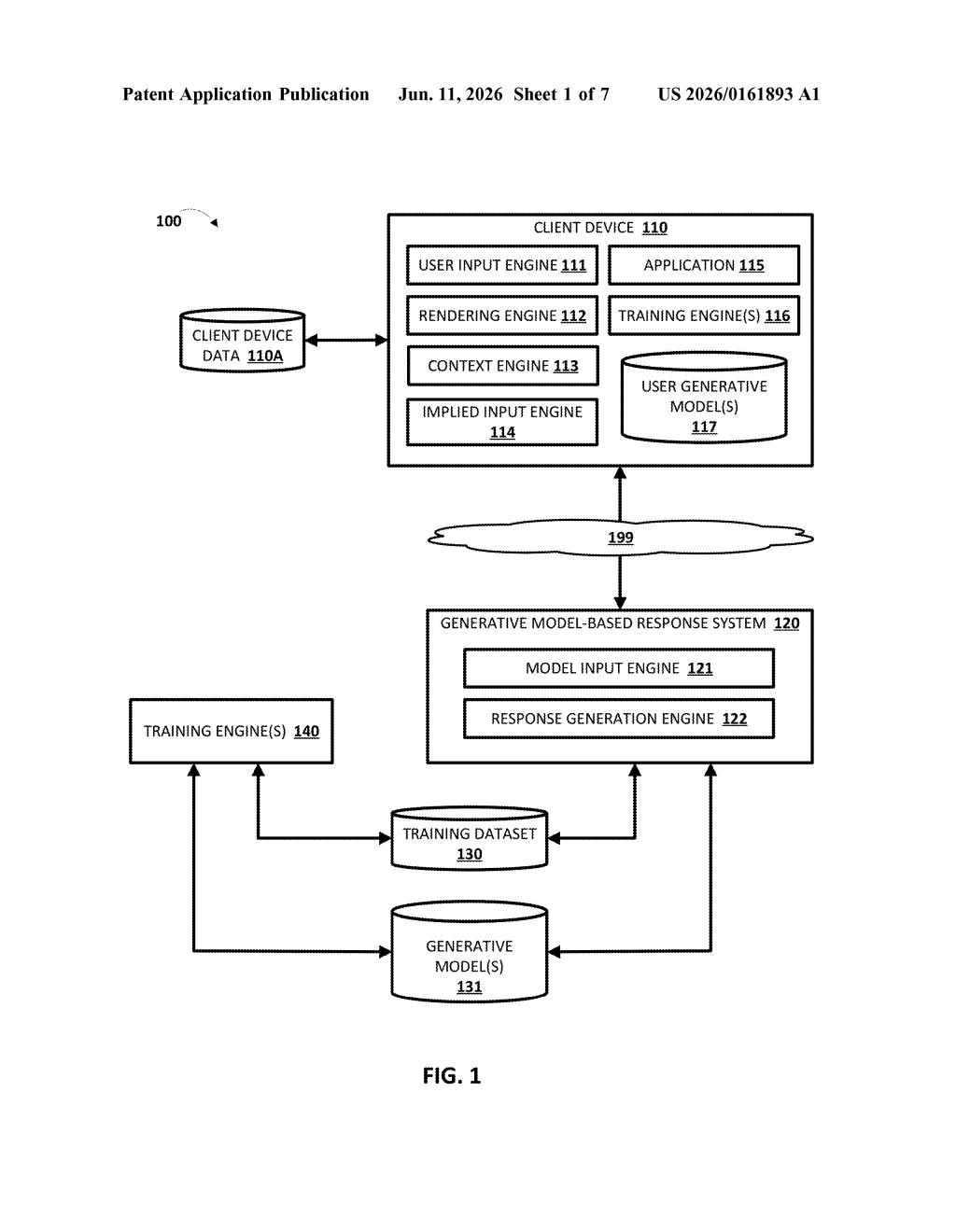
How Google's two-model editing loop actually works
Imagine asking a question and getting an answer that's almost right — but the AI itself notices something is off. Instead of just giving you that flawed response, it quietly hands the draft over to a second AI for review and correction before the final answer reaches you.
That's the core idea here. Google is patenting a setup where one AI generates an initial response — think of it as a rough draft — and if that draft contains a signal saying "this part needs fixing," a second AI steps in, figures out what should change, and sends that guidance back to the first AI to produce a polished final answer.
The two AIs can run on the same device or on different ones — for example, a lightweight model on your phone and a more powerful model on a remote server. The goal is an output that's more accurate and reliable than either AI could produce alone.
Inside the provisional-output revision cycle
The patent describes a two-stage generative model pipeline in which a first AI model produces what the patent calls a provisional output — essentially a first-pass answer to a given input.
Here's the sequence the patent lays out:
- The first AI model generates its initial response.
- The system checks whether that response contains an embedded instruction to adapt — a built-in flag that signals something in the output needs revision.
- If such a flag is present, the relevant portion is handed to a second generative model, which generates specific guidance on how to fix or improve it.
- That corrective guidance is fed back into the first model, which then produces the final, adapted output.
A key detail: the two models don't have to live on the same hardware. The patent explicitly covers configurations where the first model runs on a local device (like a phone) and the second model runs on a remote server — allowing a compact on-device model to call in a heavier cloud-based model when it detects it needs help.
The self-flagging mechanism is notable — rather than an external system deciding when to trigger the second model, the first model's own output contains the signal, making the correction process more tightly integrated.
What a self-correcting AI pipeline means for Google products
For everyday users, this matters because it targets one of the most frustrating things about AI assistants: confident-sounding answers that are subtly wrong. A pipeline where the AI itself can detect uncertainty and route to a second, potentially more capable model is a meaningful step toward fewer hallucinations and more reliable responses.
Strategically, this fits neatly into Google's existing AI infrastructure — Gemini Nano runs on Pixel devices while larger Gemini models run in the cloud. A patent that formally describes routing between on-device and cloud models suggests Google is building the plumbing to make that handoff automatic and context-aware, rather than leaving it to developers to wire up manually.
This is a genuinely interesting architectural idea — using the model's own output as the trigger for self-correction is cleaner than bolting on an external quality-checker. Whether it's novel enough to survive a patent challenge is a different question, but as a description of where agentic AI pipelines are heading, it's worth paying attention to.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.