IBM Patents a Shared-Layer System for Running Multiple Fine-Tuned AI Models at Once
Running dozens of fine-tuned AI models simultaneously is expensive — each one wants its own copy of the same giant base model loaded into memory. IBM's new patent describes a way to share that base model across all of them at once.
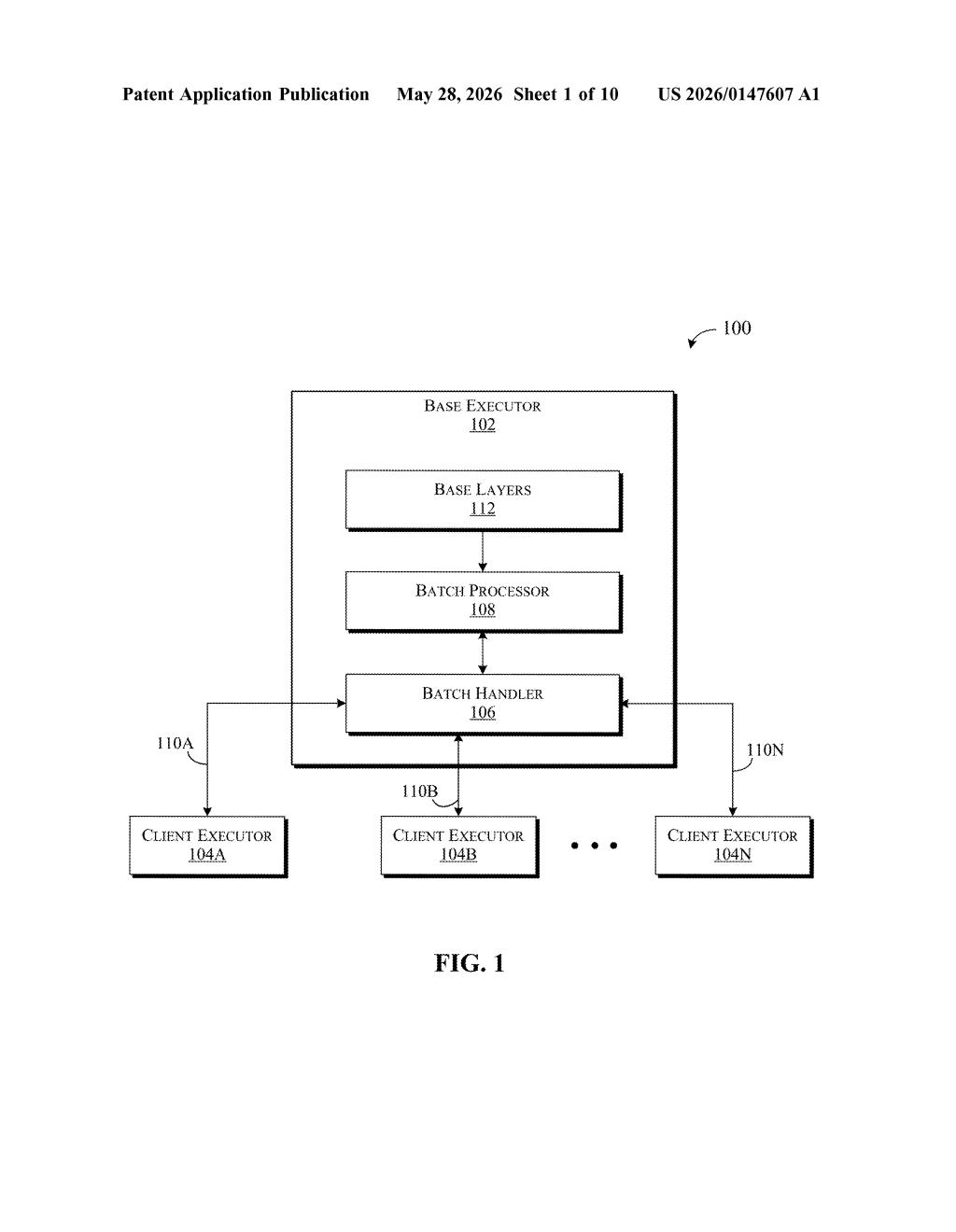
How IBM splits one base model across many AI tasks
Imagine a large company running fifty different AI assistants — one for HR, one for legal, one for each product line — all of which were built by fine-tuning the same underlying language model. Right now, every single one of those models typically needs its own copy of that base model sitting in GPU memory. That's wasteful and expensive.
IBM's patent describes a different setup. A single base executor loads the shared model layers once and handles requests from all the specialized "client" models simultaneously. Each client model sends its data to whichever layer it needs processed, the base executor batches those requests together for efficiency, and then sends the outputs back.
The result is that you get the benefits of many fine-tuned models without paying the memory and compute cost of duplicating the shared parts over and over. It's a bit like a shared kitchen where multiple restaurants send their ingredients to the same prep cook, each getting back exactly what they need.
How the base executor batches and routes layer outputs
The system introduces a two-tier architecture: a base executor that owns and runs the shared layers of a foundation model, and one or more client executors that handle task-specific logic — think the fine-tuned adapter layers or heads that make each model unique.
When a client executor needs to process some input data through a particular layer of the base model, it sends a request that specifies the input and which layer it wants. The base executor collects requests from all connected client executors, groups them into a request batch (a standard GPU efficiency trick — processing many inputs in parallel is much faster than one at a time), runs them through the requested layer, and ships each output back to the correct client.
- Base executor: hosts shared model layers, handles batching and compute
- Batch processor / handler: the internal components that queue and dispatch requests
- Client executors (L10A, L10B ... L10N): each runs task-specific logic and offloads heavy lifting to the base
The key insight is that the "selected layer" in each request can differ — one client might want output from layer 12, another from layer 24 — making this flexible enough for heterogeneous fine-tuning approaches like LoRA adapters or prefix tuning, not just identical model copies.
What this means for AI inference costs at enterprise scale
Enterprise AI deployments often run many fine-tuned variants of the same base model — customer service, code generation, document summarization — and GPU memory is the bottleneck. By centralizing the shared layers in one executor, IBM's approach could dramatically reduce the hardware footprint needed to serve all those models simultaneously. For a company running on-premises infrastructure or paying per GPU-hour in the cloud, that's a real cost argument.
This also fits squarely into the current industry conversation around model serving efficiency. Techniques like vLLM's PagedAttention and parameter-efficient fine-tuning (PEFT) are all trying to solve variants of the same problem. IBM is staking out a specific architectural claim here — one where the base model is a shared service, not a replicated artifact.
This is solid, practical infrastructure engineering aimed squarely at IBM's enterprise customer base — companies that want to run many fine-tuned models without buying a rack of GPUs for each one. It won't make headlines at NeurIPS, but it's exactly the kind of unglamorous systems work that determines whether AI deployments are economically viable at scale. Worth watching as a signal that IBM is building serious serving infrastructure around its WatsonX platform.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.