Nvidia Patents a Way to Speed Up the Math at the Heart of Every AI Model
Almost every AI model — from image generators to chatbots — runs on one operation repeated billions of times: matrix multiplication. Nvidia just filed a patent for a way to make that operation faster by encoding the numbers before doing the math.
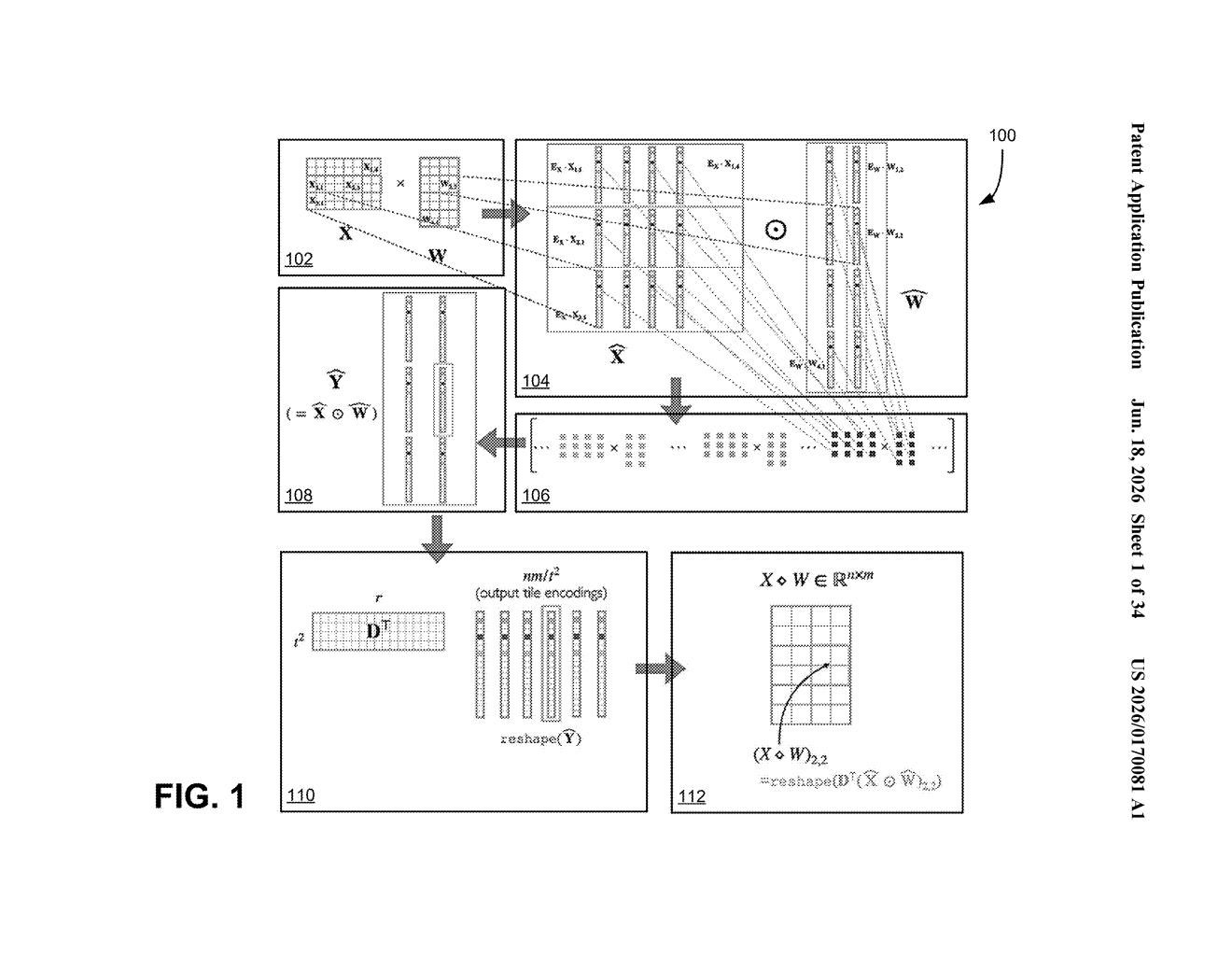
What Nvidia's encoded matrix math actually does
Imagine you're adding up a huge stack of receipts. Instead of tallying every single line item one by one, you group them, compress each group into a shorthand summary, and then do the arithmetic on those summaries. You get to the same answer, but faster.
That's roughly what this Nvidia patent describes for matrix multiplication — the core calculation that powers AI models, graphics rendering, and scientific simulations. Rather than multiplying two large grids of numbers directly, the system first converts chunks of each grid into compact encoded representations, then multiplies those encodings together.
The goal is to reduce the raw computational workload without sacrificing accuracy. For Nvidia — whose GPUs are the primary hardware running today's AI workloads — even modest speedups in this single operation could translate into meaningful gains across every product that touches machine learning.
How the encoding-and-multiply pipeline works
Matrix multiplication is the fundamental operation behind neural networks: when an AI model processes a prompt or an image, it's doing enormous numbers of these multiplications. The patent describes a system where processors don't work on the original matrix data directly.
Instead, the approach works in two stages:
- Encoding: Each matrix is broken into portions, and each portion is transformed into an encoded representation — a compressed or transformed version that's cheaper to work with mathematically.
- Multiply the encodings: The system performs the matrix multiplication operations on these encoded chunks rather than the raw data, collecting partial products along the way.
- Reconstruct: The partial products are combined to produce the final result equivalent to multiplying the original matrices.
The key insight is that working in an encoded space can reduce the number of arithmetic operations needed. This is related to decades of theoretical work on fast matrix multiplication algorithms (like Strassen's algorithm from the 1960s), which showed that clever reformulations can cut the operation count significantly. The two inventors — Nir Ailon and Omri Weinstein — are academic researchers known for work in randomized algorithms and theoretical computer science, which suggests the encoding here may be probabilistic or sketch-based rather than a simple blocking scheme.
What this means for AI chip performance
Matrix multiplication speed is the single biggest bottleneck in AI training and inference. If Nvidia can shave even a fraction of the operations needed per multiplication, that benefit compounds across every layer of every model running on its hardware — faster training runs, lower power draw, more tokens generated per second.
This patent also signals that Nvidia is pursuing algorithmic improvements, not just silicon ones. Adding faster math at the software or microarchitecture level means existing GPUs could potentially benefit through driver or compiler updates, not just next-generation chips. That's a different kind of efficiency gain than cramming more transistors onto a die.
This is a quiet but genuinely interesting filing. The inventors' backgrounds in theoretical computer science suggest this isn't incremental engineering — it may be an attempt to bring information-theoretic ideas about fast matrix multiplication into real hardware. Whether it survives the gap between theory and production silicon is the real question, but the direction is worth tracking.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.