Nvidia Patents a Way to Stop Processors from Forgetting How Code Fits Together
Nvidia is patenting a technique that watches how pieces of code get linked together at runtime — and uses that knowledge to make the processor run them faster the next time around.
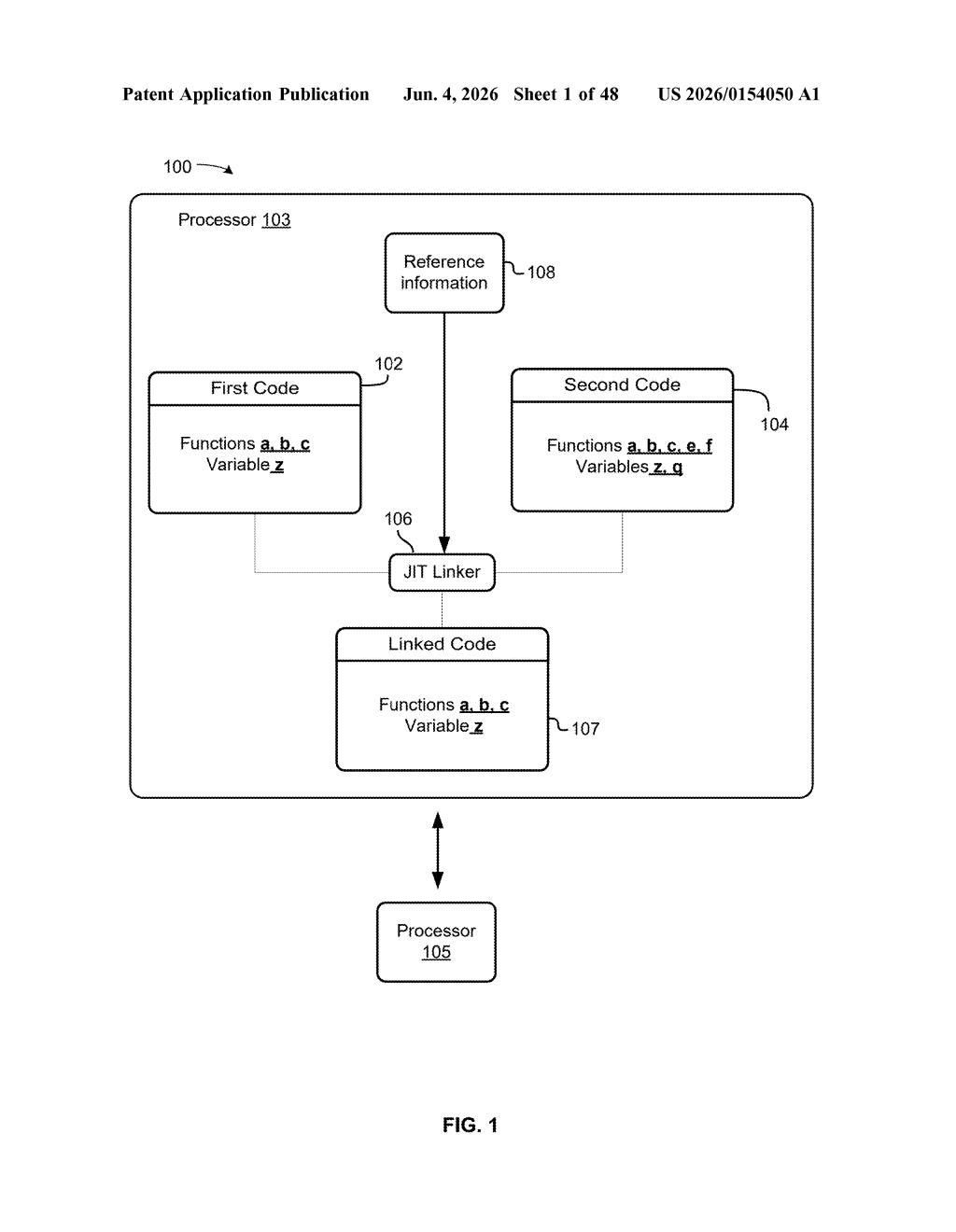
What Nvidia's linked-code optimization actually does
Imagine your computer runs the same set of instructions over and over, but every time it has to re-figure out how those instructions connect to each other. That re-figuring wastes time. Nvidia's idea is to remember which pieces of code have already been linked together, so the processor doesn't have to repeat that work.
Think of it like a GPS that saves your most common routes. Instead of recalculating directions from scratch every morning, it just loads the route it already knows. Nvidia's patent applies that same logic to how code segments are assembled and executed inside a processor.
The system stores a small flag — an indication — of whether two code chunks have already been linked. When the processor encounters them again, it can skip the linking overhead entirely and run the optimized version straight away.
How the system stores and uses code-linkage indicators
At its core, this patent describes a linked code optimization system. When a processor executes code, it often needs to combine or "link" multiple code segments together — think of subroutine calls, shader programs on a GPU, or just-in-time compiled blocks. That linking step has overhead.
Nvidia's approach adds a mechanism to store an indication of whether two specific code portions have already been linked. That stored flag (essentially a cached record of a past linking event) lets the runtime skip redundant linking work on subsequent executions.
This falls into a broader category called profile-guided or history-aware optimization — using what the system already knows about past execution to make future execution cheaper. The patent's claims were canceled (claims 1–32 listed as canceled in the filing), which is a procedural note and may indicate the patent is being revised or refiled.
- Track whether code segments have been previously linked
- Store that linkage state as an indicator
- Use the indicator to skip or accelerate future linking operations
- Apply the optimization at the processor level, not just in software
What this means for GPU and CPU runtime performance
For Nvidia, whose GPUs execute enormous numbers of shader and compute kernels that get linked and re-linked constantly, even small reductions in linking overhead can translate into measurable throughput gains across millions of parallel threads. This kind of low-level optimization is exactly the sort of thing that quietly shows up in a new driver update or a new GPU architecture without anyone writing a press release about it.
For developers, the implication is a runtime that gets incrementally faster the more it's used — without requiring any changes to the code itself. That's a useful property for real-time graphics, inference workloads, and any application that repeatedly calls the same compiled code paths.
This is unglamorous infrastructure work — the kind of optimization that never makes a keynote slide but compounds into real performance gains over time. The canceled claims make it hard to assess the final scope, but the core idea of caching linkage state is sensible and fits squarely into Nvidia's ongoing push to squeeze more efficiency out of its GPU execution pipelines.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.