Adobe Patents a Parallel-Batching Fix for LLM Context Window Overflow
Every LLM has a context window — a hard cap on how much text it can read at once. Adobe's new patent attacks that limit head-on by splitting your reference examples into parallel batches and letting the model process them simultaneously.
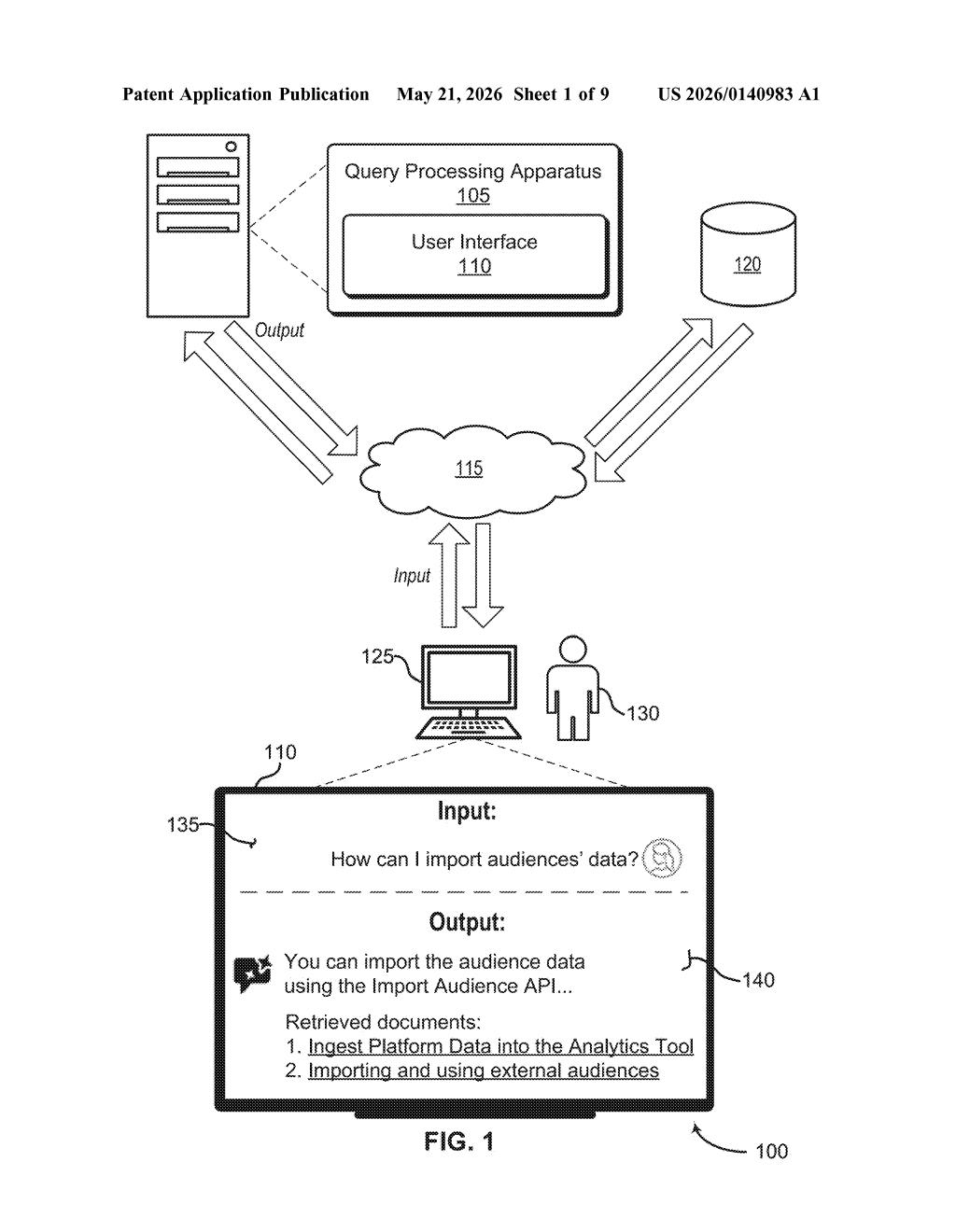
How Adobe squeezes more examples into an LLM prompt
Imagine you're using an AI assistant inside Adobe's software and you ask it a question. The AI wants to pull in a bunch of helpful examples — past documents, usage guides, similar queries — to give you a better answer. But there's a catch: the model can only "see" so much text at once, like trying to read a novel through a mail slot.
Adobe's patent describes a way around that wall. Instead of cramming everything into one oversized prompt (which would crash the context limit) or throwing away examples to make things fit, the system splits the examples into smaller batches. Each batch gets the same user question attached to it, and the model processes all of them at the same time.
The results from each batch are then combined into a single answer. You get the benefit of all those context examples — not just the ones that happened to fit — without the model ever seeing more than it can handle at once.
How the sub-batching component splits and merges inputs
The core idea is context example batching: when the total set of reference examples for a query is too large to fit inside the model's context window, a sub-batching component divides them into smaller groups. Each group is paired with the original user query to form a separate input.
Those inputs are then fed to the language generation model in parallel, using the model's own attention mechanism (the neural-network layer that decides which parts of the input to focus on). Processing happens simultaneously rather than sequentially, which keeps latency from multiplying as the number of batches grows.
The key technical claim is that the model generates a response "based on" both inputs together — meaning there's an aggregation or synthesis step that merges the parallel outputs into one coherent answer. The patent doesn't spell out exactly how that merging works, but the claim structure implies the final response accounts for evidence from every batch, not just the first one to finish.
- Sub-batching component: splits context examples when their combined size exceeds the window limit
- Parallel processing: both batched inputs run through the model at the same time
- Response synthesis: outputs from all batches are combined into a single answer for the user
What this means for AI tools built on retrieval and few-shot prompting
Context window size is one of the biggest practical constraints in deploying LLM-powered features inside enterprise software. If you're building a tool like Adobe's AI Assistant in Acrobat — which needs to reference long documents, style guides, and past examples simultaneously — you're constantly fighting the window limit. This patent describes a systematic way to route around it without waiting for the next generation of models with bigger windows.
For you as an end user, this would mean an AI assistant that gives you answers grounded in more of your actual content, rather than silently ignoring chunks that didn't fit. That's a meaningful quality improvement in document Q&A, content generation, and any workflow where historical examples improve output accuracy.
This is solid, unglamorous infrastructure work — the kind of optimization that makes AI features actually usable in production rather than just impressive in demos. Context window management is a real engineering headache, and parallel batching is a sensible approach. It's not a conceptual leap, but it is exactly the kind of patent you'd expect from a company that ships LLM features inside tools millions of people use for serious work.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.