Microsoft Patents a Second AI That Arranges Your LLM Prompts for Better Code Responses
It turns out that where you put information inside an AI prompt matters almost as much as what you put there — and Microsoft wants a dedicated AI model to figure out the ideal arrangement automatically.
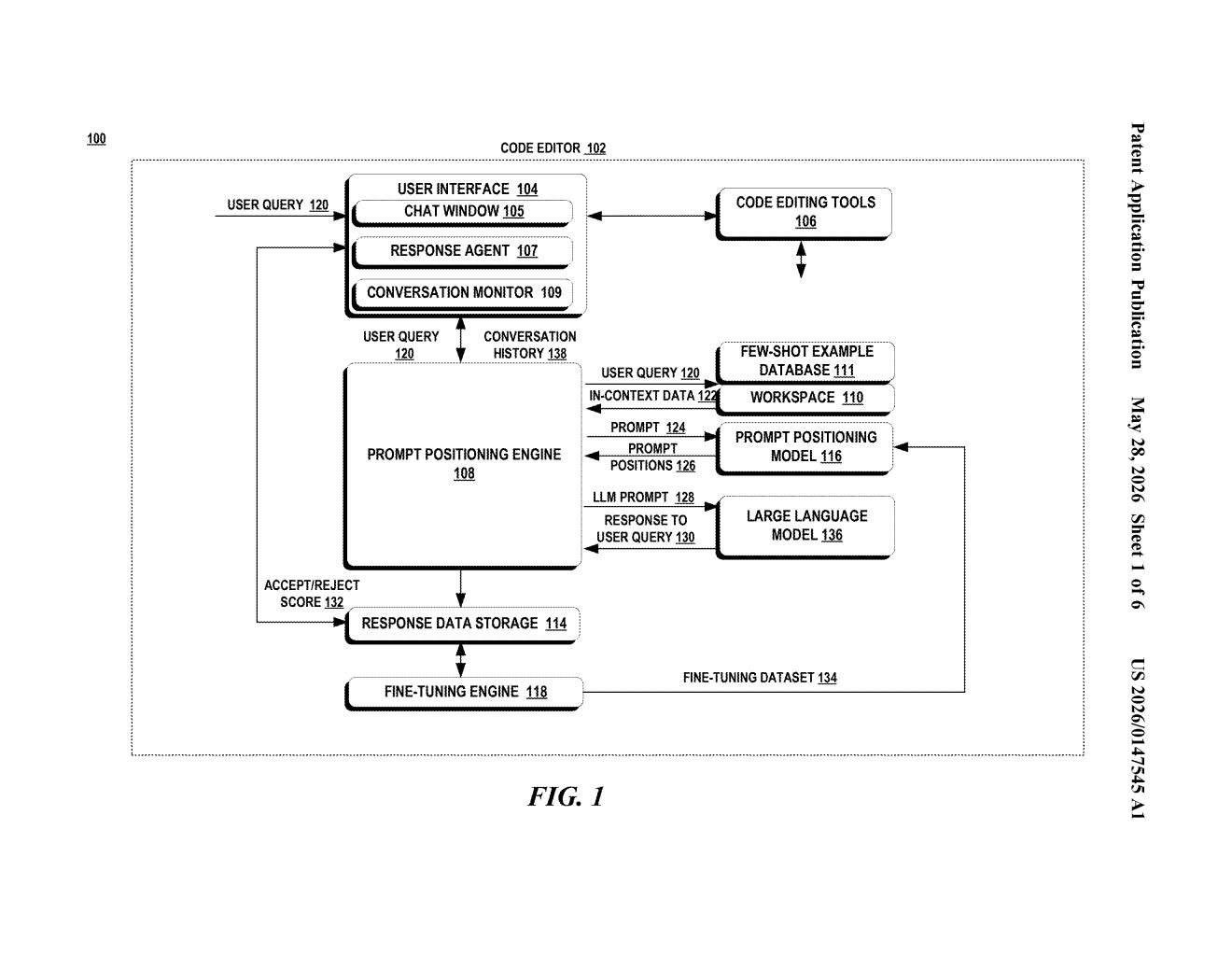
What Microsoft's prompt-positioning AI actually does
Imagine giving a colleague a stack of reference documents before asking them a question. If the most relevant document is buried at the bottom, they might miss it. Large language models like the ones powering AI coding tools have a similar quirk: they don't treat every piece of context in a prompt equally, and the order of that context can shift the quality of the answer you get.
Microsoft's patent tackles this with a clever two-model approach. Instead of dumping all your relevant code files, examples, and history into a prompt in whatever order they show up, a dedicated "positioning" model first decides the best arrangement. It's been trained on real user behavior — specifically, whether developers accepted or rejected the AI's suggestions — so it learns which ordering tends to produce useful outputs.
The result is that your AI coding assistant builds a more carefully organized prompt before ever asking the main LLM your question. You don't see any of this happening; it just silently improves the odds that the AI gives you a helpful answer on the first try.
How the positioning model learns LLM access patterns
The patent describes a prompt positioning engine that sits between you and the main large language model in a code development session. When you ask a coding question, the system pulls in a bundle of relevant in-context data — things like few-shot examples (sample code snippets that demonstrate a pattern), your conversation history, and files from your workspace.
Rather than feeding all of that into the LLM in arbitrary order, a separate, smaller positioning language model receives the same query and context bundle and outputs an ordered sequence — essentially a ranked list of where each piece of data should appear in the final prompt. The positioning model has been trained to mimic the access pattern of the primary LLM (meaning: which parts of a prompt the LLM tends to actually "pay attention to" when generating a response).
The training signal for the positioning model comes from user accept/reject feedback. When a developer accepts a code suggestion, the ordering used to generate that suggestion gets a positive signal; rejections get a negative one. That data flows into a fine-tuning dataset that continuously sharpens the positioning model's understanding of what orderings lead to useful outputs.
- User query — the developer's natural-language or code request
- In-context data — examples, history, and workspace files gathered automatically
- Positioning model — small LLM that outputs an optimized ordering
- Primary LLM — the main model that generates the actual code response
What this means for AI coding assistants like Copilot
The "lost in the middle" problem — where LLMs reliably ignore context placed in the middle of a long prompt — is a well-documented limitation of current transformer architectures. Most workarounds involve retrieval tricks or simply truncating context. Microsoft's approach is different: rather than changing the LLM itself, it trains a lightweight wrapper model to learn each LLM's specific attention quirks and compensate for them automatically.
For products like GitHub Copilot, where the quality of a code suggestion lives or dies by what context the model actually processes, this kind of invisible prompt optimization could meaningfully improve suggestion acceptance rates without requiring any changes to the underlying model. For you as a developer, that means fewer irrelevant suggestions and less time manually rewriting prompts to get the AI to focus on the right file.
This is a genuinely thoughtful piece of LLM plumbing. The insight that you can train a cheap secondary model to learn another model's attention habits — using nothing more than accept/reject click data — is elegant and practically deployable without touching the primary LLM at all. It's the kind of low-drama infrastructure improvement that quietly makes AI coding tools noticeably better.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.