Meta Patents a Dynamic Queue-Pair System for Data Center Congestion Control
When a data center link gets congested, throwing more bandwidth at it isn't always the answer — sometimes you need smarter traffic lanes. Meta's latest patent describes a system that watches network latency in real time and dynamically hands out extra queue pairs to the nodes that are struggling most.
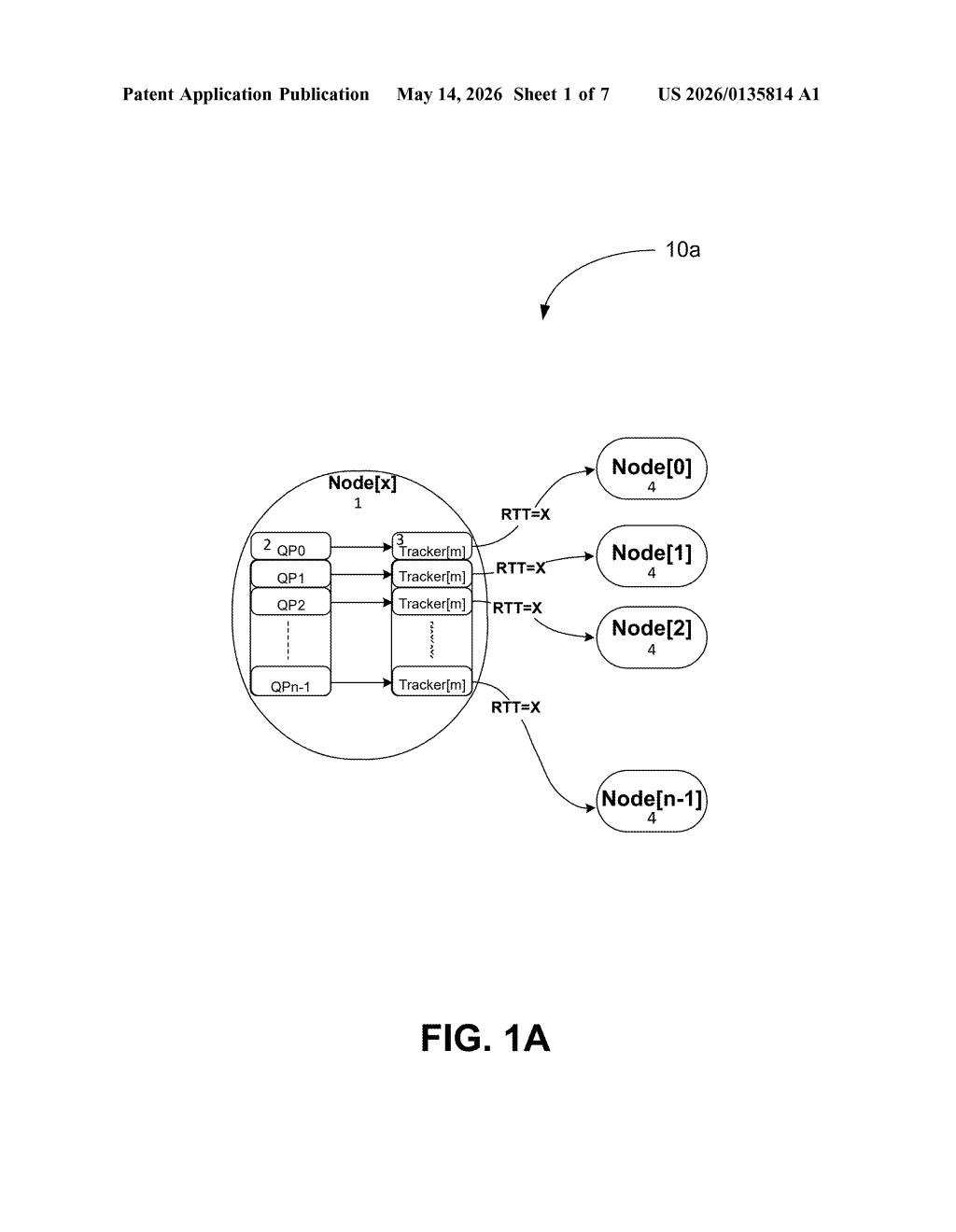
How Meta's RTT-based queue assignment fights slowdowns
Imagine a highway where some on-ramps are backed up while others are totally clear. Instead of building new roads, you open extra lanes only where traffic is already jammed. That's roughly what Meta is doing here — but inside a data center.
In networking, a queue pair (QP) is basically a dedicated channel for sending and receiving data between two machines. Meta's system watches the round-trip time (RTT) — the ping time — between nodes in a data center. If a node's RTT climbs above a set threshold, it gets assigned extra QPs to help move data more efficiently. Nodes with healthy, low latency only get one QP.
The system also keeps watching over time. If conditions change — say, a congested node clears up or a new bottleneck appears — it automatically reallocates those queue pairs. No manual tuning required.
How queue pairs get assigned and reallocated over time
The patent describes a load balance module that collects RTT measurements across all nodes in a data center. RTT (round-trip time) is the time it takes for a packet to travel from one machine to another and back — a reliable proxy for congestion or distance-related slowness.
The core logic works like this:
- Each node starts with one queue pair — the baseline channel for data transfer.
- If a node's RTT exceeds a threshold (which can be the system-wide average RTT or any configured value), it gets assigned additional queue pairs.
- Those extra QPs represent what the patent calls a "nominal block of transfer resources" — essentially a reserved bundle of bandwidth capacity between the slow node and its peers.
- The system continuously or periodically re-monitors RTTs, and if conditions shift significantly, it reallocates QPs accordingly.
This is particularly relevant for RDMA (Remote Direct Memory Access) workloads, which are common in AI training clusters where GPUs need to move huge amounts of model weights between servers with minimal CPU involvement. QP management is a known pain point in those environments because RDMA connections are stateful — you can't just spin up new ones instantly.
The patent's novelty appears to be in the adaptive, RTT-driven assignment policy rather than in any new hardware.
What this means for Meta's AI and hyperscale data centers
Meta operates some of the largest AI training clusters in the world, and at that scale, network congestion between GPUs can stall an entire training job. A system that automatically allocates more data channels to struggling nodes — and pulls them back when they're no longer needed — could meaningfully improve utilization without over-provisioning resources everywhere by default.
For you as a user, the impact is indirect: faster, more efficient training infrastructure could mean quicker iteration on Meta's AI models (Llama, etc.) and smoother performance on services like Instagram and Facebook during peak load. It's also a sign that Meta is investing heavily in the software-defined networking layer that sits beneath its hardware — a space where Google and Amazon have been active for years.
This is unglamorous but genuinely useful infrastructure work. Dynamic QP allocation based on real-time RTT is the kind of optimization that probably already exists in ad-hoc forms inside large data centers — Meta is formalizing and automating it. It won't make headlines, but in a world where AI training runs cost millions of dollars, shaving congestion-related stalls is real money.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.