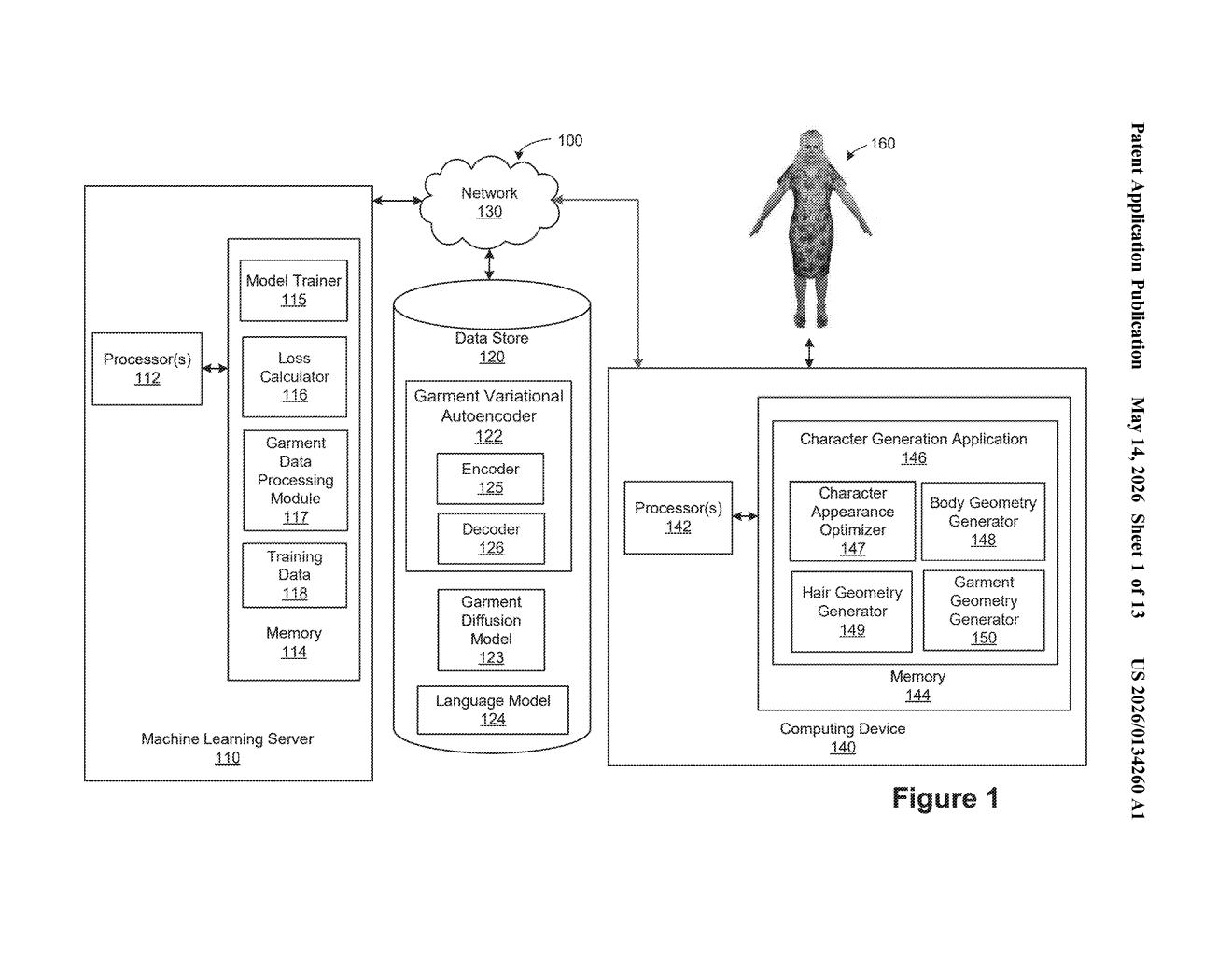
Nvidia Patents a Text-to-3D Pipeline for Simulation-Ready Virtual Characters
Nvidia is building a pipeline that takes a plain-text description — say, 'a flowing medieval tunic' — and spits out a fully simulation-ready 3D object. The interesting part isn't just the generation; it's that the output is designed to work inside physics simulators, not just look good in a render.
How Nvidia turns text prompts into 3D virtual garments
Imagine you're building a video game and you need a character wearing a specific jacket. Right now, that jacket requires a 3D artist to model it by hand, then a technical artist to rig it so it moves realistically. Nvidia's patent describes a system that could let you type a description and get a simulation-ready garment back automatically.
The system trains two AI models together. The first learns what 3D surfaces look like in general — shapes, geometry, structure. The second model, a diffusion model (the same family of AI behind image generators like Stable Diffusion), learns to connect your text description to the right geometric shape. When you type your prompt, these two models collaborate to produce the output.
The key word is simulation-ready. This isn't just generating a pretty picture of a garment — it's generating geometry that a physics engine can actually simulate, with fabric that folds, drapes, and collides realistically. That's a much harder technical bar to clear.
How the VAE and diffusion model work together
The patent describes a two-stage training pipeline. First, Nvidia trains a Variational Autoencoder (VAE) — a type of neural network that compresses complex data into a compact internal representation, then reconstructs it — on 3D object geometry data alone. This gives the system a trained encoder (which turns 3D shapes into compact embeddings) and a trained decoder (which turns those embeddings back into surface geometry).
Second, Nvidia trains a diffusion model using both the 3D geometry data and natural language data. A diffusion model works by learning to gradually 'denoise' random noise into structured output — it's the core technology behind text-to-image tools. Here, instead of generating pixels, the diffusion model is trained to generate a geometry embedding (a compact numerical description of a 3D shape) that matches a text prompt.
At inference time — when you actually want to generate something — the diffusion model takes your text input and produces a geometry embedding, then the VAE's decoder converts that embedding into a full object surface representation: actual 3D geometry usable in a simulator.
- Stage 1: VAE trained on 3D object data → learns shape compression and reconstruction
- Stage 2: Diffusion model trained on 3D + text data → learns text-to-geometry mapping
- Inference: Text prompt → diffusion model → geometry embedding → decoder → simulation-ready 3D object
What this means for game dev and AI simulation pipelines
Nvidia's core business increasingly depends on simulation — from autonomous vehicle training in DRIVE Sim to robotics training in Isaac to the broader Omniverse platform. Manually creating high-quality 3D assets for those simulations is expensive and slow. A text-to-simulation-geometry pipeline could dramatically reduce that bottleneck, letting developers and researchers populate virtual worlds with physics-accurate objects at scale.
For game developers and film studios, the implication is similar: your pipeline could eventually go from a designer's verbal description directly to a working in-engine asset, skipping several manual steps. The emphasis on simulation-readiness — not just visual fidelity — is what separates this from existing text-to-3D tools, which typically produce meshes that look fine but behave badly under physics.
This is a genuinely strategic patent for Nvidia, not a routine filing. It directly addresses the content creation bottleneck inside Nvidia's own simulation platforms, and the technical approach — decoupling geometry learning from language alignment through a two-stage VAE + diffusion architecture — is the right way to tackle this problem. If this makes it into Omniverse or Isaac, it could meaningfully accelerate synthetic data generation for robotics training.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.