IBM Patents an AI Code Writer That Learns From Its Own Broken Builds
Most AI coding tools ignore compiler errors and leave fixing them to the developer. IBM's new patent describes a system that treats every error as a lesson, looping back to train itself until the code compiles clean.
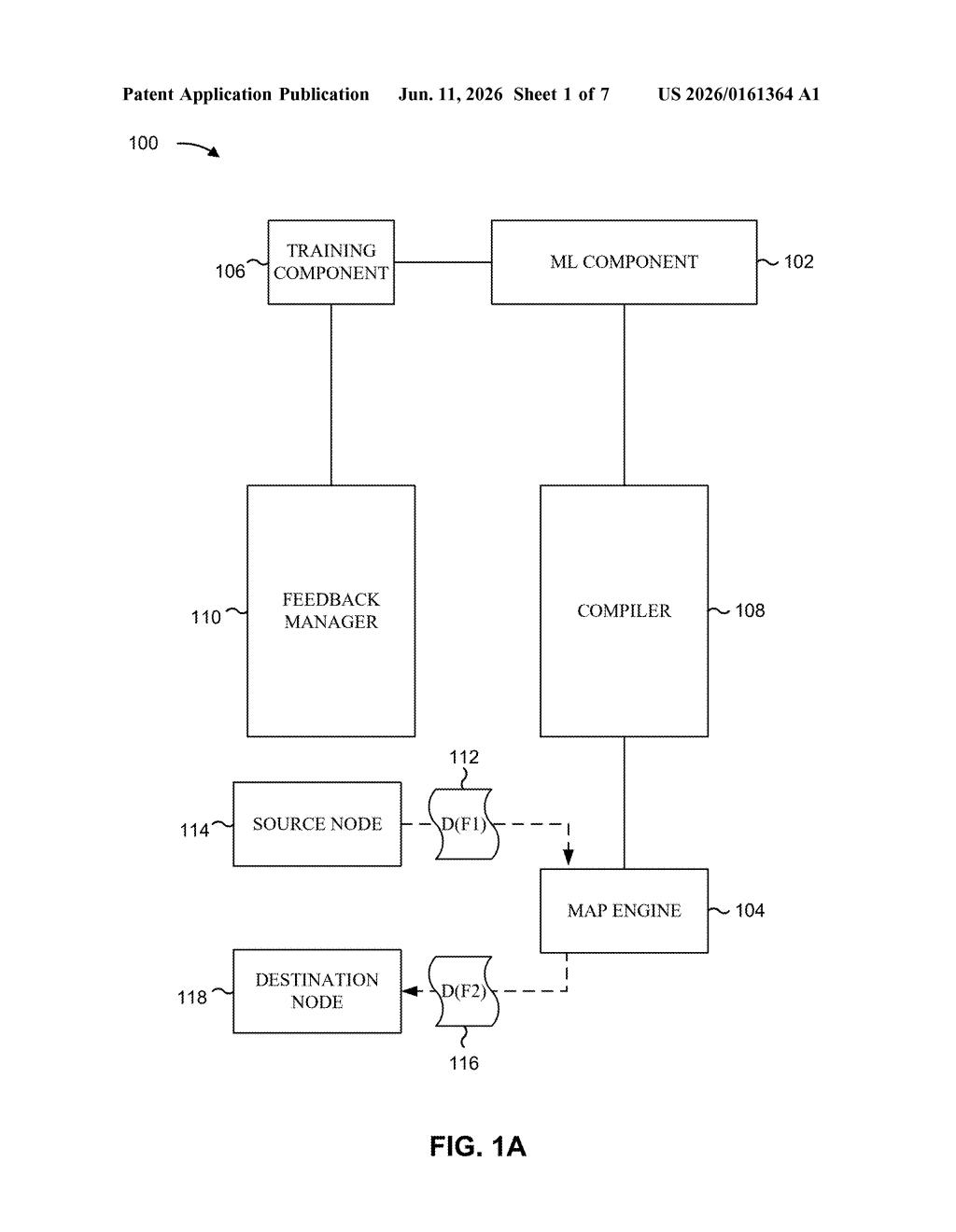
How IBM's self-correcting code generator works
Imagine hiring a junior developer who, every time their code fails to run, reads the error message, learns from it, and immediately rewrites the code — without you having to explain anything. That's roughly what IBM is patenting here.
The system uses a type of AI training called reinforcement learning, where the AI gets scored on its output. Here, the 'score' comes directly from the compiler — the tool that checks whether code is valid. If the AI's code produces errors, those errors feed back into the AI as training data, nudging it to do better next time.
The specific focus is on electronic data interchange (EDI) mapping — the behind-the-scenes code that translates data between different business systems, like turning a purchase order from one company's format into another's. It's unglamorous but essential work, and IBM is betting an AI that teaches itself from its own mistakes could handle more of it automatically.
How the reinforcement loop uses compiler feedback
The patent describes a system built around a reinforcement learning loop (a training method where an AI learns by receiving rewards or penalties for its outputs, similar to how a dog learns tricks). Instead of a human scoring the AI's work, the compiler does it.
Here's the sequence:
- An ML model generates a mapping object — source code that translates data from one EDI format to another.
- That code is fed into a compiler (a program that checks and converts source code into a runnable format).
- The compiler produces a feedback signal containing any errors it found — syntax mistakes, data mismatches, or logical flaws.
- Both the compiled output and the error signal are fed back to retrain the ML model.
- The model then generates a second, improved mapping object, which is passed to a map engine for execution.
The key insight is that the compiler itself becomes the teacher. The AI doesn't need labeled training examples created by humans — it generates its own feedback by attempting to compile, failing, and learning from those failures. This is sometimes called a self-supervised loop, though IBM's framing leans on reinforcement learning terminology.
What this means for enterprise data integration work
EDI mapping is one of those problems that sounds trivial until you try to do it at scale. Large enterprises exchange thousands of data files daily — invoices, shipping notices, inventory updates — each potentially in a different format. Writing the translation code by hand is tedious, error-prone, and requires specialized knowledge. An AI that can draft and self-correct that code could meaningfully reduce the manual effort involved.
More broadly, this patent points toward a design principle IBM is clearly interested in: using existing software tools as training signals. If compilers can teach AI to write compilable code, the same logic might extend to other automated validators — linters, test suites, schema validators. That's a broader and more interesting idea than the specific EDI use case suggests.
This is a real and useful idea, but it's narrowly scoped to a corner of enterprise software that most people never think about. The reinforcement-learning-from-compiler-feedback concept has legs beyond EDI — IBM is essentially demonstrating a general principle — but the patent's specific claims are tightly bounded around one workflow. Worth noting if you follow enterprise AI tooling; easy to skip if you don't.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.