Nvidia Patents a Cloud-Assisted Rollback System for Cluster Storage Recovery
Losing a storage cluster to corruption or failure is one of the worst days in enterprise IT. Nvidia's latest patent describes a system that lets you roll an entire cluster back to a clean point in time — with the recovery menu served up from the cloud.
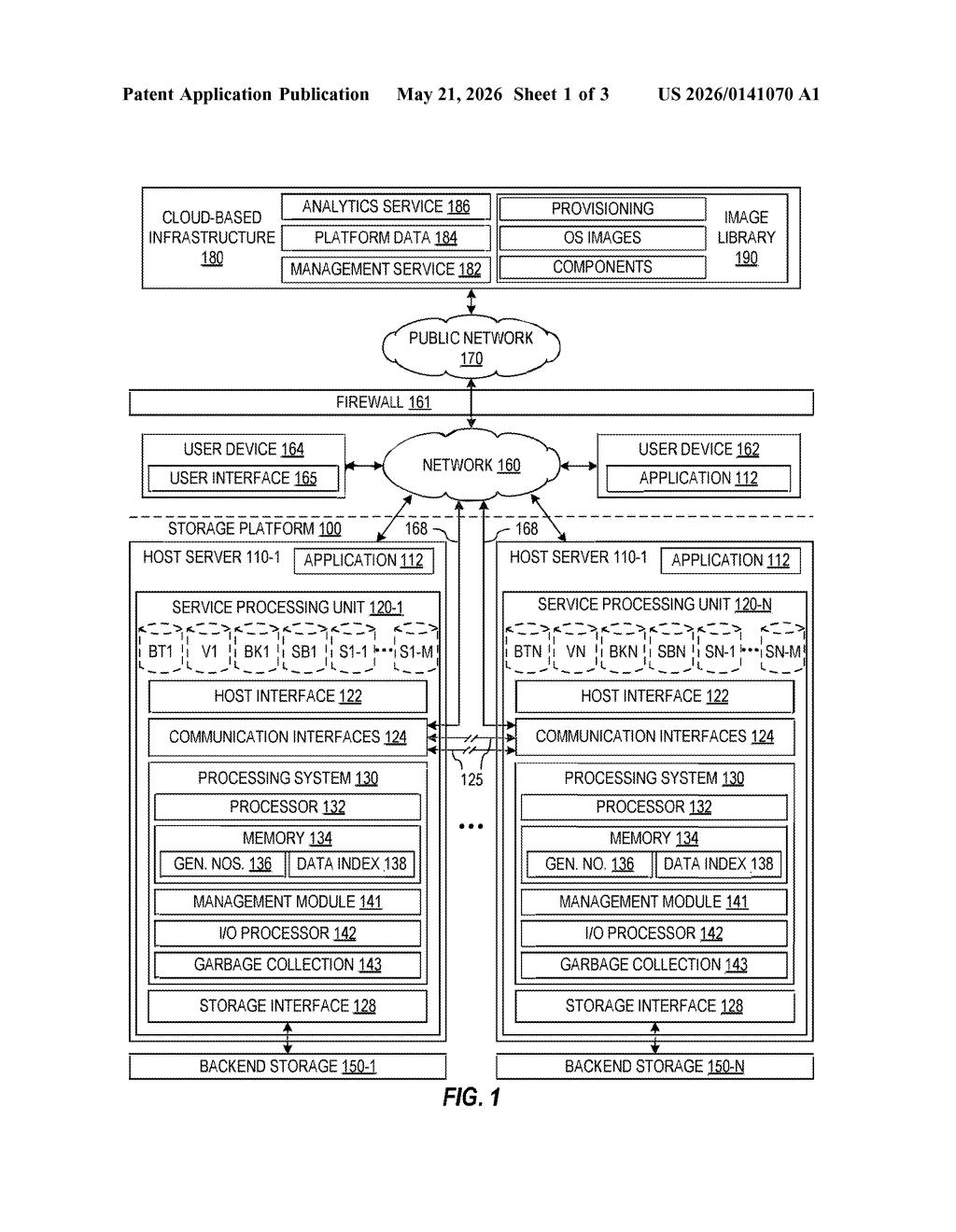
How Nvidia's snapshot rollback system actually works
Imagine your company's data center suddenly goes sideways — a software bug, a ransomware attack, or a botched update corrupts data across dozens of servers all at once. You don't just need to restore one machine; you need to wind back an entire interconnected system to a moment before everything broke.
Nvidia's patent describes a storage system where multiple servers take coordinated, time-synchronized snapshots of every data volume they manage. Those snapshot records get reported to a cloud service. When something goes wrong, you contact the cloud service, pick a recovery point from a list of clean moments in time, and the system promotes those snapshots — essentially swapping in the older, good copies — to restore service.
The clever part is the word "synchronized." All the servers pause new incoming operations at the same moment, finish whatever they were doing, and then all take their snapshots together. That means the recovery point is consistent across the whole cluster, not a patchwork of slightly different timestamps.
How the SPUs coordinate snapshots and promote volumes
The patent centers on Storage Processing Units (SPUs) — dedicated processor-and-memory units inside servers that handle storage operations. Each SPU manages a set of volumes (think logical storage buckets that applications read and write to).
At scheduled intervals, the cluster runs through a disciplined shutdown-and-snapshot sequence:
- Suspend new operations: SPUs stop accepting new storage requests so no partial writes pollute the snapshot.
- Complete pending operations: Any in-flight writes finish cleanly.
- Snapshot all volumes simultaneously: Every SPU captures the current state of every volume it owns at that exact moment.
- Prune old snapshots: Snapshots beyond the retention window are deleted to manage storage overhead.
- Report to the cloud service: Metadata about the new snapshot set is uploaded so the cloud catalog stays current.
When a user needs to recover, the cloud-based service presents a list of available rollback points. The user picks one, and the SPUs promote the selected snapshots — meaning those read-only point-in-time copies get elevated to become the live, active volumes. No manual re-imaging of individual servers required.
The first independent claim is intentionally broad, covering any processor-and-memory system that can create paired snapshot sets across multiple volumes and offer them as selectable recovery points.
What this means for enterprise data center resilience
Enterprise storage clusters are notoriously hard to recover at scale. Traditional backup tools tend to treat servers as independent units, which means a cluster-wide restore often involves manually reconciling timestamps across dozens of machines — an error-prone process that can take hours or days. Synchronized snapshot sets solve the consistency problem at the source, and offloading the recovery catalog to a cloud service means the recovery interface survives even if the local infrastructure is completely offline.
For Nvidia, which has been aggressively building out data center and AI infrastructure hardware, this kind of resilience layer is a natural fit alongside its DPU/BlueField product line. BlueField DPUs already handle storage and networking offload tasks — the SPU architecture described here maps closely to that territory.
This is solid, unsexy infrastructure work — exactly the kind of thing that matters enormously to the data center operators buying Nvidia's expensive hardware but gets zero headlines at a product launch. The synchronized snapshot approach is well-understood in enterprise storage (NetApp SnapMirror, VMware vSAN snapshots), but folding it into an SPU-native architecture with cloud-managed recovery metadata is a coherent, practical extension of Nvidia's data center ambitions.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.