Reading Body Language to Predict Pedestrian Movement
Before a pedestrian steps into the road, their body often gives it away — a turned shoulder, a weight shift, a glance. Waymo is now patenting a system that lets its self-driving cars read those physical cues in 3D, in real time.
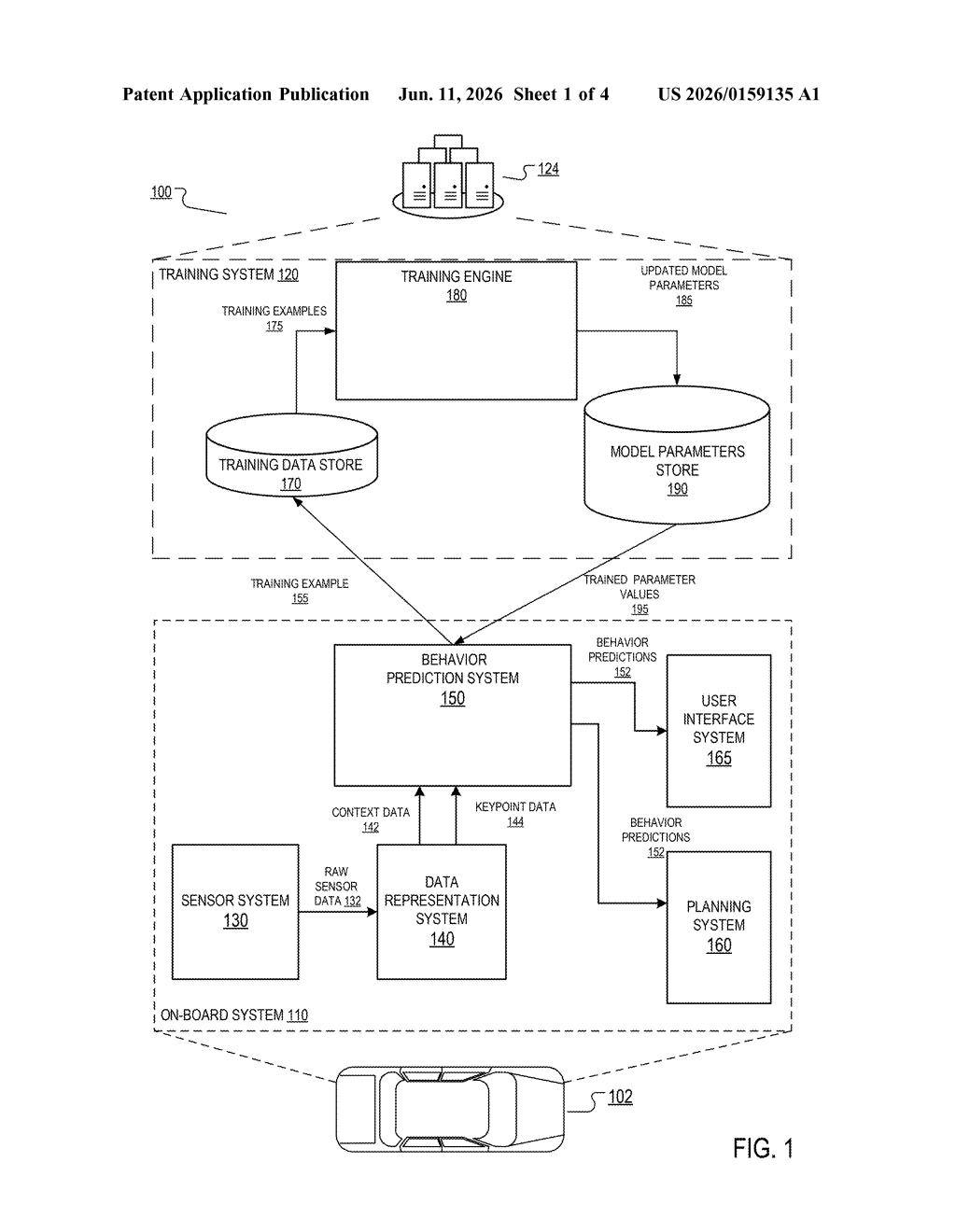
How Waymo's car reads a pedestrian's body pose
Imagine a person waiting at a crosswalk, not yet moving but leaning forward and angling their feet toward the street. That body language tells you something is about to happen — even before their foot leaves the curb. Waymo's patent is about teaching a self-driving car to pick up on exactly that kind of physical signal.
The system tracks 3D body keypoints — essentially a skeleton map of joints like shoulders, hips, knees, and feet — for every nearby pedestrian. It then combines that pose information with a record of where the person has been moving over the past few seconds. Together, those two data streams give the car a richer picture of what the pedestrian is likely to do next.
The goal is to make the car's predictions more accurate earlier, so it can slow down, yield, or steer away before a situation becomes dangerous — not just react after someone steps into traffic.
How the neural networks fuse pose and movement history
The patent describes a machine-learning pipeline with three main stages working in parallel before merging into a final prediction.
- Context encoder: A neural network processes the movement history of all nearby agents — pedestrians, cyclists, vehicles — up to the current moment, producing a summary of the scene's dynamics for the target pedestrian.
- Keypoint encoder: A separate neural network processes the 3D keypoint data for that same pedestrian. Keypoints are a skeletal representation: a set of coordinates marking major joints. In 3D, that means the system knows not just where someone is in the horizontal plane but also how they're oriented in space — whether they're crouching, turning, leaning forward.
- Combined decoder: The outputs of those two encoders are merged into a single combined embedding (think of it as a compressed numerical fingerprint of everything known about that person right now). A decoder network then reads that fingerprint and outputs a behavior prediction — essentially a probability map of where the pedestrian is likely to be at future time steps.
The key insight is that trajectory history alone misses short-term intent signals. Someone can be standing perfectly still while their body is already oriented to cross — the keypoint encoder catches that; the context encoder alone would not.
What better pedestrian prediction means for self-driving safety
Pedestrian prediction is one of the hardest problems in autonomous driving. People don't follow lane markings, they change their minds mid-step, and they interact with each other in ways that are hard to model from GPS traces alone. By adding body pose as an independent input channel, Waymo is essentially giving its vehicles a sense closer to what a human driver does intuitively — reading body language at a glance. That matters most in dense urban scenarios: school crossings, busy intersections, parking lots.
For you as a potential passenger or pedestrian near a Waymo vehicle, the practical upside is a car that yields earlier and brakes more smoothly — because it anticipated your move instead of reacting to it. It also reduces the chance of a false-positive emergency stop triggered by someone who merely glanced at the road but wasn't actually crossing.
This is genuinely substantive work, not a defensive filing. Adding a dedicated 3D-pose encoder as a parallel input stream — rather than just hoping trajectory history captures intent — is a principled architectural choice that addresses a real gap in current prediction models. Waymo has been publishing research in this direction for a few years, so this patent reflects an active engineering bet, not speculative IP hoarding.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.