Nvidia Patents a Multi-Layer Video Captioning System That Can Move Robots
What if a robot could watch a video and then physically act on what it saw? Nvidia has filed a patent that chains multiple AI captioning models together — and then feeds that combined understanding directly to a device to make it move.
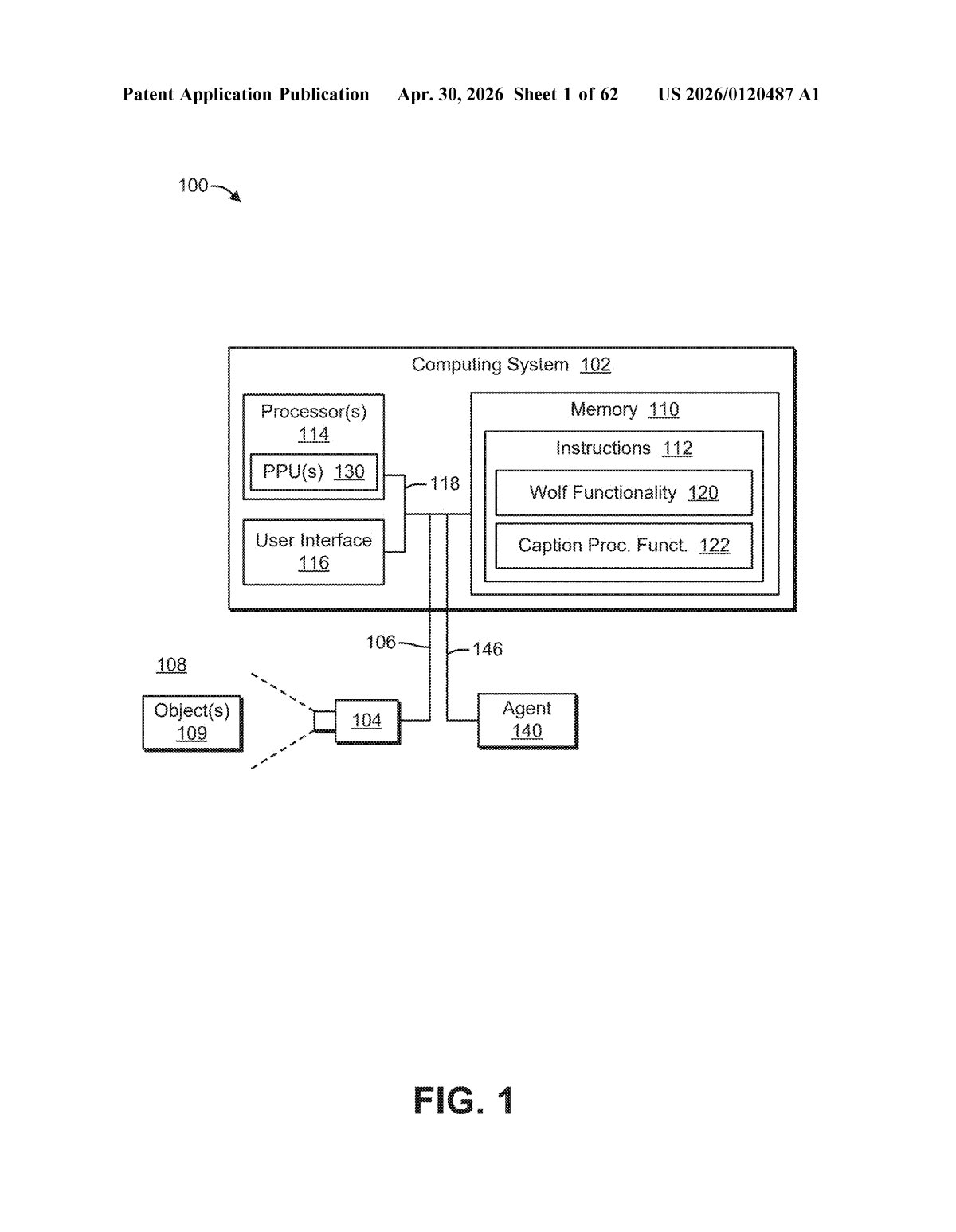
How Nvidia turns video into robot instructions
Imagine you hand a robot a short clip of someone opening a cabinet door. The robot needs to understand not just what's in the frame, but the motion, the sequence, and the meaning — before it can replicate the task. That's a hard problem, and a single AI model usually doesn't nail all three.
Nvidia's patent describes a system that attacks this with layers. One AI watches the video as a whole and writes a caption about it. A second AI pulls out individual frames and captions those. A third AI reads both captions and synthesizes a final, richer description — called an output caption — that captures both the still details and the motion.
The twist: that final caption isn't just for humans to read. The system uses it to physically move a device — a robot arm, a vehicle, or any actuated machine — from one position to another. It's a pipeline where language becomes action.
How three neural networks collaborate to caption a video
The patent describes a three-stage neural network pipeline for generating video captions, with the end goal of issuing motion commands to a physical device.
- First neural network (video-level captioning): Takes the entire video as input and generates a caption describing what's happening across the whole clip — motion, events, and temporal context (i.e., how things change over time).
- Second neural network (image-level captioning): Samples individual frames from the video and generates captions for each. This captures fine-grained visual detail — object identities, spatial relationships — that a video-level model might blur over.
- Third neural network (synthesis / summarization): Ingests both sets of captions and infers a single output caption that merges the temporal and spatial understanding. The patent notes this step can use a large language model (LLM) for summarization.
Critically, the claim explicitly ties this caption pipeline to actuation: the system causes "at least a portion of a device to move from a first position to a second position" based on the output caption. That bridges the gap between video understanding and physical control — a key requirement in robotics and autonomous driving. The patent also references motion captions as an optional additional input, suggesting the system could incorporate dedicated optical-flow or pose-estimation models to further enrich the description.
What this means for Nvidia's robotics and autonomous vehicle ambitions
Nvidia is not a robotics company in the traditional sense — but it's clearly trying to become the AI backbone of one. Systems like Isaac and DRIVE depend on machines understanding visual scenes and converting that understanding into physical actions. A captioning layer that fuses frame-level detail with video-level narrative gives downstream motion planners richer, more reliable context to work with.
For you as a user or developer, the practical upshot is robots that are better at learning from demonstration videos — watch a human do a task once, and the system generates an actionable description it can execute. That's a meaningful step toward robots you could actually train by showing, not programming.
This patent is doing something genuinely interesting: it treats language as the interface between perception and action, rather than trying to route raw video pixels directly into a motion controller. The three-network fusion architecture is smart engineering, not a gimmick. Whether it ships in Isaac Lab or DRIVE first, this approach reflects Nvidia's broader bet that LLMs aren't just chatbots — they're the control plane for physical machines.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.