Samsung Patents a Way to Split Heavy AI Data Crunching Across the Network Itself
Instead of funneling all data to one central server to be combined, Samsung's new patent describes a system where the network switches themselves do part of the math — spreading the work out and potentially cutting the bottlenecks that slow down large AI training jobs.
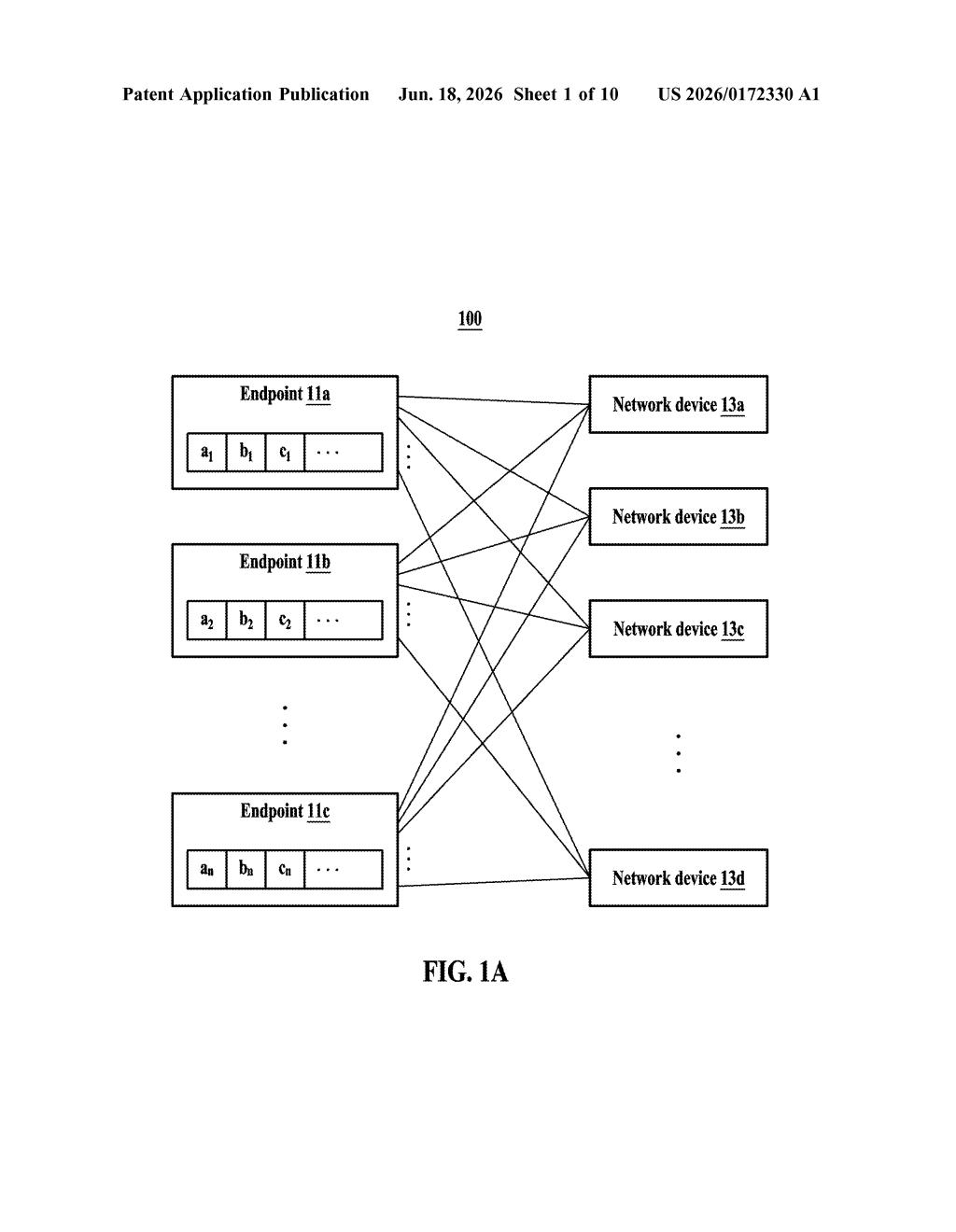
What Samsung's distributed data-crunching patent actually does
Imagine a group project where everyone writes their section, emails it all to one person, and that person types up the final report alone. That one person becomes the bottleneck — and the bigger the group, the worse it gets. This is exactly the problem that slows down large AI training systems today.
Samsung's patent proposes a different approach: instead of sending all the raw data to one central machine, the network devices in between — the switches and routers — do some of the combining work themselves. Each device produces its own partial result, and those partial results are then merged into a final answer.
The result is that no single machine has to do all the heavy lifting. The workload is shared across the network, which could mean faster AI training runs, less congestion, and better use of expensive hardware.
How partial collective data flows between network nodes
The patent describes a collective operation — a standard technique in distributed computing where many machines each hold a piece of data, and the goal is to combine all those pieces into one result (think: summing up gradients across thousands of GPUs during AI model training).
In the traditional approach, every machine sends its data to a central aggregator, which combines everything and sends the result back. Samsung's method inserts the network devices (switches, routers) into that process as active participants:
- Each endpoint (a GPU server, for example) sends its local data chunk to the nearest network device.
- Each network device combines the chunks it receives into a partial collective result.
- A designated master network device then merges all the partial results from peer network devices into the final collective output.
This is sometimes called in-network computing — pushing computation into the fabric of the network rather than keeping it at the endpoints. The patent's claim is broad, covering the general method of generating, receiving, and combining these partial results across a hierarchy of network devices.
What this means for large-scale AI training clusters
For anyone running large AI training clusters — the kind used to train foundation models — the interconnect between GPU servers is often the biggest bottleneck. Every time thousands of GPUs need to synchronize their weight updates, a massive volume of data has to travel across the network. Moving even part of that aggregation work into the switches themselves could meaningfully cut the time each synchronization round takes.
Samsung makes both AI chips and networking hardware, so this patent sits squarely at the intersection of both businesses. If in-network computing becomes standard practice for AI infrastructure, having foundational IP in this area could matter commercially — even if this particular filing is fairly abstract.
This is a real and active area of research — companies like Nvidia, Broadcom, and startups building AI networking hardware have all been exploring in-network computing for exactly this reason. Samsung's patent is broad and abstract, which means it's more of a placeholder in the space than a detailed technical blueprint. It's worth tracking, but don't mistake it for a finished product.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.