Nvidia Patents a GPU Method for Splitting Tensor Operations into Parallel Paths
Tensor operations are the heartbeat of modern AI — but certain flavors, like the ones used in physics-aware neural networks, are notoriously hard to parallelize efficiently. Nvidia's new patent describes a structured way to slice those operations into smaller, GPU-friendly chunks and compute them all at once.
How Nvidia's segmented tensor trick speeds up GPU math
Imagine you're trying to multiply two enormous tables of numbers together, but the math rules connecting them are irregular — some cells feed into many outputs, others into just one. On a normal GPU, that irregularity causes bottlenecks because the hardware thrives on doing the same operation thousands of times in lockstep.
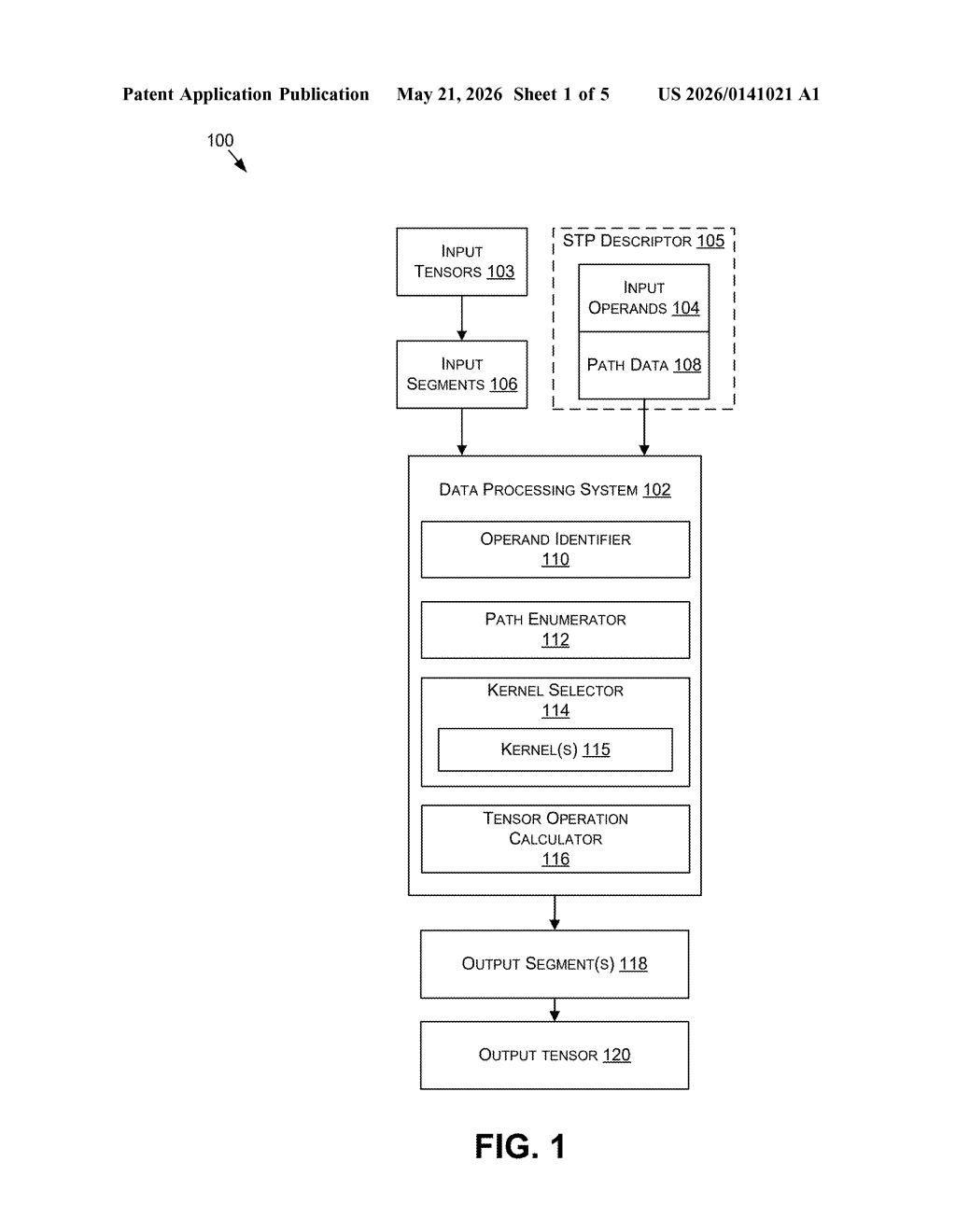
Nvidia's approach here is to break each input (called an operand) into smaller pieces called segments, and then define explicit paths — each path says 'take this piece from operand A, this piece from operand B, multiply by these coefficients, and produce a partial result.' Thousands of those paths run in parallel on the GPU.
The final output tensor is assembled from all those partial results. It's a divide-and-conquer strategy that maps messy, irregular tensor math onto the grid-like structure that GPUs love. The patent also describes a kernel selector that picks the best GPU code routine for each specific combination of segments and coefficients.
How the path-and-segment pipeline breaks down tensor ops
The patent centers on tensor products — specifically the kind used in equivariant neural networks (models designed to respect physical symmetries, popular in molecular dynamics, protein folding, and materials science simulations). These operations involve multiplying multi-dimensional arrays where each element can interact with many others through a set of Clebsch-Gordan coefficients (a fixed set of weights derived from group theory that describe how different 'angular momentum channels' combine).
The system works in four steps:
- Operand identification: The circuit identifies the input tensors and partitions each one into segments — logical sub-blocks defined by channel type or size.
- Path enumeration: A path enumerator generates all valid combinations of one segment from each operand plus the relevant coefficient set. Each path is an independent unit of work.
- Parallel kernel execution: A kernel selector chooses the optimal GPU kernel (a compiled GPU function) for each path and launches them. Each kernel computes a partial output tensor — the result of that one path's math.
- Output assembly: The partial outputs are combined (typically by summation) into the final output tensor.
The segmentation means the GPU's thread blocks can be assigned to paths cleanly, avoiding the load-imbalance that plagues naive implementations of irregular sparse tensor contractions.
What this means for physics-ML and molecular simulation workloads
Equivariant neural networks — the main consumer of this kind of tensor math — are a big deal in scientific AI. Models like NequIP, MACE, and SE(3)-Transformers use exactly these Clebsch-Gordan tensor products to simulate how atoms interact. Right now, those operations are often a severe GPU bottleneck that limits how large or fast those models can run.
If Nvidia ships this as part of its CUDA libraries or a framework like cuEquivariance (which Nvidia has already been developing publicly), it could meaningfully accelerate drug discovery, materials design, and climate modeling workloads — the kinds of jobs increasingly running on Nvidia's data center hardware. For you as a researcher or engineer, it means faster iteration on physics-ML models without custom kernel hacks.
This is genuinely useful infrastructure work, not a flashy AI headline. Equivariant tensor products are a real pain point in scientific ML, and a hardware-aware segmentation scheme from the people who make the GPUs is exactly the kind of low-level optimization the field needs. The patent's timing — alongside Nvidia's public cuEquivariance library work — suggests this is headed toward a real product, not a shelf filing.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.