Adobe Patents a System That Invents Fake Users to Train Its AI Assistants
Training an AI assistant requires thousands of example conversations, but real user data is hard to collect and raises privacy concerns. Adobe's answer: make the users up.
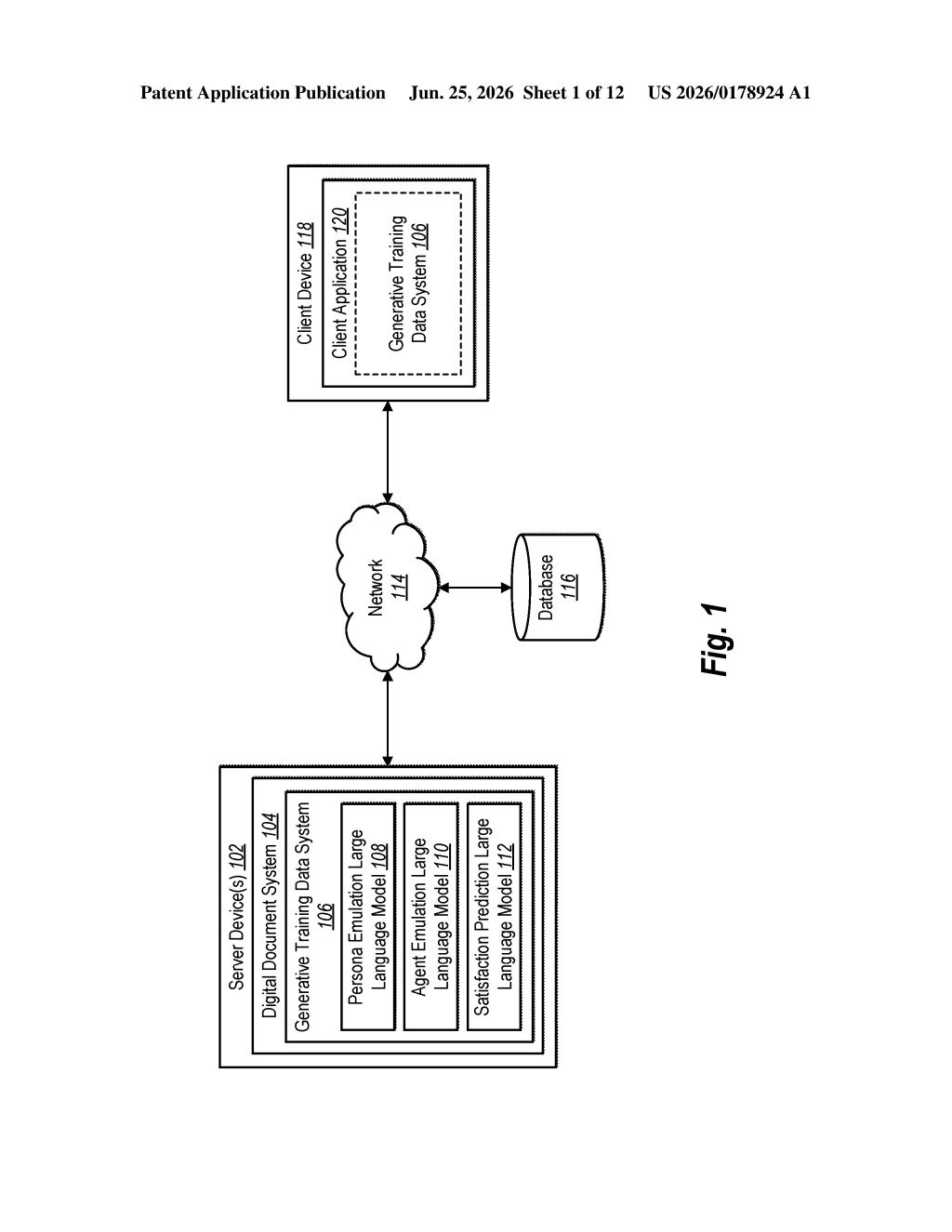
What Adobe's synthetic-persona training system actually does
Imagine you want to teach a customer-service bot how to answer questions about a 50-page contract. Ideally, you'd watch hundreds of real people read that contract and ask questions. But collecting that data takes time, costs money, and means storing sensitive conversations. Adobe's patent describes a shortcut.
The system creates a fictional user, complete with invented background details, then uses an AI to read a real document and write the kinds of questions that persona would plausibly ask. A second AI then writes the answer, as if it were a helpful assistant. The result is a synthetic back-and-forth conversation that can be used to train a third AI.
In plain terms: Adobe is using AI to generate the training examples that teach other AI how to behave. The whole loop stays grounded in actual documents, like PDFs or contracts, so the made-up conversations still reflect real-world content rather than pure fiction.
How Adobe builds fake conversations from real documents
The patent describes a four-step pipeline for generating document-grounded training data without needing real users.
- Persona creation: The system picks a set of characteristics to define a synthetic (fictional) user, things like job role, expertise level, or goal. This shapes what kind of questions that persona would realistically ask.
- Prompt generation: A first large language model (LLM) reads an actual digital document tied to that persona and writes a synthetic prompt, essentially inventing the question the persona would type.
- Response generation: A second LLM reads that synthetic prompt and generates a synthetic response, playing the role of an AI assistant answering the question.
- Model training: The prompt-response pair is fed into a neural network as training data, adjusting the network's parameters so it learns to produce that style of response.
Using two separate LLMs, one for the user side and one for the assistant side, keeps the roles distinct and reduces the risk of the system collapsing into a single voice talking to itself. The document anchor is the key design choice: by forcing the question-generating LLM to work from a real file, Adobe ensures the fake conversations stay relevant to actual content rather than drifting into generic chat.
What this means for Adobe's document-based AI tools
Adobe's core products, Acrobat, Document Cloud, and its AI Assistant feature, all involve users querying or summarizing documents. Building a well-trained AI for that job normally requires enormous volumes of real question-and-answer pairs collected from actual users. That's slow, expensive, and raises privacy questions about who gets to see those interactions.
A system that manufactures its own training data from documents directly could let Adobe fine-tune AI assistants faster and with less reliance on user data. For you as a user, a better-trained document assistant means more accurate summaries and answers when you ask Acrobat to explain a clause or find a figure buried in a report.
This is a genuinely practical patent, not a flashy one. The underlying idea (use LLMs to bootstrap training data for other LLMs) is a well-known technique in the AI research community, and Adobe is essentially formalizing an application of it for document-focused assistants. The real value is operational: it gives Adobe a cleaner, faster pipeline for improving its AI tools without accumulating sensitive user data. Worth tracking, but don't expect a splashy announcement.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.