Nvidia Patents a System That Moves AI Models Between Chips Mid-Task
Most AI systems are locked to a specific chip once they start running. Nvidia is patenting a way to shuffle pieces of a neural network between different hardware in real time — while the AI is actively working.
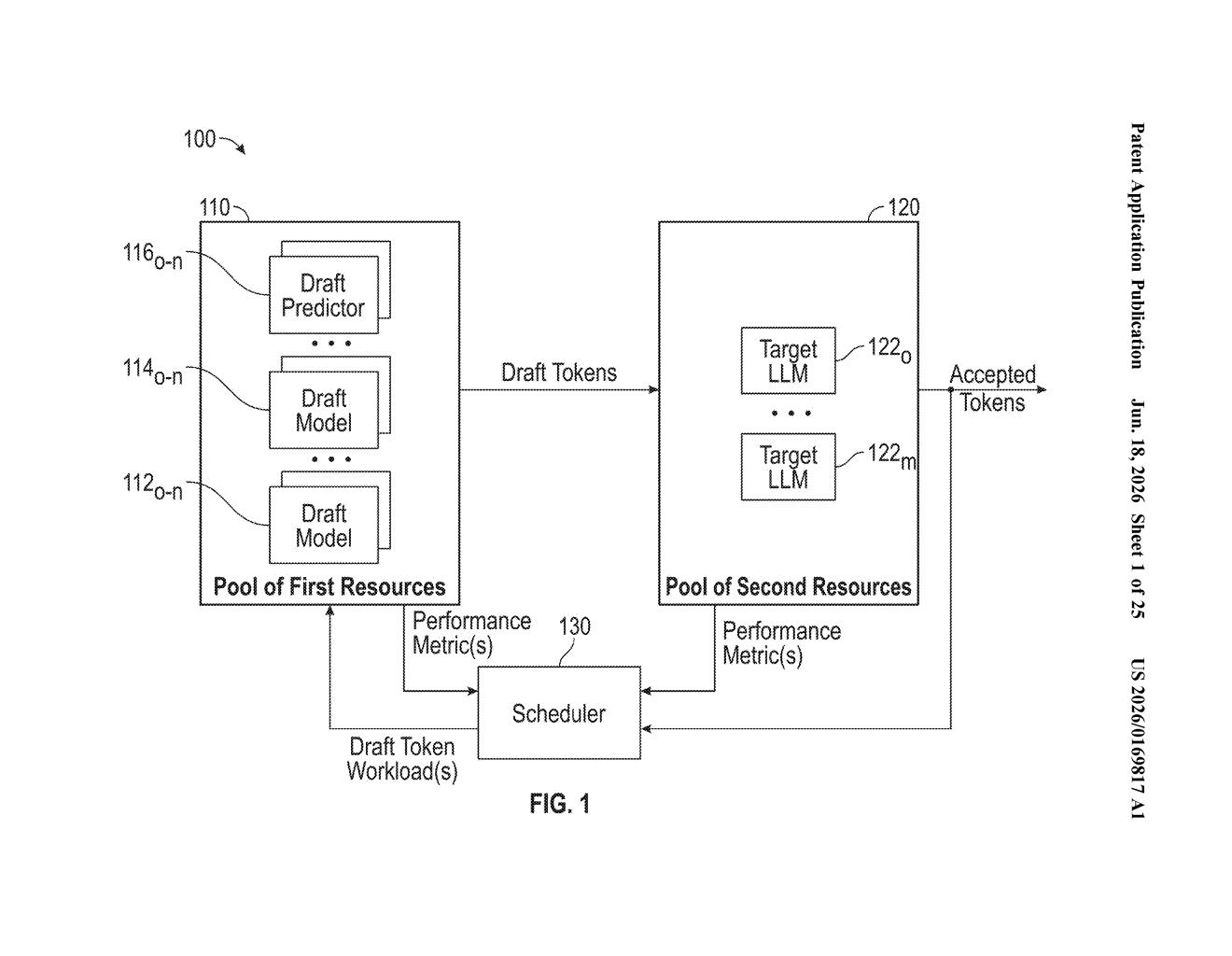
What Nvidia's on-the-fly chip-switching actually does
Imagine a restaurant kitchen where every chef is assigned to one station and can't move, even if the grill is slammed and the salad station is idle. That's roughly how most AI systems work today: a model gets assigned to a chip, and it stays there, even if that chip gets overloaded.
Nvidia's patent describes a processor that watches how busy different parts of an AI model are — and how much spare capacity different chips have — then shuffles pieces of the workload around to wherever there's room. This happens while the AI is already running, not between jobs.
The practical upshot: instead of one AI job monopolizing a powerful GPU while another job idles on weaker hardware, the system could balance the load automatically, making better use of the chips you already have.
How the processor decides when to reassign a neural network
The patent describes a processor with circuits designed to monitor two things simultaneously: inferencing workloads (how much computation each piece of an AI model needs at any given moment) and hardware capabilities (what each available chip can actually handle right now).
When those two factors shift — say, one part of a neural network suddenly needs a lot more compute, or a GPU frees up — the system can reassign that portion of the model to different hardware without stopping the overall job. The key word in the claim is dynamically: this isn't a one-time assignment at startup, it's an ongoing process.
The patent covers scenarios where:
- Multiple neural networks are running at the same time and competing for resources
- A single large model is split across several chips and the load on each section changes
- Hardware itself changes capability mid-run (for example, due to thermal throttling or a chip coming back online)
The underlying idea — dynamic workload migration — is borrowed from general computing (operating systems have long moved software processes between CPU cores), but applying it to neural network inferencing adds real complexity because AI models have strict data dependencies between layers.
What this means for data centers running multiple AI models
Data centers running AI inference at scale waste a surprising amount of GPU time because workloads are unevenly distributed. A system that rebalances in real time could mean more AI requests handled per chip, which translates directly to lower cost per query for companies running large models.
For Nvidia specifically, this kind of capability would make its multi-GPU server products — like the NVLink-connected systems in its DGX line — more appealing, because they'd squeeze more throughput out of hardware customers already own. It also positions Nvidia's chips as the orchestration layer, not just the raw compute, which is where the long-term platform value tends to accumulate.
This is a real engineering problem worth solving, and Nvidia is well-placed to solve it — they control both the chips and the software stack (CUDA, TensorRT) needed to make dynamic reassignment actually work. The patent claim itself is broad, but the underlying idea has enough practical depth that it's likely already being built into future driver or system software.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.