Nvidia Patents a GPU Memory Error Isolation System for Parallel Workloads
One bad memory cell on a GPU shouldn't crash every workload sharing that chip — but without careful fault isolation, it can. Nvidia is patenting a way to catch that error early, quarantine the offending partition, and let everything else keep running.
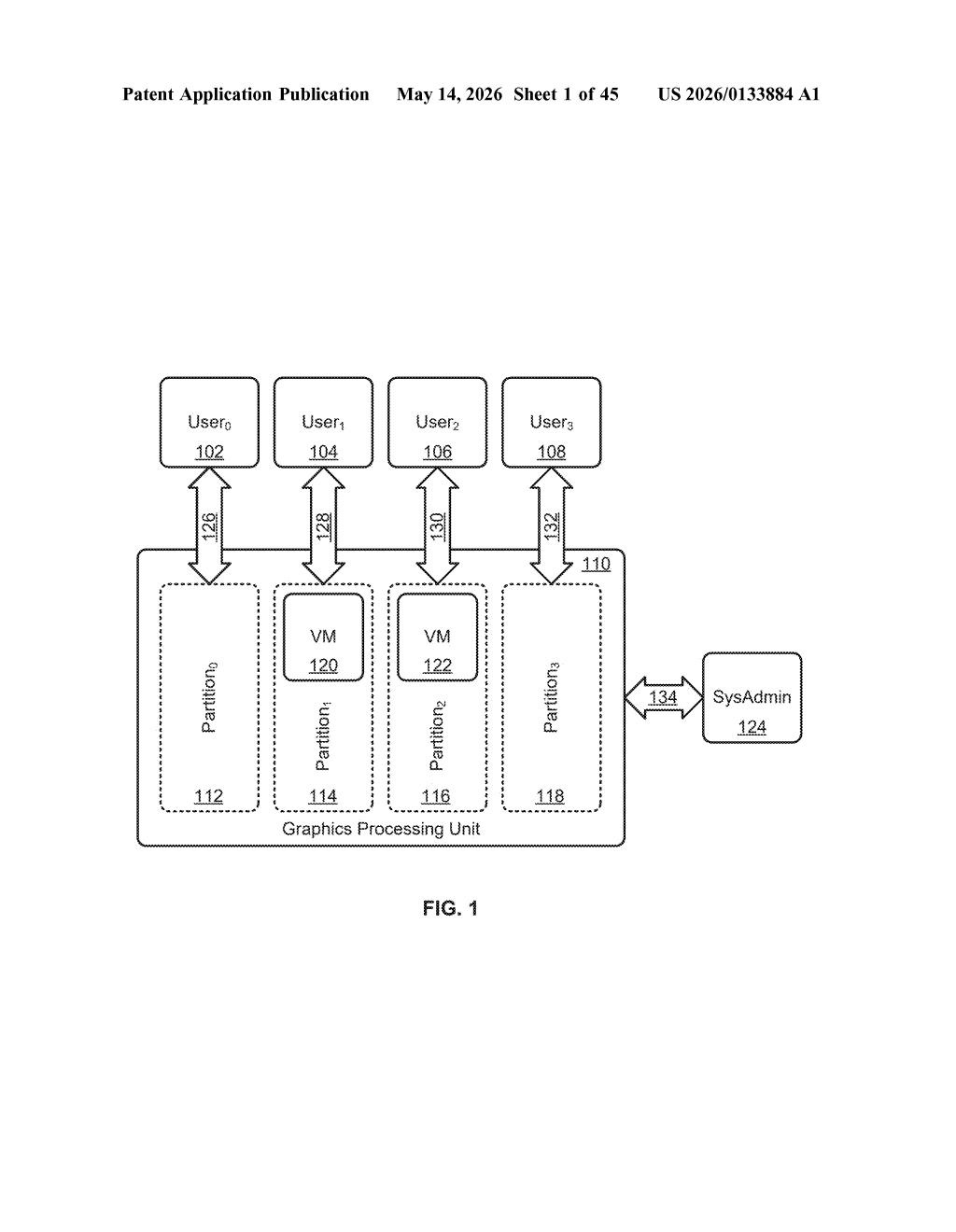
How Nvidia keeps a GPU memory glitch from taking everything down
Imagine a busy office building where one tenant's gas leak forces an evacuation of the entire building, even though everyone else was perfectly fine. Modern GPUs face a similar problem: when a memory error appears in one corner of the chip, it can ripple out and corrupt or crash other programs sharing that same hardware.
Nvidia's new patent describes a system that acts like a smart fire door. When a memory error is detected — say, a bit flips in a specific physical memory address — the system stores a marker at that bad location, watches to see which software program tries to touch it, and then isolates just that program rather than letting the error spread.
The whole mechanism works through GPU-level interrupts (hardware signals that say "something went wrong") and a policy engine that decides what to do next. Other workloads on the same GPU keep running, untouched.
How the error handler detects, stores, and quarantines bad memory
The patent describes hardware circuitry and software hooks that work together inside a GPU to contain memory faults at the partition level. At its core, the system has three jobs:
- Detect the error — the circuitry monitors one or more GPU slices (independent subdivisions of the GPU's compute and memory resources) for errors in physical memory locations.
- Poison the location — rather than immediately alerting every process, the system writes an error value (sometimes called a "poison" marker in memory-fault literature) into the bad address. This is a deliberate sentinel that says "reading this data is unsafe."
- Intercept and isolate — when any software program running on a GPU slice actually reads that poisoned address, an error handler intercepts the access and isolates that specific program, preventing the fault from propagating to other partitions.
The API layer referenced is CUDA (Nvidia's parallel-computing platform), which means this mechanism slots into the existing developer ecosystem rather than requiring new programming models. Interrupts — hardware signals that pause normal execution and hand control to an error handler — are intercepted and processed at the GPU level before the host CPU has to get involved.
The patent also mentions the ability to migrate partitions, suggesting workloads could potentially be moved off a degraded memory region rather than just killed outright.
What this means for multi-tenant GPU and datacenter reliability
In a datacenter where dozens of AI training jobs or inference workloads share a single high-end GPU (a configuration called multi-instance GPU, or MIG, which Nvidia already ships), a single memory fault without this kind of isolation could mean one customer's job corrupting another's — or forcing a full GPU reset that drops every tenant simultaneously. That's a real operational cost, and cloud providers running Nvidia hardware at scale care about it deeply.
For you as a developer or ops engineer, this patent points toward GPUs that behave more like fault-tolerant servers — where hardware errors are events to manage gracefully, not catastrophes that require rebooting the whole machine. That's particularly meaningful as GPU memory capacities grow and error rates become a statistical reality at scale.
This is unglamorous but genuinely important infrastructure work. Memory error isolation is a solved problem on enterprise CPUs and has been for decades — the fact that Nvidia is formalizing it for GPUs at the partition level signals that they're treating datacenter-grade reliability as a first-class design goal, not an afterthought. If this ships in a future CUDA or driver update, SREs running GPU clusters will notice.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.