Nvidia Patents a Matrix Multiply That Starts Before the Data Fully Arrives
Nvidia's latest patent tackles one of the most unglamorous bottlenecks in AI chip design: the processor sitting idle while it waits for numbers to finish loading before it can start multiplying them.
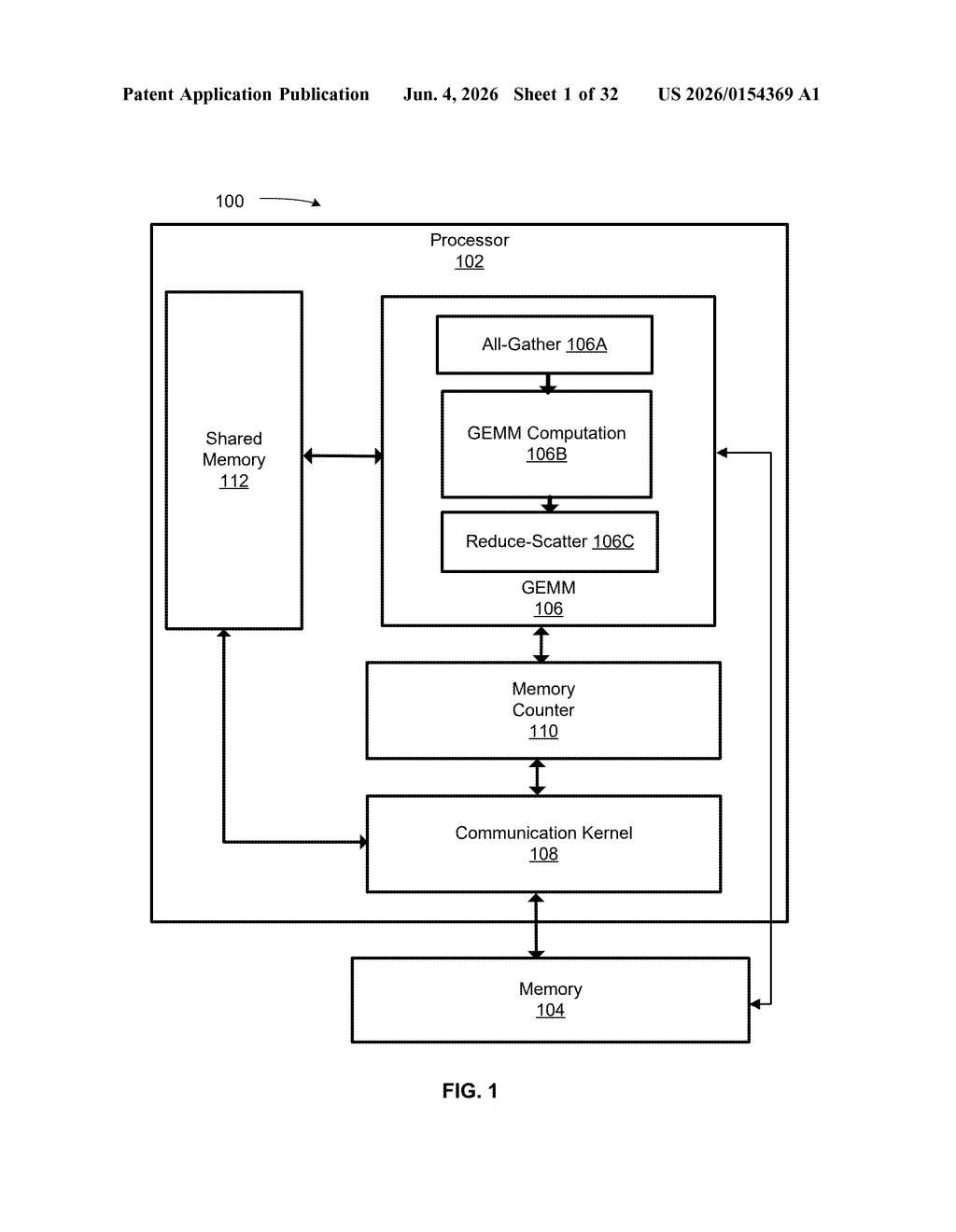
How Nvidia's early-start matrix math actually works
Imagine a chef who won't start chopping vegetables until every single ingredient has been delivered to the kitchen. That's how traditional matrix math on a chip can behave — it waits for all the numbers to arrive before it begins crunching. Nvidia's patent describes a way to let the processor start working on the parts that have already arrived, rather than waiting for the full batch.
Matrix multiplication — the core math behind almost every AI model — involves loading huge grids of numbers into the processor and multiplying them together. The trick here is that the circuit checks whether part of the data has been loaded, and if so, gets to work on that portion immediately.
For you as an end user, this kind of optimization is invisible — but it's the sort of low-level improvement that adds up to faster AI inference, lower power consumption, and better utilization of expensive GPU silicon.
How the circuit checks load status before firing GEMM ops
The patent centers on GEMM operations (General Matrix Multiply — the fundamental building block of neural network computation). Modern GPUs run thousands of these in parallel, but they can stall when the data pipeline can't keep up with the compute units.
The core idea: instead of waiting for the full input matrix to be resident in memory before kicking off computation, the processor's circuits check a status flag indicating whether data has been partially loaded. If the answer is yes — even partially — those circuits can begin executing the portions of the GEMM that are ready.
This is essentially a form of eager execution or speculative data consumption applied to matrix math. It reduces the latency gap between memory load operations and arithmetic execution — a gap that becomes increasingly painful at scale when you're running trillion-parameter models.
- Circuits monitor load-completion status at a granular level
- GEMM sub-operations are dispatched as soon as their required data slice is available
- The overall multiplication completes faster by overlapping load and compute phases
What this means for GPU throughput in AI training
GPU compute utilization — the percentage of time the chip is actually doing math versus waiting on memory — is one of the most important real-world metrics in AI infrastructure. Even modest improvements here translate directly into faster training runs and lower cost-per-inference at the data center scale Nvidia operates at.
This patent is squarely aimed at the memory-bandwidth wall that every AI chip designer is fighting. As models get larger, the gap between how fast a chip can compute and how fast it can feed itself data widens. Techniques like this one — starting computation before the data fully lands — are a key tool in closing that gap without requiring a hardware redesign.
This is deep plumbing work — not the kind of thing that gets a product announcement slide — but it's exactly the type of micro-optimization that separates Nvidia's GPU performance from competitors at scale. The concept of overlapping load and compute isn't new in computer architecture, but patenting a specific circuit-level implementation for GEMM operations signals that Nvidia is baking this aggressively into future silicon designs.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.