Nvidia Patents a Way to Mix Compute and Graphics Work in the Same GPU Queue
Modern GPUs constantly juggle graphics rendering and general-purpose compute work — but traditionally those two types of tasks have lived in separate queues. Nvidia's new patent describes an API that lets them share the same line.
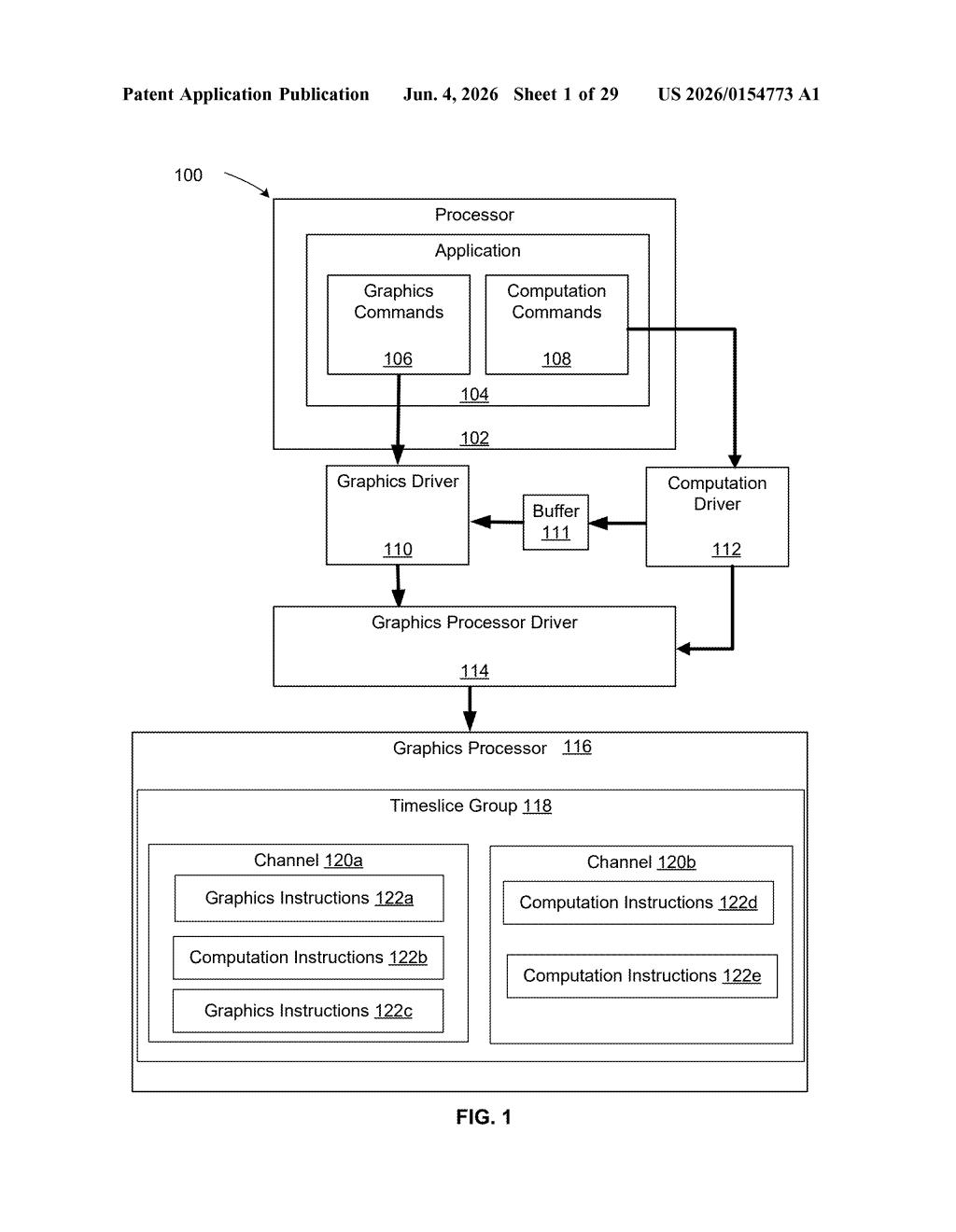
What Nvidia's mixed GPU kernel queuing actually does
Imagine a busy kitchen where the grill cook and the prep cook have to use separate serving windows to pass food to the front — even when they're working on the same dish. It slows everything down. Your GPU has a similar problem: it typically handles graphics tasks and general-purpose compute tasks through separate pipelines.
Nvidia's patent describes a way to let these two types of work — graphics kernels and non-graphics (compute) kernels — sit together in the same sequential queue. An API call is all it takes to place them side by side, in order, so the GPU can work through both without switching contexts or waiting on separate schedulers.
The practical payoff is smoother, more efficient GPU execution — especially in workloads like game engines or AI-assisted rendering that blend heavy compute tasks (like physics simulations or ML inference) with traditional rendering work.
How the API sequences graphics and compute kernels together
At the core of modern GPU programming is the concept of a kernel — a small program that runs in parallel across hundreds or thousands of GPU cores. Graphics kernels handle things like vertex shading and pixel rasterization. Non-graphics kernels (sometimes called compute kernels) handle everything else: physics, AI inference, post-processing, simulation.
Today, these two types of kernels typically live in separate command queues — dedicated pipelines that the GPU drains in order. That separation means synchronization overhead: the GPU has to coordinate between queues, often stalling one while it waits for the other to finish a dependent step.
This patent describes an API (application programming interface) — essentially a standardized call a developer or driver can make — that stores non-graphics kernels sequentially alongside graphics kernels in the same queue. The key word is "sequentially": the ordering is preserved, so dependencies are naturally respected without extra synchronization primitives.
- A single queue holds both graphics and compute work in submission order
- The API abstracts away the separation, letting the driver or hardware handle scheduling
- Processors execute the mixed queue without needing cross-queue barriers for in-order work
What this means for GPU workload efficiency
For GPU-heavy applications — game engines, real-time ray tracing, AI-augmented rendering — the overhead of coordinating separate graphics and compute queues is a real cost. Collapsing them into a single ordered queue can reduce synchronization stalls and simplify driver logic, which translates to better frame pacing and lower latency.
This is also strategically relevant as GPU workloads blur. Modern games run ML-based upscalers (like DLSS), physics solvers, and audio simulation alongside traditional rendering — all on the same chip. A cleaner queuing model makes it easier to schedule that mix efficiently, and it's the kind of low-level plumbing that benefits Nvidia's entire ecosystem from gaming to professional visualization.
This is unglamorous but genuinely useful GPU infrastructure work. The separation between graphics and compute queues is a known friction point for developers building mixed workloads, and an API-level fix is the right layer to solve it. It won't ship as a feature anyone tweets about, but it's exactly the kind of driver-level improvement that shows up as smoother frame times.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.