Nvidia Patents AI Models That Watch and Control Interactive Applications
Nvidia is building AI models that don't just see what's happening on screen — they predict what to do next. This patent describes a training pipeline for so-called vision-language-action models tuned specifically for interactive applications like games.
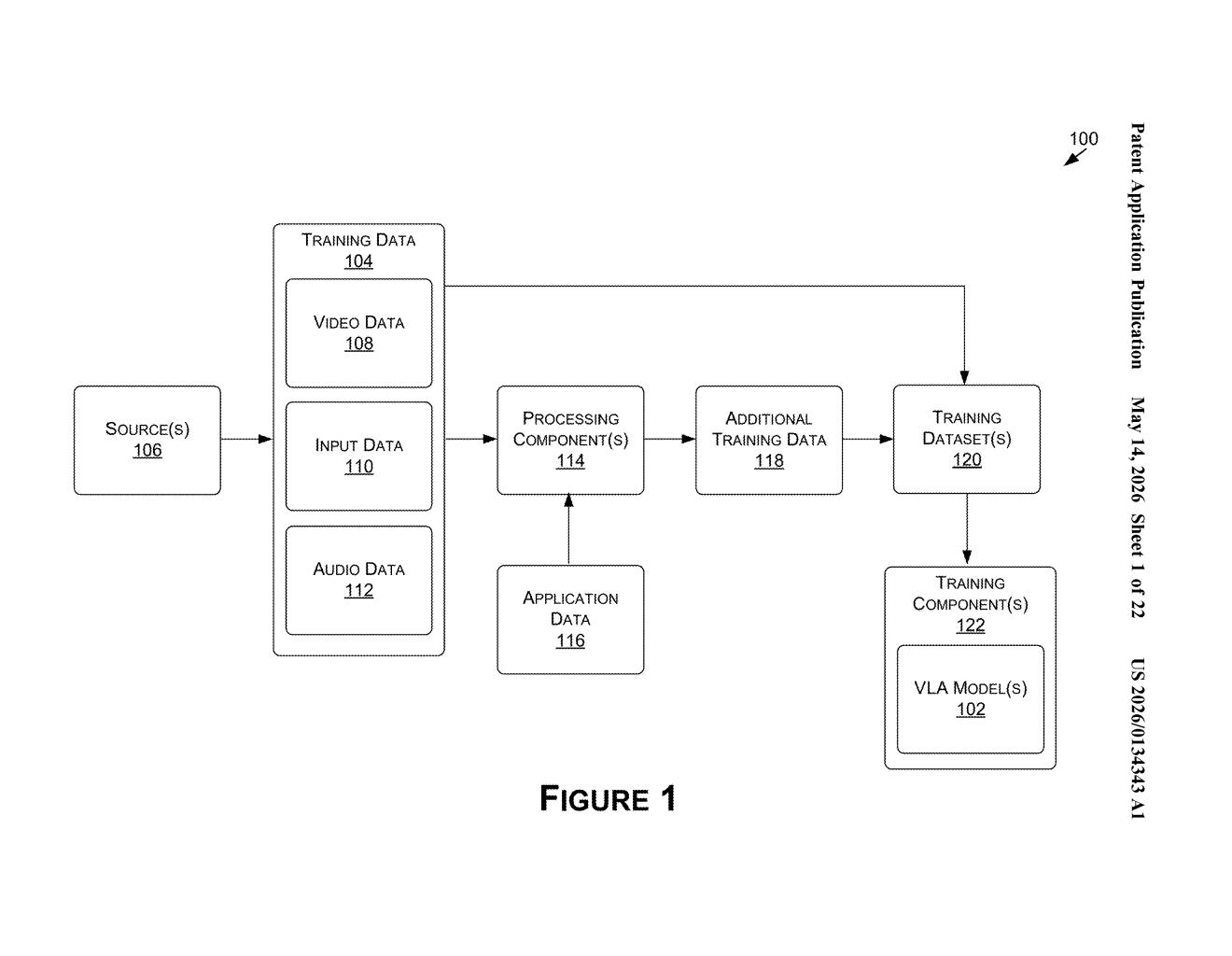
How Nvidia's VLA model watches apps and acts on them
Imagine an AI that can watch someone play a video game, read on-screen text, track every button press, and then learn to play that game itself — not from hand-coded rules, but from observing thousands of hours of real gameplay.
That's roughly what Nvidia is patenting here. The system scrapes training data from sources like game streaming services and app platforms — grabbing video frames, player inputs, audio, and in-game text — then feeds all of it into a machine learning model called a vision-language-action (VLA) model. The model learns to look at what's on screen and predict what instruction or action should come next.
Once trained, you'd essentially have an AI that can autonomously operate an interactive application by watching it unfold in real time. Think of it less like a chatbot and more like an AI co-pilot that understands both what it sees and what it should do about it.
How the VLA model trains on video, inputs, and instructions
The patent describes a two-stage system: a data collection pipeline and a training pipeline.
On the data side, the system pulls together multiple modalities from application and content-sharing services:
- Video frames — what the screen looks like at any given moment
- Input data — the actual actions a human took (keystrokes, controller inputs, mouse clicks)
- Audio data — in-game sound or narration
- Application data — metadata or state information from the app itself
These are combined into a unified training dataset and fed into one or more vision-language-action (VLA) models — a class of model that bridges computer vision (seeing), natural language understanding (reading text and context), and action prediction (deciding what to do).
The core training loop in the first independent claim is straightforward: the model looks at a set of frames plus any prior inputs or instructions, predicts what instruction should come next, and that prediction is compared against ground truth instructions (i.e., what a human actually did). The model's parameters are then updated based on the error — standard supervised learning, but applied to a rich, multi-modal interactive context.
After training, the model can take live video frames and prior context as input and generate instructions for the application to execute in real time.
What this means for AI agents in games and software
For gaming specifically, this is a meaningful step toward AI agents that can actually play complex modern games without needing hand-authored behavior trees or game-engine hooks. If Nvidia can train these models from streaming data at scale, the same infrastructure that powers GeForce Now could also generate the training corpus — a notable vertical integration play.
More broadly, a generalizable VLA model trained on interactive applications could power automated software testing, AI-driven NPCs, or general-purpose computer-use agents. The fact that the training data comes from content-sharing services (think Twitch or YouTube Gaming) means Nvidia could theoretically train across thousands of different games and apps without needing special developer access to any of them.
This is a serious research patent, not a defensive filing. Nvidia has the GPU infrastructure, the streaming platform relationships via GeForce Now, and the AI talent (the inventors include researchers from Nvidia's applied deep learning group) to actually build this. The VLA framing puts it squarely in the same territory as Google DeepMind's work on generalist agents — and Nvidia clearly wants a seat at that table.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.