Google Patents a Way to Train AI Models to Survive Hardware Failures
What if your AI model didn't crash when a chip failed — it just quietly worked around it? Google is patenting exactly that: a training technique that teaches models to keep performing even when the hardware underneath them breaks.
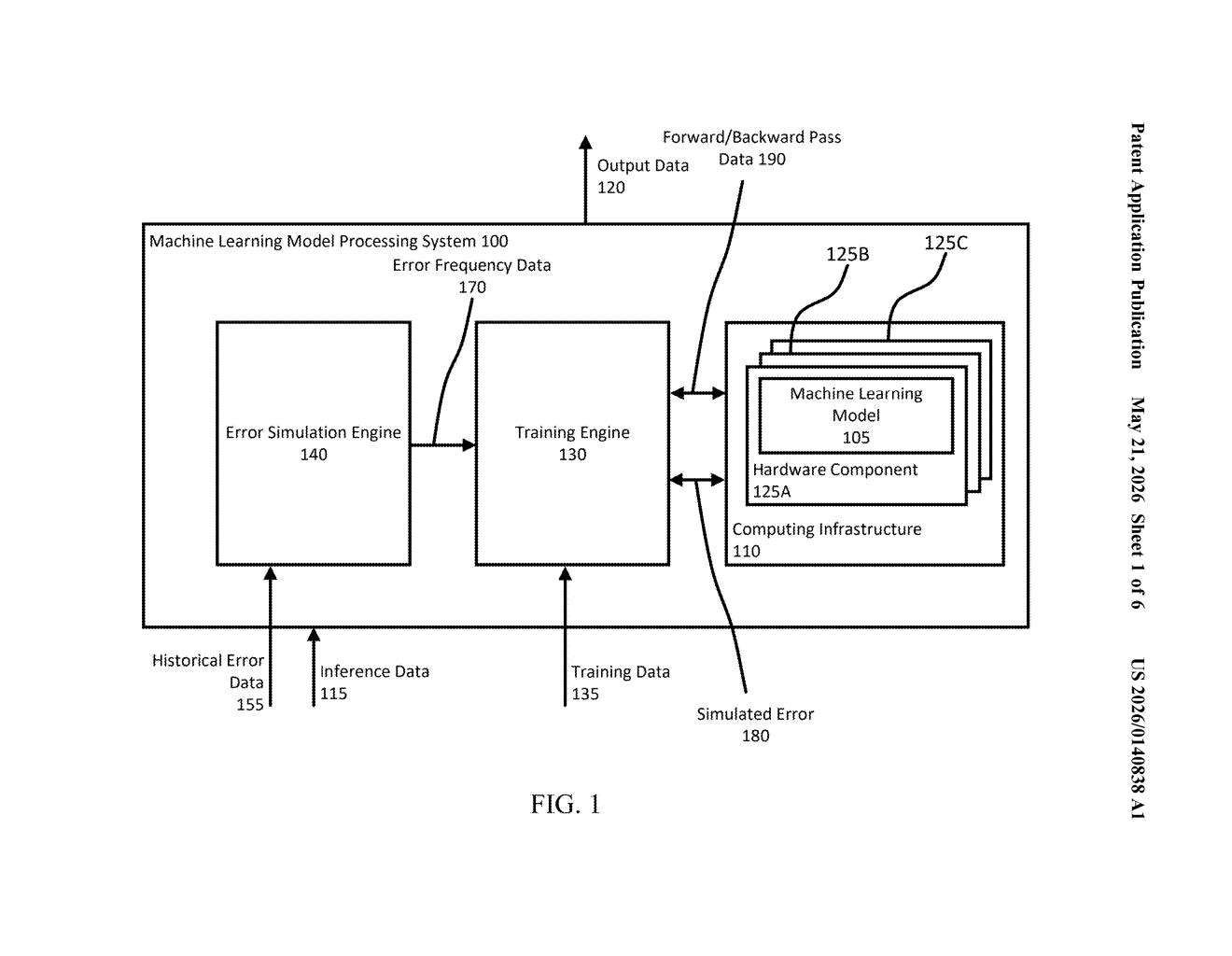
What Google's error-resilient AI training actually does
Imagine a flight simulator that deliberately throws engine failures at trainee pilots so they know how to handle the real thing. Google's patent applies the same logic to AI models running in datacenters.
Right now, when a hardware component fails inside a massive server farm — say, a memory chip or a processor core — the AI model running on it can produce garbage outputs or crash entirely. The conventional fix is to detect and repair the hardware, which is slow and expensive. Google's approach is different: train the model ahead of time to expect those failures and compensate for them automatically.
During training, simulated hardware errors are injected into the process. The model learns to still reach accurate answers even when parts of its compute infrastructure go dark. Think of it like teaching a musician to play a song even if a few keys on the piano stop working.
How Google simulates hardware faults during model training
The patent describes a training pipeline where real-world component error data — logs of actual hardware faults from datacenter infrastructure — is collected over a network and used to generate errored training data. That corrupted data is then fed into the model's normal training loop.
The key mechanism is that error simulation happens during both the forward pass (when the model makes a prediction) and the backward pass (when it updates its weights via backpropagation — the standard process where errors flow backward through the network to adjust how it learns). By seeing failures during both phases, the model builds in resilience at a fundamental level, not just as a post-hoc patch.
The patent also addresses scenarios where not all parts of the model are available at inference time — meaning some components may be offline when the model is actually serving requests in production. The model is specifically trained to compensate for those partial-availability windows.
- Collect real hardware fault logs from deployed infrastructure
- Generate synthetic errored training data that mirrors those faults
- Train the model to maintain accuracy under those simulated conditions
- Use backpropagation to reinforce error-handling behavior across the network
What this means for AI reliability in Google's datacenters
Datacenter hardware fails constantly at scale — Google operates some of the largest AI compute clusters on the planet, and even small failure rates across millions of chips add up fast. Today, the answer is redundancy (keep spare hardware ready) or fault detection (catch the error and reroute). Both approaches cost time, money, and engineering complexity. Training the model itself to be fault-tolerant flips that burden from infrastructure teams to the training process, which happens once rather than continuously in production.
For users, this could translate to more consistent AI service reliability — fewer silent quality degradations or unexpected errors when you're using a Google product powered by one of these models. For Google's competitors running large-scale inference, it signals a shift toward hardware-aware model design as a first-class engineering concern, not an afterthought.
This is genuinely clever engineering philosophy — instead of fighting hardware entropy, you make the model embrace it. It's especially relevant as AI inference scales to massive, heterogeneous clusters where perfect hardware uptime is a fantasy. The single-inventor filing and relatively narrow first claim suggest this is an early-stage idea, but the direction is sound and practically motivated.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.