Intel Patents Circuitry That Spots AI Data-Streaming Before the Cache Gets Swamped
When a processor is running an AI job, it often burns through memory in one long sweep, never touching the same data twice. Intel's new patent is about catching that pattern as early as possible, so the chip can stop wasting its cache on data it'll never reuse.
What Intel's early stream detection actually does
Imagine your fridge has limited shelf space. If you know you're cooking a dish that uses every ingredient exactly once, you wouldn't cram everything in at once. You'd grab ingredients as you need them, keeping the fridge clear. A computer's cache works the same way: it's fast, limited storage sitting between the processor and main memory.
Some AI workloads, like processing a giant matrix of numbers, read through memory in one long pass and never look at the same data twice. These are called streaming workloads. If the processor doesn't know that's what's happening, it wastes precious cache space saving data that will never be reused.
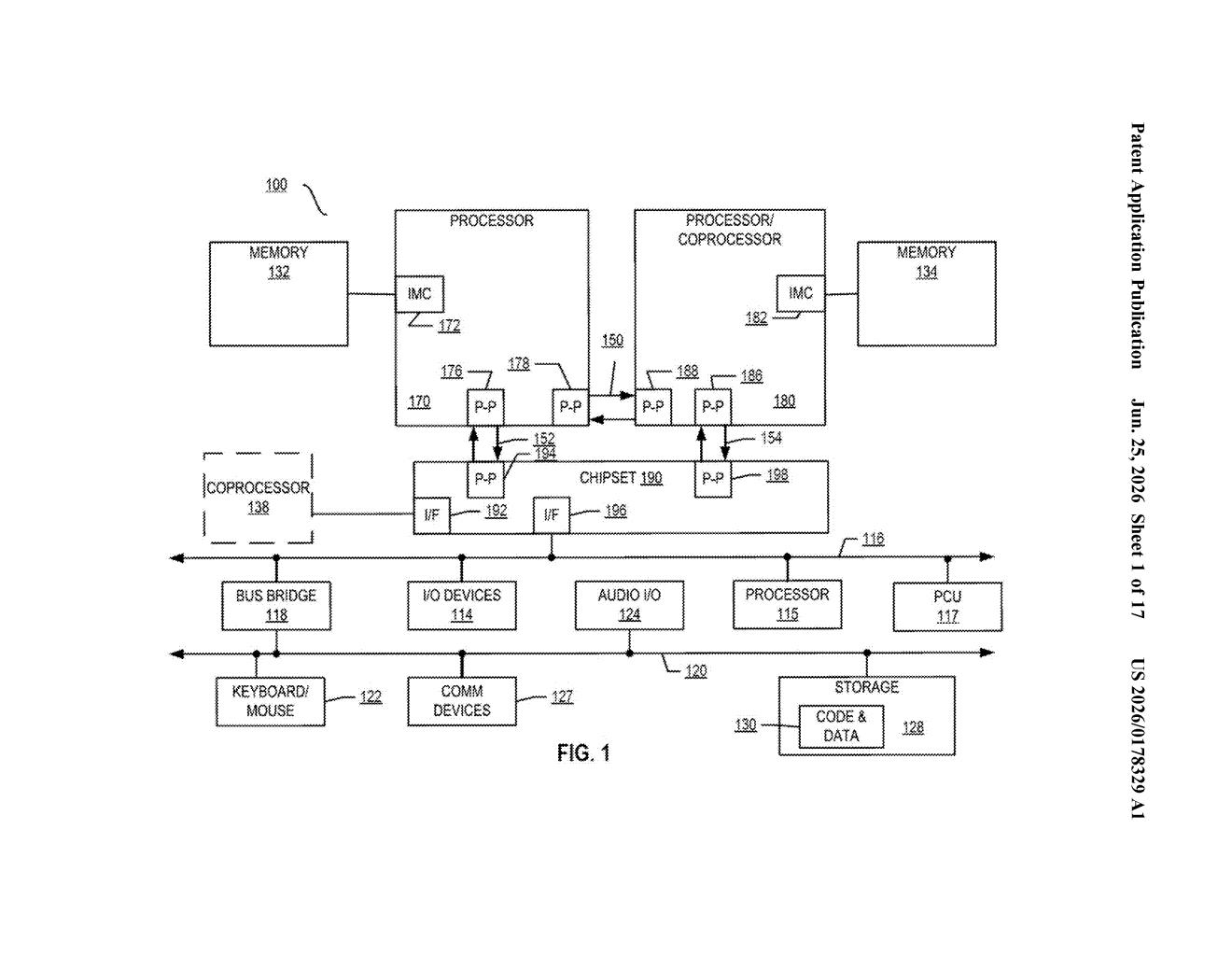
Intel's patent describes circuitry built directly into the processor that watches how load instructions touch memory. As soon as every cache line (a small fixed-size chunk) in a memory page has been requested once, the chip knows it's dealing with a stream. That early warning lets the processor shift strategy and stop polluting the cache with throwaway data.
How the tracker counts cache lines to flag a stream
The patent describes stream detection circuitry built into the processor pipeline, sitting alongside the instruction fetch unit.
Inside that circuitry is a tracker: a small table of entries, one per active memory page (a page being a standard block of memory, typically 4 KB). Each entry holds a demand counter that increments every time a load instruction touches a cache line inside that page. A cache line is the smallest unit the cache can hold, usually 64 bytes, so a 4 KB page contains exactly 64 of them.
Detection logic watches those counters. The trigger condition is precise: when the number of loads touching a given page equals the total number of cache lines in that page, the logic concludes the workload is streaming. In other words, once every slot in the page has been read at least once, the pattern is confirmed.
The key word in the claim is early: this detection fires at the moment the last cache line of a page is first touched, not after multiple passes confirm the pattern. That gives the rest of the processor time to adjust prefetch and cache-eviction policy before the pipeline is already deep into the workload.
What this means for AI chip performance
For AI inference and training, where processors stream through large weight matrices and activation buffers, cache pollution is a real bottleneck. If the chip's cache is full of data it'll never reread, every other process on the same chip gets slower cache performance too. Early detection means the processor can switch to a streaming-friendly mode (bypassing or deprioritizing the cache for that data) before the damage is done.
For Intel, this sits squarely in its effort to make its Xeon and upcoming AI-focused processors more competitive for data-center AI workloads. The logic is implemented in hardware, so it adds no software overhead for the workloads that benefit from it.
This is unglamorous but genuinely useful processor plumbing. Cache pollution from streaming AI workloads is a well-documented performance problem, and hardware-level detection is a cleaner fix than asking software to annotate memory accesses. Whether the specific trigger condition (exactly one load per cache line) proves to be the right heuristic in production is the real question, but the architecture is sound.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.