Nvidia Patents a Way to Teach AI to Spot the Things It Almost Never Sees
AI vision models are only as good as their training data — and when certain objects appear rarely in that data, the model learns to overlook them. Nvidia's patent targets that blind spot directly.
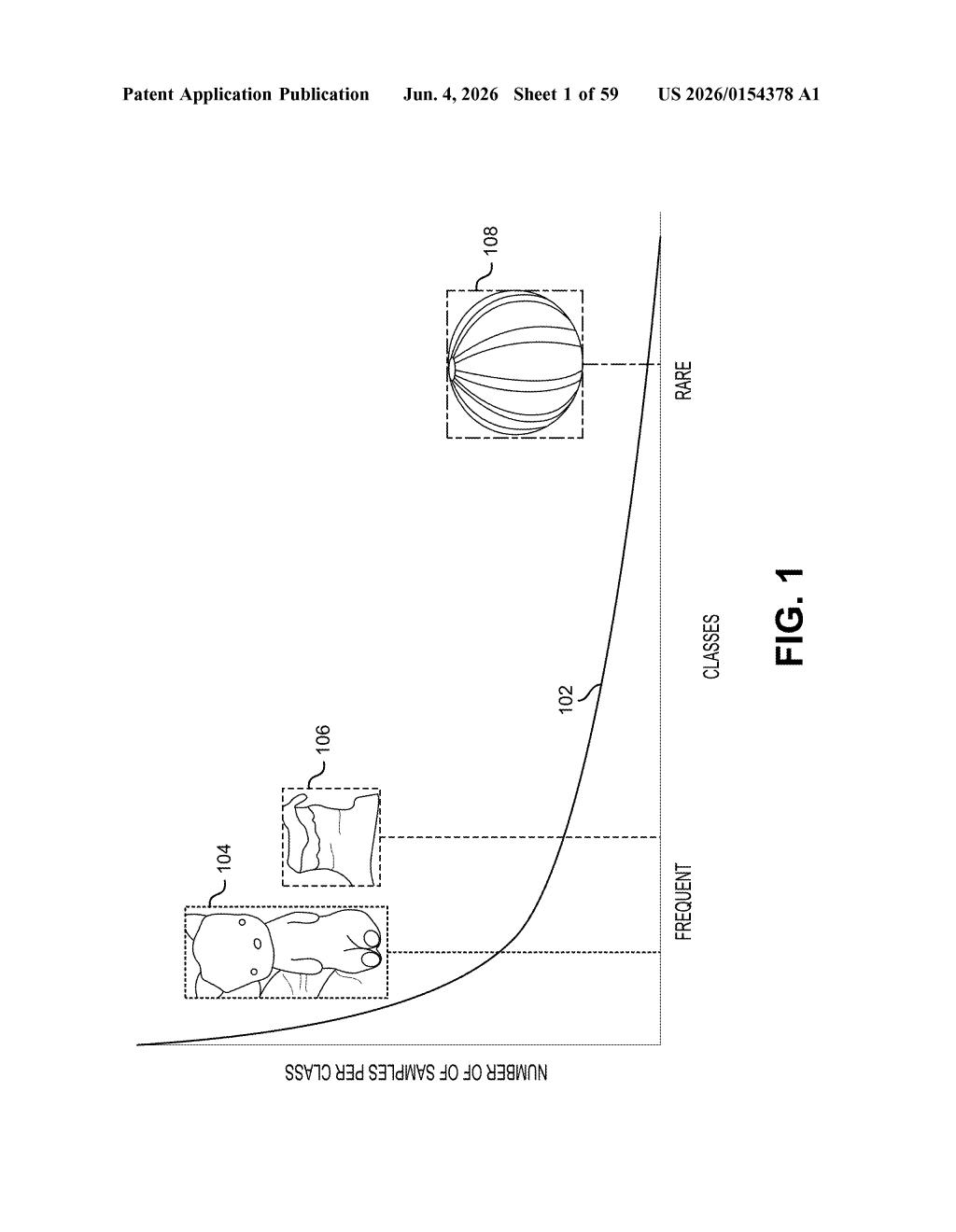
What Nvidia's image resampling fix actually does
Imagine teaching a child to recognize animals by showing them a photo album that has 500 pictures of dogs but only 3 pictures of armadillos. The child will get great at spotting dogs and terrible at spotting armadillos. AI vision models have exactly the same problem.
Nvidia's patent describes a way to fix this imbalance without going out and collecting thousands of new photos. Instead, the system scans your existing training images, finds examples of under-represented objects hiding inside them — say, a pedestrian in the corner of a street scene — crops those objects out, and uses those crops to create additional training examples.
The result is a training dataset that gives rarer objects a fairer share of attention, so the model learns to recognize them with the same confidence it has for common objects. No new photography required — just smarter use of what you already have.
How Nvidia crops and rebalances under-represented objects
The patent describes a resampling pipeline for machine learning training datasets, focused on correcting class imbalance — the well-documented problem where models trained on lopsided data become systematically worse at detecting rare categories.
The core mechanism works like this:
- The system scans a set of training images and tallies how often each object type (class) appears.
- It identifies under-represented classes — object types that appear far less frequently than others.
- It extracts crops or patches from existing images that contain those rare objects.
- Those extracted patches are used to augment the training set with additional examples of the rare class, effectively upweighting it without requiring new data collection.
The approach is a form of data augmentation (artificially expanding a training dataset using transformations of existing samples) combined with targeted resampling. By pulling rare objects out of scenes where they appear incidentally, the system creates focused training examples that teach the model to recognize those objects in isolation and in context.
The patent is broadly written to cover the apparatus, system, and technique — suggesting Nvidia sees this as a foundational data-pipeline component rather than a narrow trick.
What this means for self-driving and vision AI reliability
For autonomous driving and robotics — two of Nvidia's biggest platform bets — rare-object detection failures aren't just accuracy statistics, they're safety issues. A model that rarely sees motorcyclists or road debris in training will be less reliable when those things actually appear.
This technique matters because it addresses the problem at the data layer, before a model is ever trained. That makes it complementary to architectural improvements (better model designs) and potentially cheaper than collecting and labeling new data. If Nvidia bakes this into its training infrastructure — tools like TAO Toolkit or the DRIVE platform — it becomes a background quality-improvement that every model trained on those platforms quietly benefits from.
This is a solid, practical contribution to a real and persistent problem in applied ML. Class imbalance in training data is responsible for a huge share of real-world AI failures, and Nvidia's approach of mining existing images for rare-object crops is both resource-efficient and scalable. The claims were canceled in this publication, which limits what we can assess about final scope, but the underlying technique is directly relevant to Nvidia's core customers building perception systems.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.