Microsoft Patents an Automated File-Compaction System for Data Lakes
Every data lake slowly turns into a junk drawer — thousands of tiny files that drag query performance to a crawl. Microsoft's latest patent describes a system that watches for that chaos and cleans it up automatically.
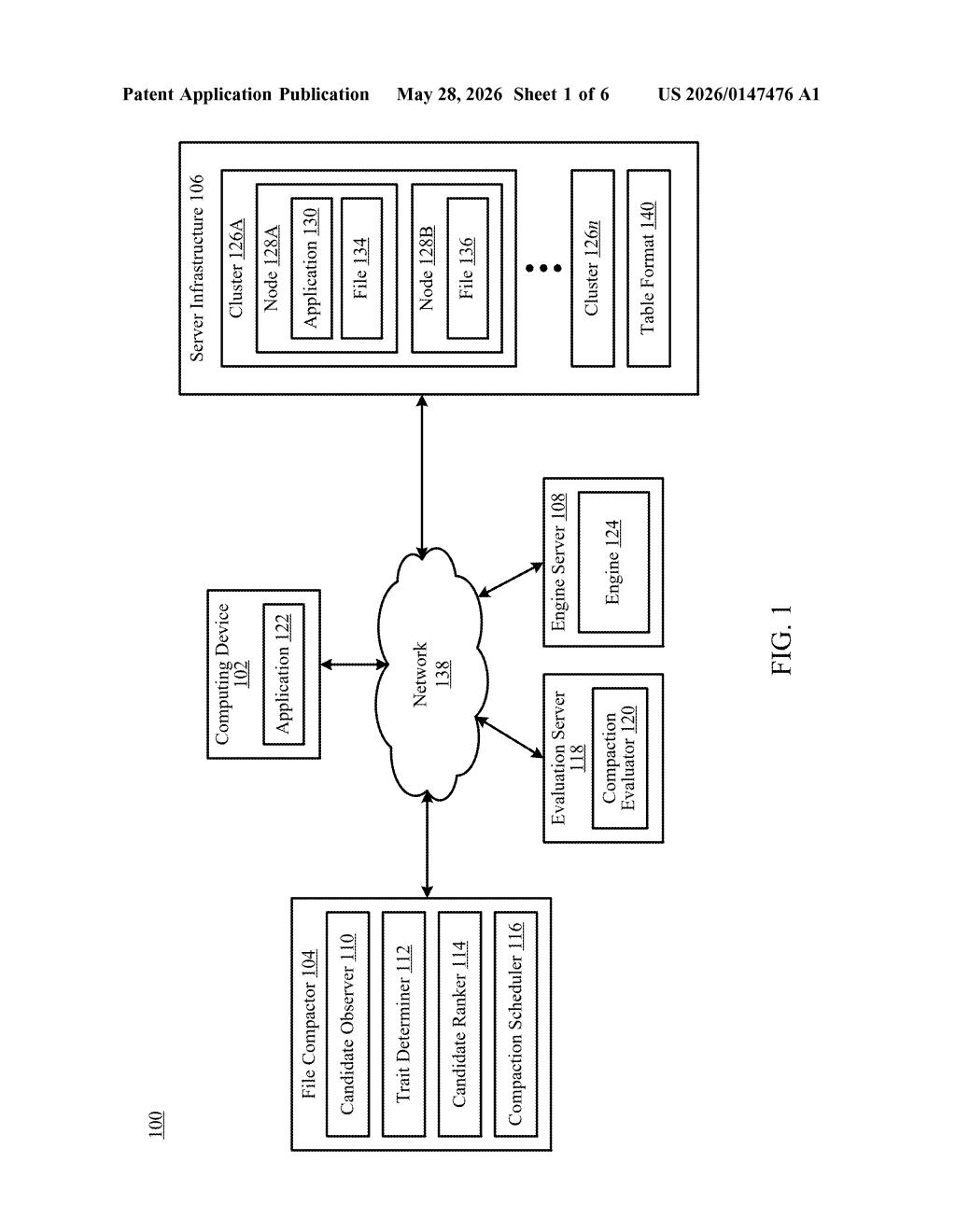
What Microsoft's data lake compaction system actually does
Imagine a filing cabinet where, over months, someone keeps stuffing in sticky notes instead of proper folders. Eventually, finding anything takes forever. That's roughly what happens to cloud data lakes — the storage systems that companies use to hold huge amounts of raw data. Queries slow to a crawl because the system has to sift through a massive pile of small, inefficient files.
Microsoft's patent describes a system that watches your data lake and automatically figures out which groups of files most need to be merged together (a process called compaction). It scores each candidate group using statistics, ranks them by how much compaction would help, and then kicks off the right kind of cleanup job — all without a human having to schedule or configure anything.
This kind of automated housekeeping is especially relevant for modern table formats like Apache Iceberg or Delta Lake, which are the organizational layers that sit on top of raw cloud storage and make it queryable. The patent is squarely aimed at making those systems self-maintaining.
How the ranking engine picks files to compact
The system works on top of a data lake — a large blob-storage repository (think Azure Data Lake Storage) where files are managed by a table format such as Apache Iceberg, Delta Lake, or Apache Hudi. These formats track which files belong to which table, but they don't automatically clean up fragmentation.
The patent describes a pipeline with a few key steps:
- Candidate identification: The system groups files into candidates — subsets of files that could potentially be merged together. Think of a candidate as a bin of related files that belong to the same table partition or time window.
- Statistic computation: For each candidate, the system computes one or more statistics — things like total file count, average file size, or data skew — to characterize how fragmented or inefficient that candidate is.
- Ranking against a compaction objective: Candidates are ranked relative to a compaction objective (a declared goal, such as 'reduce file count' or 'improve read latency'). The trait derived from the statistics determines where each candidate lands in the priority queue.
- Action selection and execution: The top-ranked candidate gets a compaction action chosen based on the objective, the table format in use, and the specific file profile — then that action is executed.
The system is format-aware, meaning it can pick the appropriate merge strategy for whichever table format is managing a given dataset.
What this means for Azure's data warehouse performance
Data lake compaction is one of those unglamorous but high-impact maintenance tasks that data engineering teams currently handle manually — writing cron jobs, tuning thresholds, or paying for managed services that do it opaquely. A ranking-driven, objective-aware compaction engine built into the platform means less operational toil and more predictable query performance for teams running analytics on Azure Synapse or Microsoft Fabric.
For you as a data engineer or platform buyer, the practical upside is that tables stay in good shape without babysitting. The deeper strategic angle is that Microsoft is trying to make its lakehouse infrastructure self-tuning — a capability that competing platforms like Databricks and Snowflake have been pushing hard on, so this is a competitive catch-up play as much as a technical one.
This is unglamorous plumbing work, but it's exactly the kind of thing that separates a mature cloud data platform from an early-adopter one. The ranking-and-objective abstraction is a legitimately useful design — it lets the system prioritize compaction intelligently rather than just firing off jobs on a schedule. If this lands in Microsoft Fabric or Synapse, it'll quietly make a real difference for teams managing large Iceberg or Delta Lake tables.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.