Microsoft Patents a Neural Network That Predicts Action Sequences from Entity Relationships
Microsoft has patented a way to train attention-based neural networks that treat 'who you interact with' and 'what those interactions say about you' as two separate — but jointly learned — inputs. The goal: predict what a user or entity will do next.
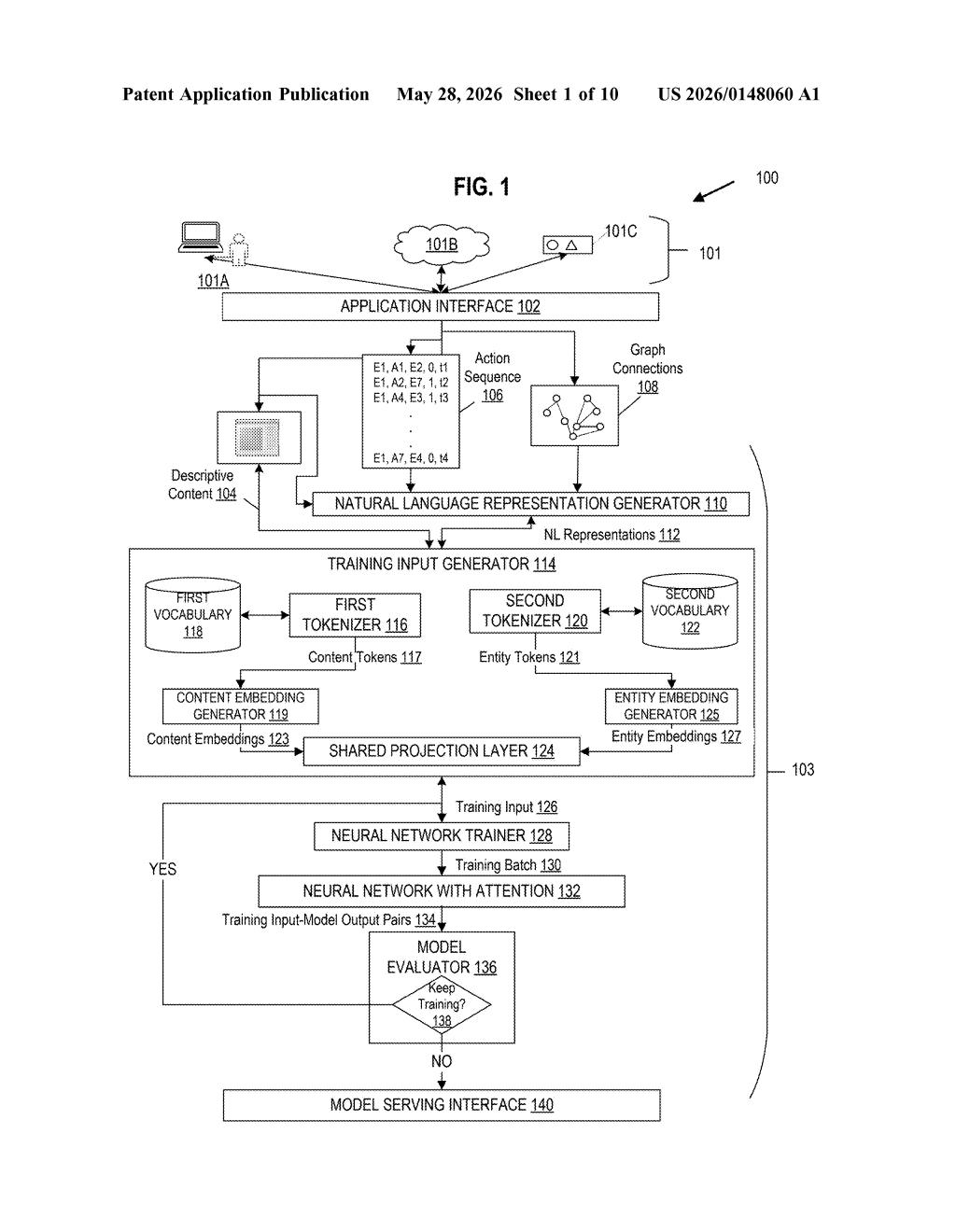
What Microsoft's entity-relationship sequence model actually does
Imagine LinkedIn watching which job postings you click, which recruiters message you, and which companies you follow — and then trying to predict what you'll do next, like applying to a specific role or accepting a connection. That's roughly the problem this patent is designed to solve.
Microsoft's approach feeds two kinds of information into a neural network at the same time: a sequence of actions (what an entity — say, a user or an advertiser — has actually done) and descriptive content about that entity (like a profile, a bio, or product metadata). By combining behavioral history with descriptive context, the model gets a richer picture than either source alone would provide.
The clever part is that Microsoft uses a non-standardized tokenizer — essentially a custom vocabulary tuned to the specific domain — rather than a one-size-fits-all text tokenizer. That means the model can treat entity IDs and behavioral signals as first-class inputs, not afterthoughts bolted onto a generic language model.
How the dual-tokenizer and shared projection layer work together
At its core, this patent describes a training pipeline for a sequence-to-sequence attention model (think: the same architectural family as Transformers) that takes in two channels of data simultaneously.
The first channel is action data: a structured sequence of electronic transmissions or interactions tied to a specific entity ID — basically a log of what entity A did with entity B, then entity C, and so on. The second channel is descriptive content: natural language or metadata that characterizes what entity A actually is.
These two inputs are processed through separate tokenizers and embedding generators before being combined via a shared projection layer (a mathematical operation that maps both representations into the same vector space so they can be compared and combined). The diagram in the patent shows a pipeline that includes:
- A first tokenizer for content tokens (natural language descriptions)
- A second tokenizer for entity tokens (IDs and behavioral signals)
- A shared projection layer that unifies both embedding spaces
- A neural network trainer that uses graph connections between entities as additional context
The trained model then outputs a predicted second sequence of actions — in other words, it guesses what the entity will do next. The use of a non-standardized (domain-specific) tokenizer is a key claim, suggesting Microsoft wants flexibility to define its own vocabulary for entity-level signals rather than relying on general-purpose NLP tokenizers.
What this means for LinkedIn recommendations and ad targeting
This patent sits squarely in the recommendation and behavioral prediction space — territory that's critically important to Microsoft's LinkedIn and advertising businesses. A model that jointly learns from what users do and what their profiles say about them could power more accurate job recommendations, content feeds, or ad targeting than systems that treat behavioral logs and profile data as separate problems.
The explicit inclusion of graph connections between entities in the training input also hints at social or professional network graph exploitation — predicting behavior based on who you're connected to, not just what you've done yourself. If this architecture ships in LinkedIn's recommendation stack or Microsoft Advertising's bidding models, the downstream effect for you as a user is a feed that's harder to game and more eerily accurate about what you'll engage with next.
This is a solid, well-scoped ML systems patent — not flashy, but clearly aimed at a real production problem Microsoft faces at scale across LinkedIn and its ad platforms. The dual-tokenizer architecture with a shared projection layer is a thoughtful engineering choice, and the explicit graph-connection input signals this isn't just a generic Transformer fine-tuning job. Worth watching if you follow LinkedIn's AI roadmap.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.