Nvidia Patents an Automatic Precision Selector for Neural Network Layers
Every layer of a neural network doesn't need the same level of numeric precision — but figuring out which layers can tolerate less has always been tedious manual work. Nvidia is filing a patent to automate that decision.
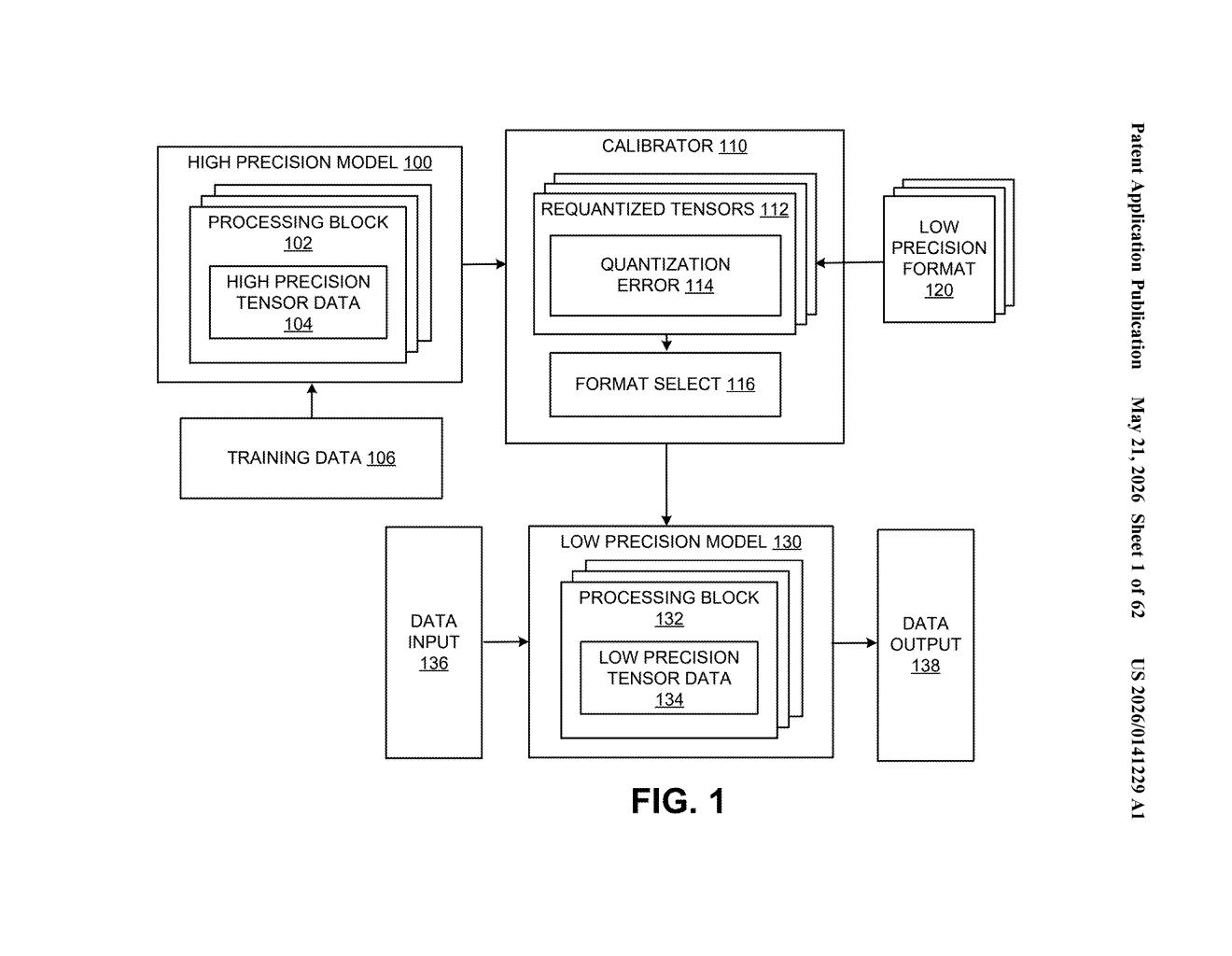
What Nvidia's auto-precision system actually does
Imagine you're packing a suitcase and you realize you can roll some clothes tightly and fold others flat — but doing it wrong means wrinkles everywhere. Neural networks face a similar tradeoff: storing numbers at lower precision saves memory and speeds things up, but go too far and the model makes worse predictions.
Nvidia's patent describes a system that automatically tests different low-precision numeric formats on each layer of a neural network and picks the best fit based on how much accuracy you lose. Instead of an engineer manually tuning each layer, the processor does the evaluation itself.
This kind of automatic quantization is a big deal for deploying AI models on GPUs, edge devices, or data center hardware where every bit of memory and compute matters. It's the difference between a model that runs fast and stays accurate versus one that forces you to choose.
How the quantization error score drives format selection
The patent describes a processor — likely a GPU or dedicated AI accelerator — equipped with circuits that measure the accuracy impact of quantizing (compressing) the weights and tensor data within individual layers or groups of layers in a neural network.
Quantization is the process of representing floating-point numbers (like 32-bit or 16-bit floats) using fewer bits — say, 8-bit integers or even 4-bit formats. It shrinks model size and speeds up inference, but introduces quantization error (a measure of how far the compressed numbers stray from their original values). The trick is knowing which layers can tolerate more error and which can't.
The system works by:
- Running tensor data from each neural network layer through multiple low-precision encoding formats
- Measuring the quantization error produced by each format
- Selecting the preferred format based on which format minimizes accuracy loss
This selection can happen either during training or after training (post-training quantization), giving it flexibility across different deployment workflows. The goal is to automate what AI engineers currently do by hand — a labor-intensive process of profiling, testing, and tuning precision settings across potentially hundreds of layers.
What this means for AI inference speed and model size
For anyone building or running large AI models, compute efficiency is the central cost problem. Mixed-precision inference — using different numeric formats in different parts of a model — is already a known technique, but automating the format selection removes a major engineering bottleneck. This is especially relevant as models get larger and more heterogeneous.
For Nvidia specifically, this capability embedded in silicon or in the CUDA/TensorRT stack could make its GPUs even more attractive for inference workloads, where competitors like AMD and custom TPUs are aggressively competing. If your hardware automatically picks the best precision per layer without manual intervention, that's a meaningful operational advantage for anyone running models at scale.
This is a solid, practical patent aimed squarely at inference efficiency — not a moonshot. Automated quantization selection is already a pain point that every serious ML deployment team has dealt with, and baking it into the processor level is the logical next step for Nvidia as it pushes deeper into inference-optimized hardware. Don't expect a product announcement, but do expect this to quietly show up in a future TensorRT or Hopper/Blackwell feature set.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.