Nvidia Patents a Neural Network That Reconstructs Video Frames Without Redoing the Work
Nvidia's new patent describes a neural network that looks at a fully-processed reference frame and uses it to reconstruct nearby frames — without starting from scratch each time. It's a smarter way to handle video that hasn't changed much.
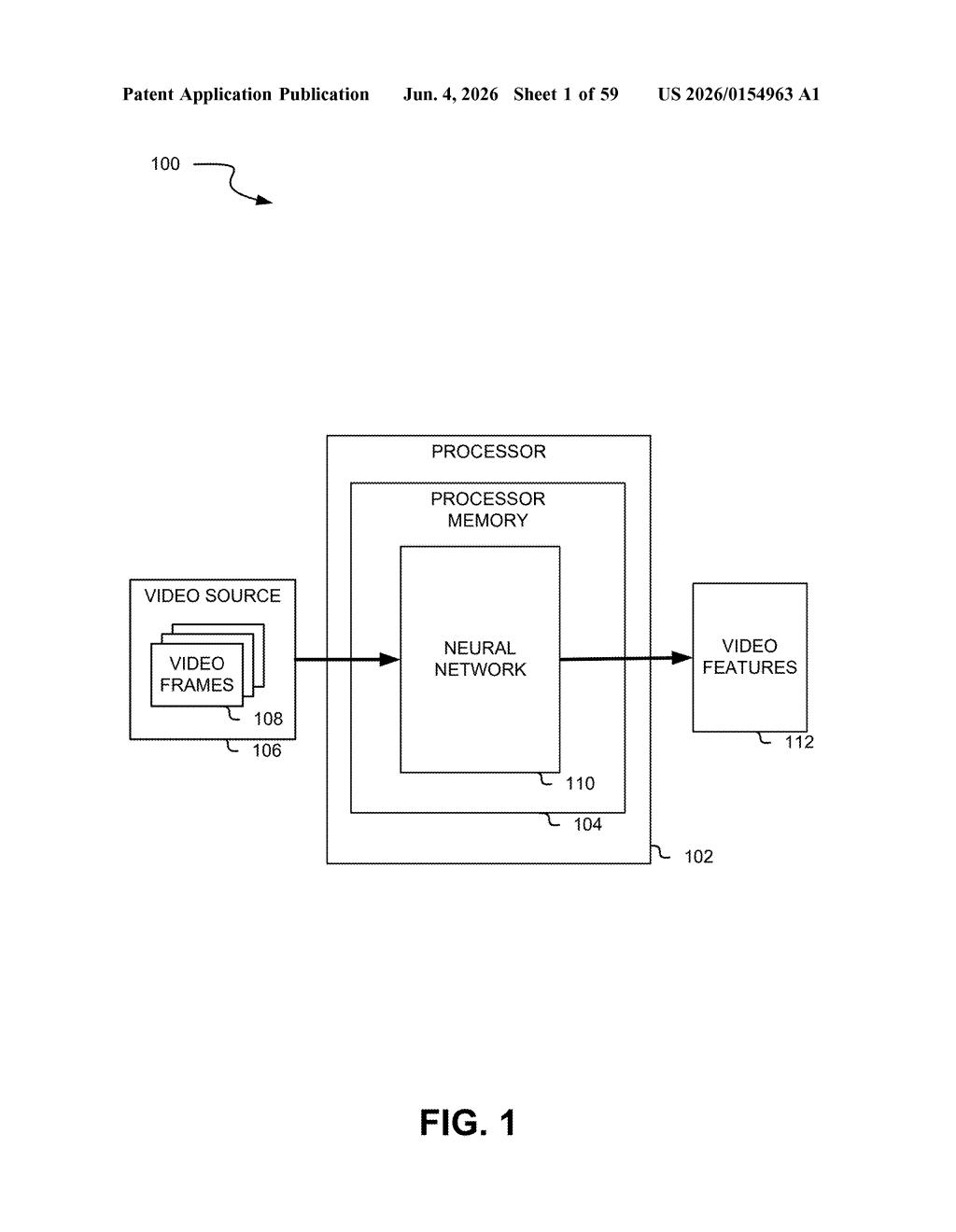
How Nvidia skips redundant work between video frames
Imagine watching a video where the camera is barely moving — maybe a slow pan across a landscape. Most of the pixels in one frame are nearly identical to the last. Redoing all the heavy computational work for every single frame, even when very little changes, is wasteful.
Nvidia's patent tackles this by designating certain frames as keyframes — the fully-processed anchors. For nearby frames that look very similar to the keyframe, the system skips a full re-analysis and instead derives the new frame's internal representation from the keyframe's. It only does the heavy lifting when things actually change significantly.
The result is a more efficient pipeline for neural-network-based video generation or processing. Your GPU (or whatever processor runs this) does less redundant work, potentially speeding up video rendering or AI-driven video synthesis without a visible quality hit.
How the keyframe feature map carries over to new frames
The patent describes a processor with circuits that run a neural network pipeline in two distinct modes depending on how much a new frame differs from the previous keyframe.
For a keyframe — a frame with significant differences from its predecessor — the system generates a full feature map (an internal neural network representation that encodes what's in the image: shapes, textures, context). This is the expensive step.
For subsequent frames where the number of pixel-level differences stays below a threshold, the system classifies that frame as a non-keyframe. Instead of regenerating a feature map from scratch, it derives the new feature map from the existing keyframe's feature map, adjusted only by the delta between the two images.
The key components are:
- Feature map reuse: carry forward the neural network's internal state from the keyframe rather than recomputing it
- Difference-based classification: a threshold mechanism decides which frames need full processing
- Delta-conditioned generation: the second frame's feature map is generated using both the first feature map and information about what changed
This is conceptually similar to how traditional video codecs use I-frames and P-frames — but applied inside a neural network's internal representation layer rather than at the pixel level.
What this means for AI video and real-time rendering
For AI-driven video generation and real-time neural rendering, computational efficiency is the central bottleneck. Running a full neural network inference pass on every frame of a 60fps video is enormously expensive. A keyframe-delta approach could reduce that cost significantly for scenes with limited motion or change — which is a large portion of typical video content.
Nvidia is well-positioned to embed this kind of optimization directly into GPU hardware or its video-processing SDKs. If this approach gets incorporated into tools like DLSS or Nvidia's AI video pipelines, it could mean faster, cheaper neural video processing on consumer and professional hardware alike — with fewer visible artifacts from the reuse approach.
This is a targeted, pragmatic engineering patent — not a flashy AI demo. The keyframe-delta concept is familiar from codec design, and Nvidia is applying it one layer deeper, inside the neural network's feature representation. That's the genuinely interesting part. It's worth watching because it fits neatly into Nvidia's existing GPU acceleration roadmap and could quietly ship inside a future DLSS or video SDK update.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.