Nvidia Patents a GPU-Cluster Approach to Simulate Quantum Systems with Less Data Shuffling
Simulating quantum systems is one of the most computationally brutal tasks in science — and the biggest bottleneck isn't raw math, it's moving data between processors. Nvidia's new patent tackles that bottleneck directly.
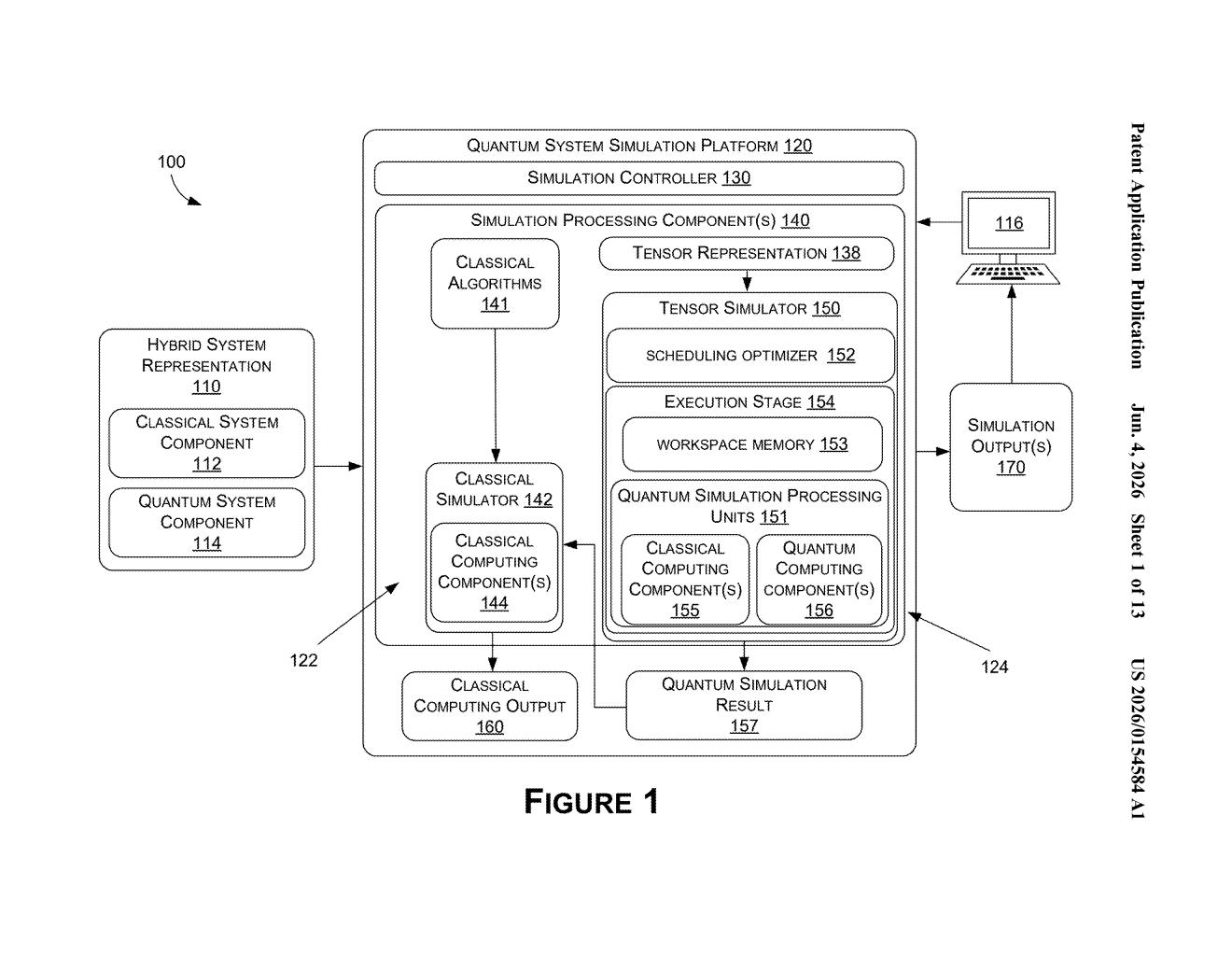
How Nvidia's quantum simulator cuts GPU communication costs
Imagine you're trying to simulate how a molecule or a small quantum computer behaves over time. The math involved is so complex that you need hundreds of GPUs working in parallel. The problem? Those GPUs constantly have to share data with each other, and that back-and-forth communication is often slower than the actual calculations.
Nvidia's patent describes a scheduling system that figures out the most efficient order to hand data between GPUs. It groups the work so that as much computation as possible happens locally on each GPU — without needing to talk to the others — before any big data shuffle happens.
Think of it like packing a moving truck: instead of running between rooms randomly, you plan your trips so you carry everything from one room at once. The result is fewer trips, less waiting, and a faster simulation overall. This is aimed squarely at researchers and developers who need to run large quantum physics simulations on Nvidia's multi-GPU hardware.
How the hypergraph scheduler organizes tensor redistribution
The patent centers on simulating the time dynamics of quantum many-body systems — essentially, how complex quantum states evolve when operators (mathematical transformations representing physical interactions) are applied to them.
The core data structure is a quantum state tensor: a high-dimensional array encoding the quantum state of the system. On a multi-GPU cluster, this tensor has to be distributed across processors, and applying operators to it normally requires lots of inter-GPU communication.
Nvidia's approach introduces a scheduling optimizer that works like this:
- It builds a hypergraph (a graph where a single edge can connect more than two nodes) representing the relationships between the tensor's dimensions (called modes) and the operators that act on them.
- A clustering algorithm partitions the hypergraph into groups, identifying which tensor modes can be kept local to a GPU slice and which need to be distributed.
- The tensor is sliced so that operators can be applied to non-distributed (locally held) modes — meaning no cross-GPU communication is needed for those operations.
- The process repeats iteratively until all operators in the full quantum many-body operator have been applied.
The key insight is that by carefully deciding which dimensions to distribute and when, the system dramatically reduces the total number of expensive redistribution steps needed across the cluster.
What this means for large-scale quantum research on GPU clusters
For quantum physics researchers and computational chemists, running large-scale quantum simulations on GPU clusters is already possible — but communication overhead between GPUs often kills performance at scale. A smarter redistribution schedule means you can simulate larger quantum systems, or simulate the same systems faster, without needing more hardware.
For Nvidia, this is also strategically significant. As quantum computing hardware matures slowly, classical simulation of quantum systems on GPU clusters remains the dominant tool for quantum algorithm research. Owning the software stack for that workflow — schedulers, simulators, and all — reinforces Nvidia's position as the default infrastructure for quantum research, even before real quantum computers are widely available.
This is genuinely useful systems research, not just a paper patent. The communication-bottleneck problem in distributed tensor operations is real and well-documented, and applying hypergraph partitioning to schedule around it is a clever, principled approach. It's also squarely in Nvidia's wheelhouse — the same kind of low-level scheduler optimization that made CUDA dominant. Worth watching if you care about HPC or quantum simulation infrastructure.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.