Nvidia Patents an AI That Spots the Same Person Across Different Cameras
Nvidia has filed a patent for a system that can recognize the same person across different camera feeds — even when the angle, lighting, or distance changes — by building a rich AI 'fingerprint' of their appearance.
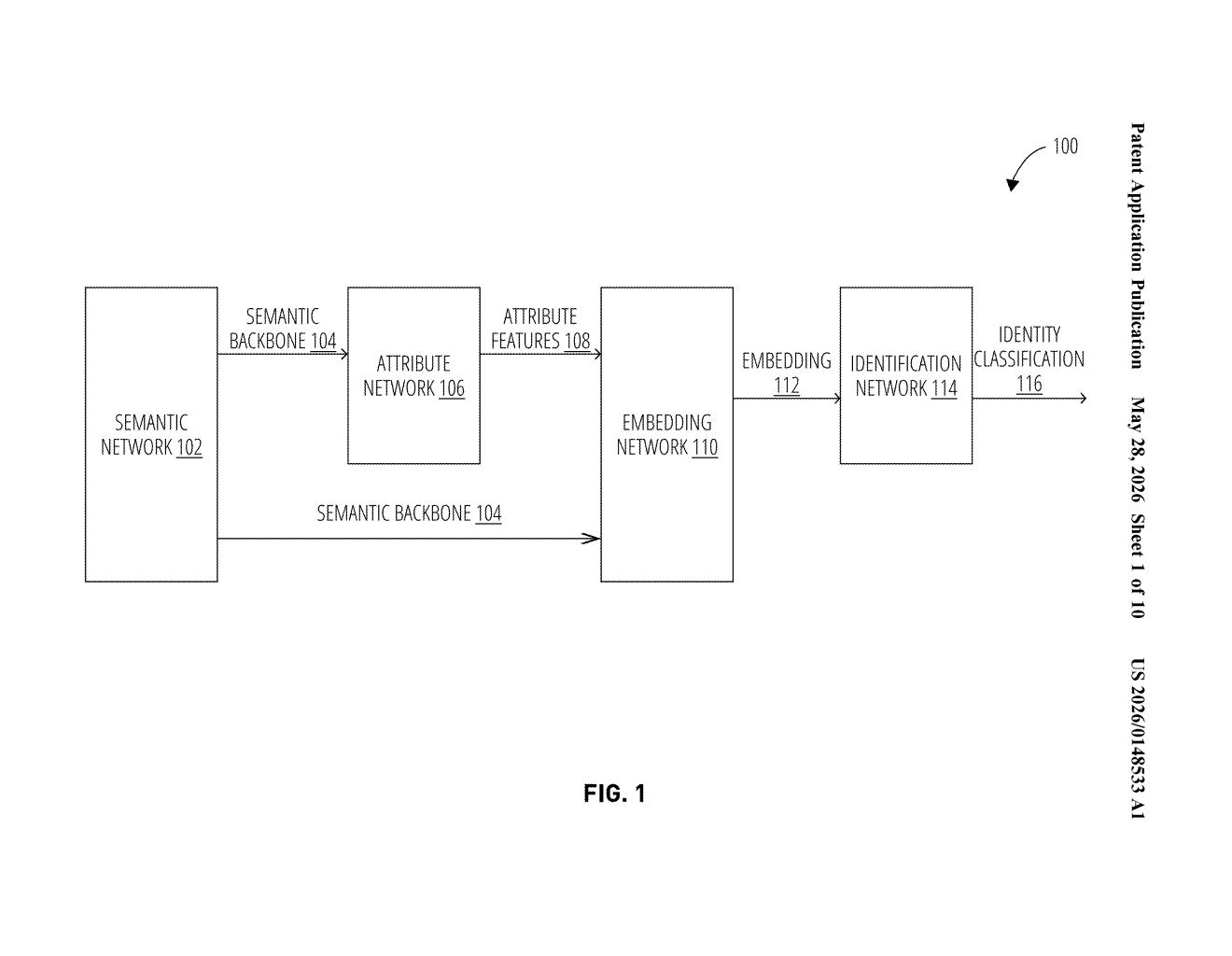
What Nvidia's semantic person re-ID system actually does
Imagine a busy airport with dozens of cameras. Security staff spot someone suspicious on one feed, but then lose them in the crowd. Tracking that person down on a different camera — with a different angle and lighting — is genuinely hard, even for trained humans. That's the problem Nvidia's patent is aimed at.
The system works by analyzing how a person looks in one image — things like clothing color, body shape, or accessories — and turning those observations into a compact mathematical summary called an embedding. Think of it like a fingerprint made from visual clues rather than skin patterns.
Once that fingerprint is built, the system can search through footage from other cameras to find the same person, even if the view is completely different. This kind of technology is called person re-identification, and it's increasingly central to AI-powered camera networks used in logistics, retail, and security.
How the model converts appearance into a searchable embedding
The patent describes a multi-stage pipeline. First, the system takes a first image of a person and extracts semantic data — structured, human-readable descriptions of appearance features (think: 'red jacket,' 'carries a backpack,' 'tall build'). This goes beyond raw pixels and gives the model something more interpretable to work with.
Next, one or more neural network models use that semantic data to generate attribute features — a more refined, machine-optimized representation of those appearance cues. This is the translation layer between human-legible descriptions and what the AI actually computes on.
Those attribute features are then combined with the original semantic data to produce an embedding — a dense vector (essentially a list of numbers) that encodes the person's appearance in a way that's both compact and highly discriminative. This is similar in concept to how face-recognition systems encode facial geometry, but applied to full-body appearance.
Finally, the same model uses that embedding to search a second image — from a different camera, time, or vantage point — and identify whether the same person appears. The key technical claim is that feeding both the raw semantic data and the derived attribute features into the embedding step produces a richer, more accurate representation than using either alone.
What this means for surveillance and multi-camera AI
Person re-identification is one of the hardest practical problems in computer vision — appearances change dramatically across cameras due to lighting shifts, occlusion, and angle. By layering semantic understanding on top of low-level visual features, Nvidia is trying to make re-ID systems more robust and explainable than pure deep-learning black boxes. That matters a lot in enterprise deployments where operators need to understand why a system flagged a match.
Nvidia's position here makes sense: the company already dominates the hardware that runs video analytics at scale through its Jetson edge AI platform. A proprietary re-ID algorithm that runs efficiently on that hardware would be a natural upsell — and a meaningful competitive moat — for customers in retail analytics, logistics, and physical security.
This is solid, applied computer vision work rather than a conceptual moonshot. The layered semantic-plus-attribute approach is a legitimate technical contribution to a real and commercially active problem. Given Nvidia's deep footprint in edge AI hardware, it's easy to see this landing in a future version of Metropolis, their video analytics platform.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.