Microsoft Patents a Real-Time Meeting Summarizer That Switches AI Attention Modes on the Fly
Most AI meeting summaries arrive after the call ends. Microsoft is patenting a system that builds the summary while people are still talking — by cleverly toggling between two different ways of reading the conversation.
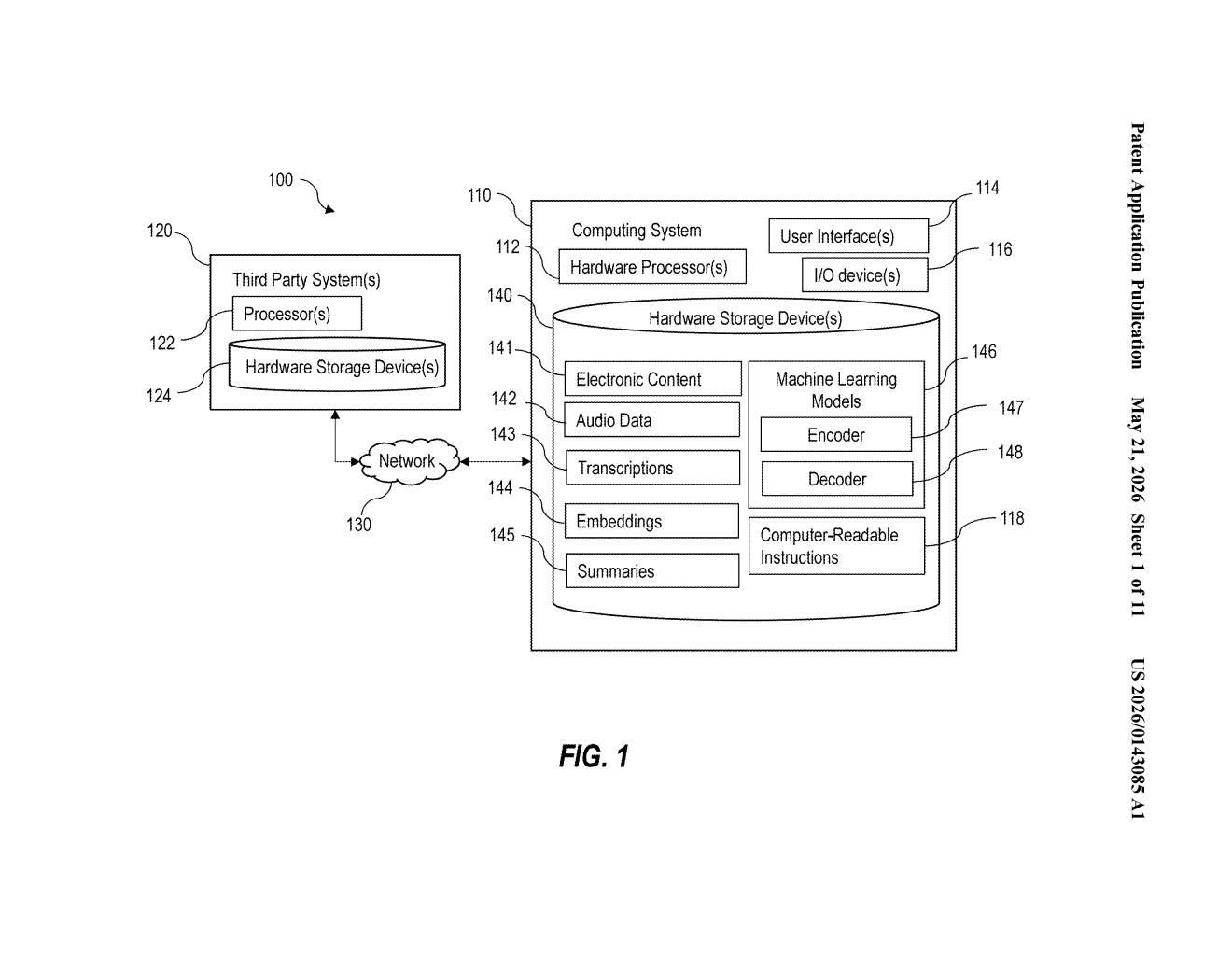
What Microsoft's live meeting summarizer actually does
Imagine you're 20 minutes into a one-hour Teams call and you want a quick recap of what's been decided so far. Today, most AI tools make you wait until the meeting is over before handing you a summary. Microsoft's new patent describes a system that generates that summary in real time, as the words are still being spoken.
The trick is how it processes the audio. Two different reading modes — one that only looks backward at what's been said, and one that looks both backward and forward — take turns handling the incoming speech. The backward-only mode is fast and works well for live, incomplete sentences. The two-way mode is more thorough but needs a chunk of context to work well, so it kicks in less often.
The result is a rolling summary that stays current without lagging behind the conversation. You could theoretically check in mid-meeting and get a coherent, up-to-date digest of everything discussed so far.
How the attention-switching encoder processes live speech
The patent describes an encoder-decoder architecture applied to a live audio stream. Speech is first converted to text (via automatic speech recognition), then fed into a transformer-style encoder — the kind of neural network layer that's at the heart of most modern language models.
The core innovation is the alternating attention mechanism:
- Unidirectional (causal) attention — the model only looks at tokens that came before the current word. This is how GPT-style models work and is well-suited to streaming because you don't need future context to process the present moment.
- Bidirectional attention — the model looks both backward and forward across a window of text, like BERT does. This produces richer representations but requires a complete chunk of text, so it can't run on every token in a live stream.
The patent specifies that these two modes run at different frequencies — unidirectional attention applies more often (essentially token-by-token), while bidirectional attention applies less frequently, periodically re-processing buffered content to refine the summary.
A decoder then takes the encoded representations and generates the actual summary text. The system is designed to keep the summary continuously updated rather than waiting for a defined endpoint like a sentence boundary or meeting end.
What this means for Teams and real-time AI notes
If this lands in Microsoft Teams or Copilot, it closes one of the more annoying gaps in AI meeting tools: the fact that you can't get a useful AI-generated recap mid-meeting. Real-time summaries would be useful not just for latecomers catching up, but for anyone who needs a quick "where are we?" check before making a decision in the room.
The attention-switching design also matters technically. It's a pragmatic middle ground between the latency of pure causal models and the accuracy of full bidirectional models — essentially admitting that live summarization is a different problem than post-hoc summarization, and solving it differently. That architectural honesty is worth noting.
This is a real engineering problem with a thoughtful solution. The hybrid attention approach isn't a marketing gimmick — it reflects a genuine trade-off that anyone who's tried to apply BERT-style models to streaming data has run into. Whether it ships as a polished Teams feature or stays buried in Copilot infrastructure, it's the kind of unglamorous plumbing that actually makes AI assistants more useful day-to-day.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.