Adobe Patents a System That Lets You Ask a Database Questions in Plain English
Most corporate databases speak SQL — a formal query language that takes years to learn. Adobe's latest patent describes a way to let anyone type a normal question and get the right answer back, even if their wording doesn't match what's actually stored in the database.
How Adobe's system translates your words into database results
Imagine you work at a company that stores all its customer data in a big database. You want to know how many people bought a particular product last quarter, but to get that answer you'd normally need to write something like SELECT COUNT(*) FROM orders WHERE... — a programming-style command most people never learn.
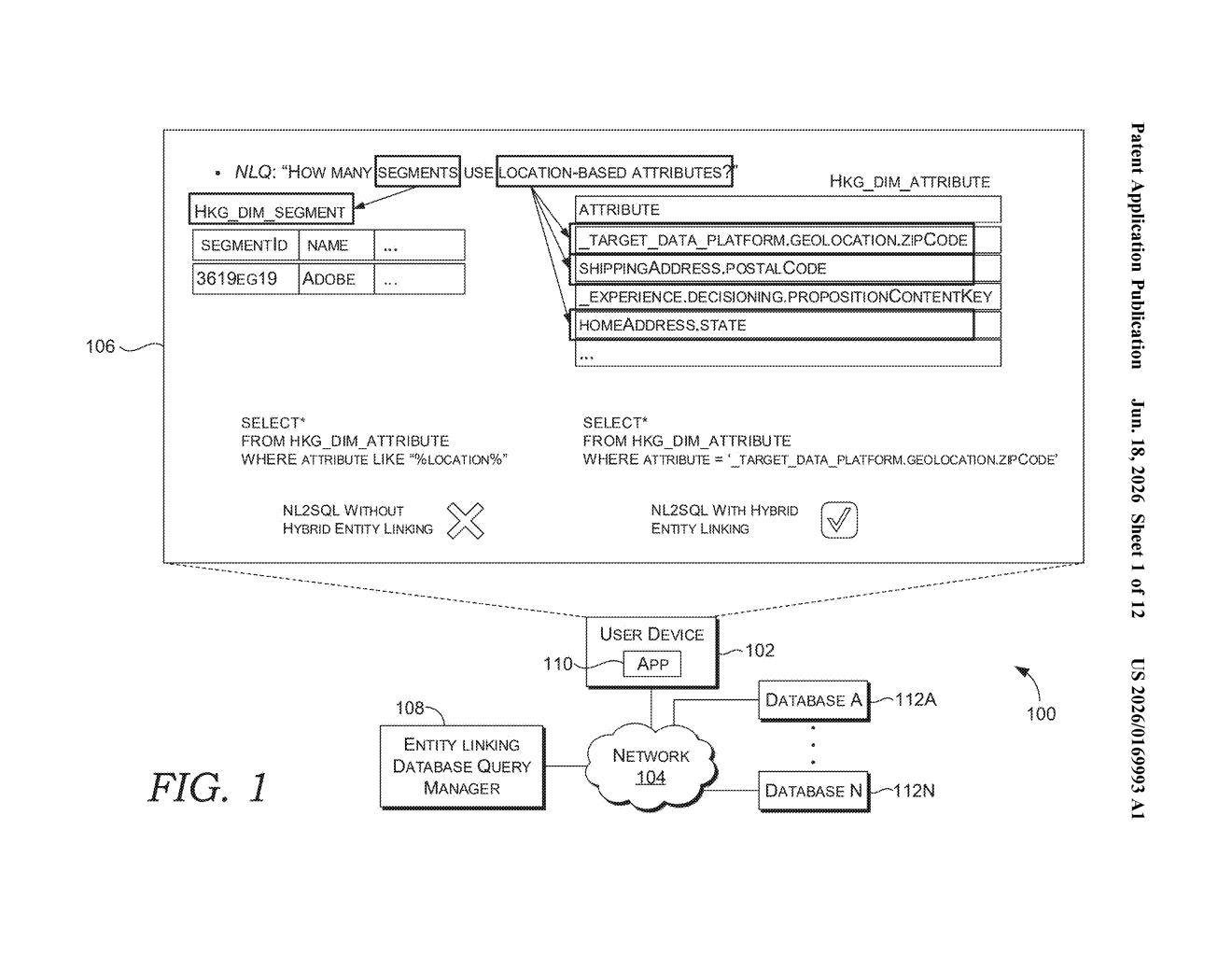
Adobe's patent describes a system that sits between you and the database, translating plain questions into the formal commands the database understands. You type something like "how many customers bought blue sneakers in October," and the system figures out what you mean — even if the database calls them "azure athletic footwear" or abbreviates the month differently.
The trick is that it uses two separate methods at the same time: one that looks for close spelling matches between your words and database entries, and another that matches the meaning of your words rather than the exact letters. Together, they cast a wider net so you get useful results even when your phrasing isn't a perfect match.
How the two-engine matching pipeline finds the right data
The patent describes a pipeline with two matching engines working in parallel on whatever question a user types.
Engine 1 — String matching: The system breaks your question into overlapping word chunks (called n-grams — think "blue sneakers," "sneakers in," "in October") and then compares those chunks against a library of spelling variations for every term in the database. So if the database stores "colour" and you typed "color," the match still works.
Engine 2 — Semantic matching: This engine converts both your question chunks and the database's entity names into numerical representations called embeddings — essentially coordinates in a mathematical space where similar meanings land close together. "Buy" and "purchase" would be near each other even though they share no letters.
After both engines produce a list of candidate matches, a ranking classifier (a trained AI model) scores each candidate on how relevant it actually is to the original question. Only candidates above a confidence threshold get surfaced to the user.
- String matching catches typos and abbreviations
- Semantic matching catches synonyms and paraphrasing
- The classifier filters noise so you don't get irrelevant results
What this means for non-technical Adobe users
For Adobe, whose products like Adobe Experience Platform and various analytics tools sit on top of large customer-data repositories, this kind of system would let marketing teams and business analysts query their own data without needing a data engineer in the room. That's a real competitive advantage — most enterprise software still requires SQL knowledge or pre-built dashboards.
For you as a potential user, the benefit is access. Right now, insight from corporate data often flows through a bottleneck of people who speak "database." A system that genuinely bridges plain language to structured queries could shift that dynamic — assuming it works well enough in practice, which depends on implementation details the patent doesn't guarantee.
This is a well-trodden problem in enterprise software — "natural language to SQL" (NL2SQL) has been a research hot topic for years — but Adobe's dual-engine approach, combining spelling-variation matching with meaning-based matching before a learned ranker, is a sensible and practical architecture rather than just another AI wrapper. The real question is accuracy at scale on messy real-world databases, which a patent can't answer.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.