Qualcomm Patents a Fix That Keeps AI Sharp After Shrinking It for Low-Power Chips
When AI models get squeezed down to fit on a phone chip, they often get a little dumber. Qualcomm's new patent tackles that problem at the training stage itself — before the model ever ships.
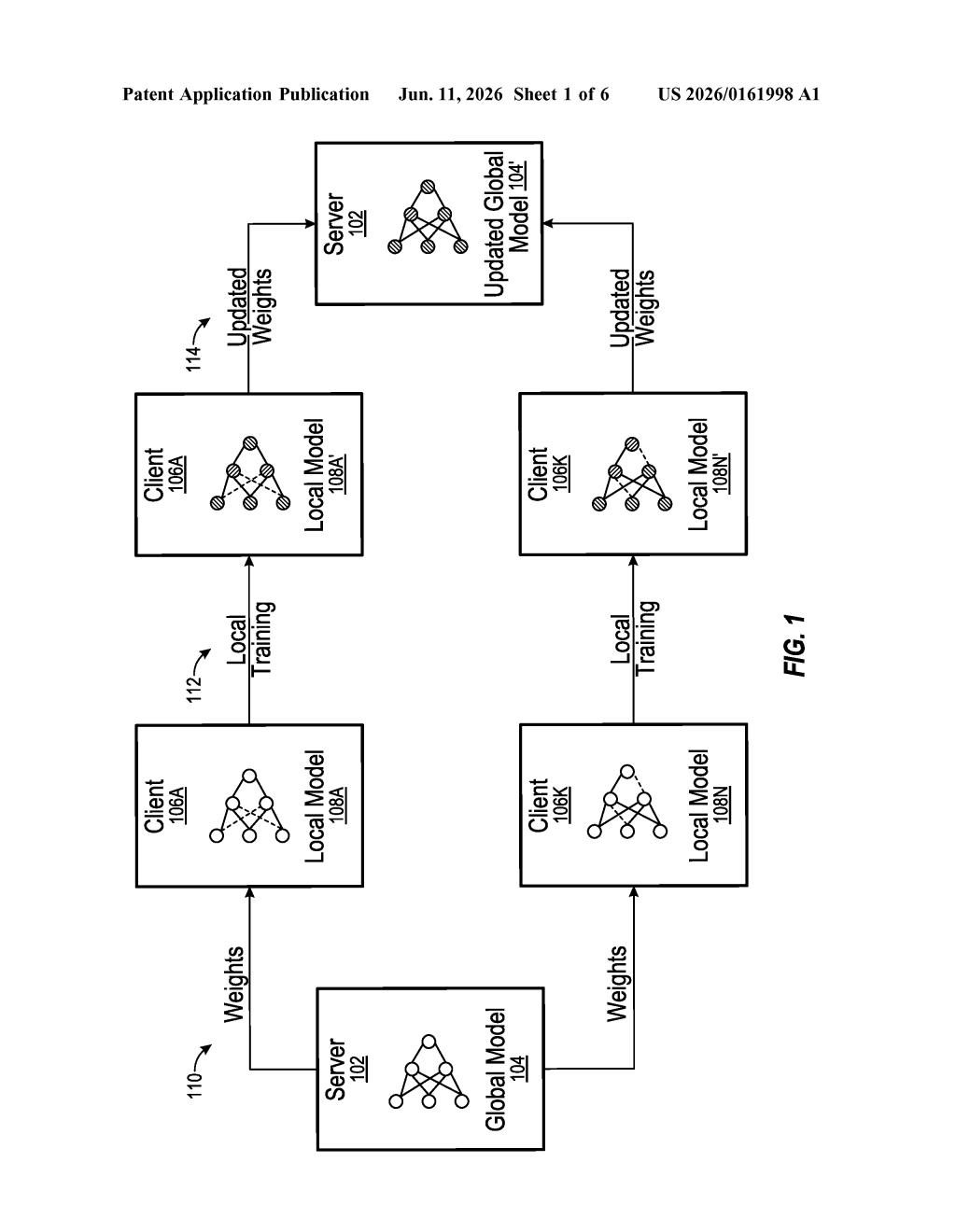
How Qualcomm trains AI across phones without losing accuracy
Imagine a group of students each studying from their own copy of a textbook, then pooling their notes to build a shared answer key — without ever sharing the textbooks themselves. That's roughly how federated learning works: devices train an AI model locally, then send only the updates (not your data) back to a central server.
The catch is that phones and other devices can't run big AI models as-is. They need a compressed, stripped-down version — a process called quantization — and compression tends to shave off accuracy. The model that worked great on a beefy server suddenly stumbles on your phone.
Qualcomm's patent proposes fixing this during the training process itself. Instead of training the model normally and compressing it later, each device trains with a special rule built in that makes the model naturally more tolerant of compression. The devices then send their compression-friendly updates back to the server, so the final shared model stays sharp even on low-power chips.
How the local objective function bakes in compression tolerance
The patent describes a federated learning system — a setup where many client devices (think phones or tablets running Snapdragon chips) each train a shared AI model on their own local data, then report their updates to a central server. No raw user data leaves the device.
The core invention is a modification to the local objective function — the mathematical goal each device optimizes during training. Normally, that goal is simply "get the predictions right." Qualcomm's modification adds an extra term that also rewards the model for staying accurate after being quantized (compressed from high-precision numbers to low-bit representations that cheap hardware can run efficiently).
In practice, this means:
- A federated server sends the current model to client devices.
- Each device trains the model using the modified objective, which penalizes weight configurations that fall apart under compression.
- Each device sends an updated model back to the server.
- The server aggregates those updates into a new global model that is inherently more quantization-robust.
The key insight is that quantization robustness is baked in during collaborative training rather than patched on afterward with a separate compression step — which is typically how it's done today.
What this means for on-device AI on Snapdragon hardware
For Qualcomm, this is directly relevant to its Snapdragon chip business. Snapdragon powers a massive share of Android phones, and Qualcomm has been pushing hard on running AI inference locally rather than in the cloud. Any technique that lets a collaboratively trained model survive aggressive compression without losing accuracy makes on-device AI more practical — and makes Qualcomm's chips look better doing it.
For you as a user, the downstream effect is AI features that work reliably on mid-range phones, not just flagships. It also supports privacy: if models can be trained and run well on-device, your data never has to leave your phone to improve the AI. That's a meaningful trade-off in a world increasingly wary of what tech companies do with personal data.
This is quiet, infrastructure-level research — not a splashy product announcement — but it addresses a real and persistent tension in deploying AI on edge devices. Qualcomm is essentially trying to remove one of the main excuses for sending AI workloads to the cloud, which fits its long-term chip strategy cleanly. Worth tracking if you follow on-device AI.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.