Nvidia's New Patent Builds an AI That Won't Stop Looking Until It Sees the Full Picture
Most vision AI systems look at a scene once and move on. Nvidia's new patent describes an agent that keeps interrogating its own understanding — looping through queries until it's sure it hasn't missed anything.
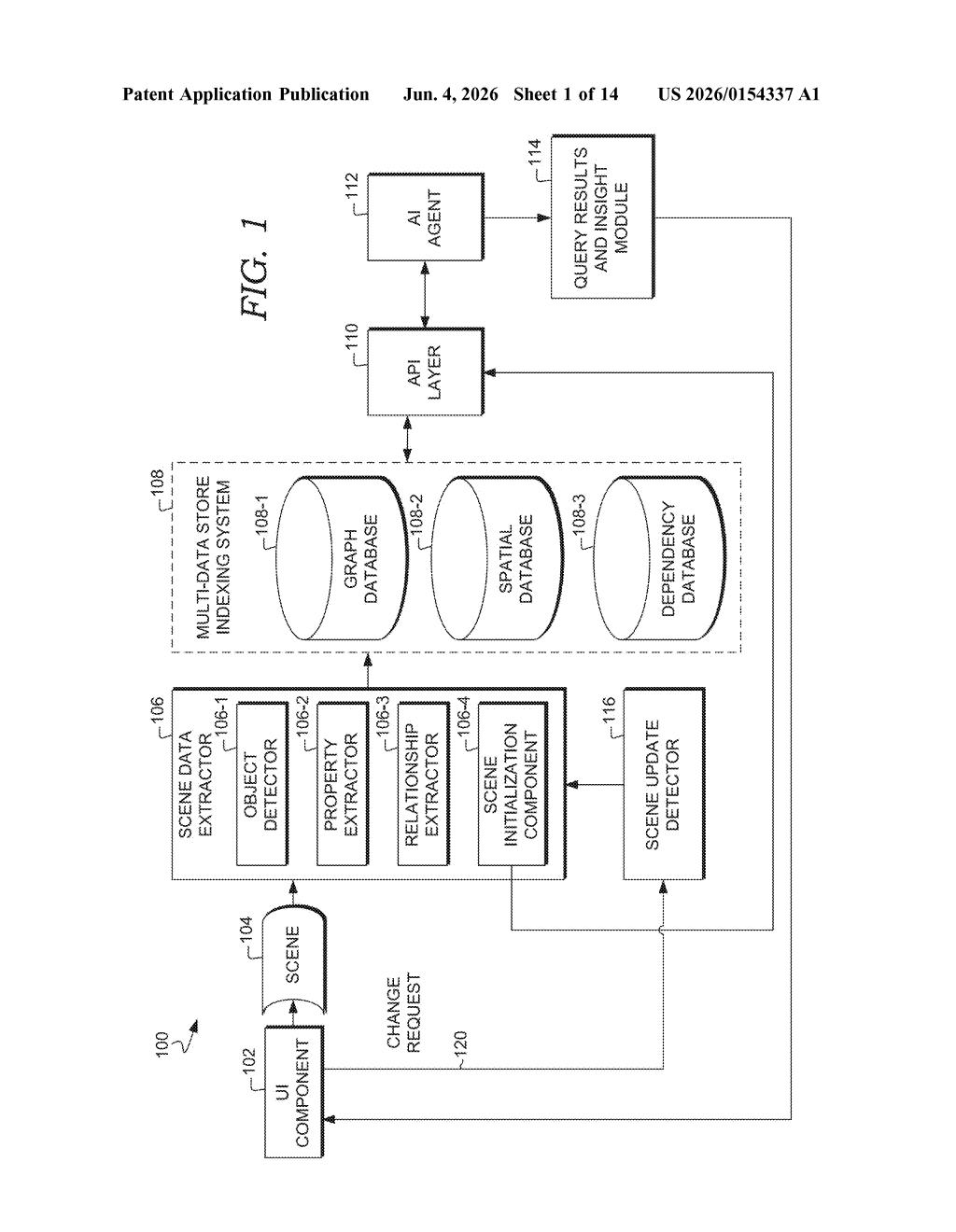
What Nvidia's self-querying scene AI actually does
Imagine you're trying to describe a busy intersection to someone who can't see it. You might start with the obvious stuff — cars, pedestrians, traffic lights — but then realize you forgot to mention the cyclist squeezing between lanes, or the construction barrier half-blocking the left turn. Good scene understanding takes more than one pass.
Nvidia's patent describes an AI agent designed to work the same way your brain does: look, notice a gap, ask a follow-up question, then keep going until it reaches a threshold of completeness. Instead of snapping a one-shot description of what it sees, the agent indexes all the scene data into something queryable, generates an initial query to extract key details, then automatically fires off follow-up queries based on what it just learned.
The loop continues until the system decides it knows enough. Think of it less like a camera and more like a detective running down leads — each answer surfaces the next question.
How the agent loops through queries to fill in the gaps
The core idea is a continuous query-refine loop driven by an AI agent. Here's how the patent describes the flow:
- Extract and index: Raw scene data (visual, spatial, or otherwise) is ingested and indexed so it becomes queryable — essentially turned into a structured knowledge base the agent can interrogate.
- Generate a first query: The AI agent autonomously produces an initial query against the indexed data to pull out relevant scene information.
- Generate follow-up queries: Based on what the first query returns, the agent automatically generates a second query — and so on — to fill gaps or deepen understanding.
- Completeness threshold: The loop terminates when the scene representation meets a predefined completeness criterion, not just when a single pass is done.
The patent emphasizes that this produces a fully indexed and queryable representation of the scene over time — meaning the output isn't just a snapshot, it's a living model that gets refined with each iteration. This is architecturally similar to agentic RAG (Retrieval-Augmented Generation, where an AI retrieves facts before answering), applied to spatial or visual data rather than text documents.
What this means for robotics, autonomous vehicles, and AR
For autonomous vehicles, robotics, and AR/VR systems, scene understanding is the foundational problem. A robot that only gets one pass at perceiving its environment will miss things; a self-driving car that doesn't know what it doesn't know is dangerous. An agent that iteratively closes its own knowledge gaps is a meaningfully different architecture than today's single-inference perception pipelines.
For you as a user, this kind of system could eventually show up in smarter robot assistants, more reliable autonomous vehicles, or spatial computing devices that build a persistent, detailed model of your physical environment — one that updates itself rather than needing to be re-scanned from scratch.
This is a focused, architecturally interesting patent that applies agentic AI patterns — the kind popularized by LLM tool-use frameworks — directly to spatial and visual scene understanding. Nvidia filing this makes sense given its simultaneous investment in autonomous vehicles (DRIVE), robotics (Isaac), and AI inference infrastructure. It's not a splashy consumer-facing idea, but it addresses a real limitation in how current perception systems work.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.