Google Patents a Compound Scaling Method for Neural Network Architecture
Building a bigger neural network isn't just about making it deeper — Google's patent describes a principled way to scale three separate dimensions of a network at once, using a single tunable coefficient to divide up extra compute budget.
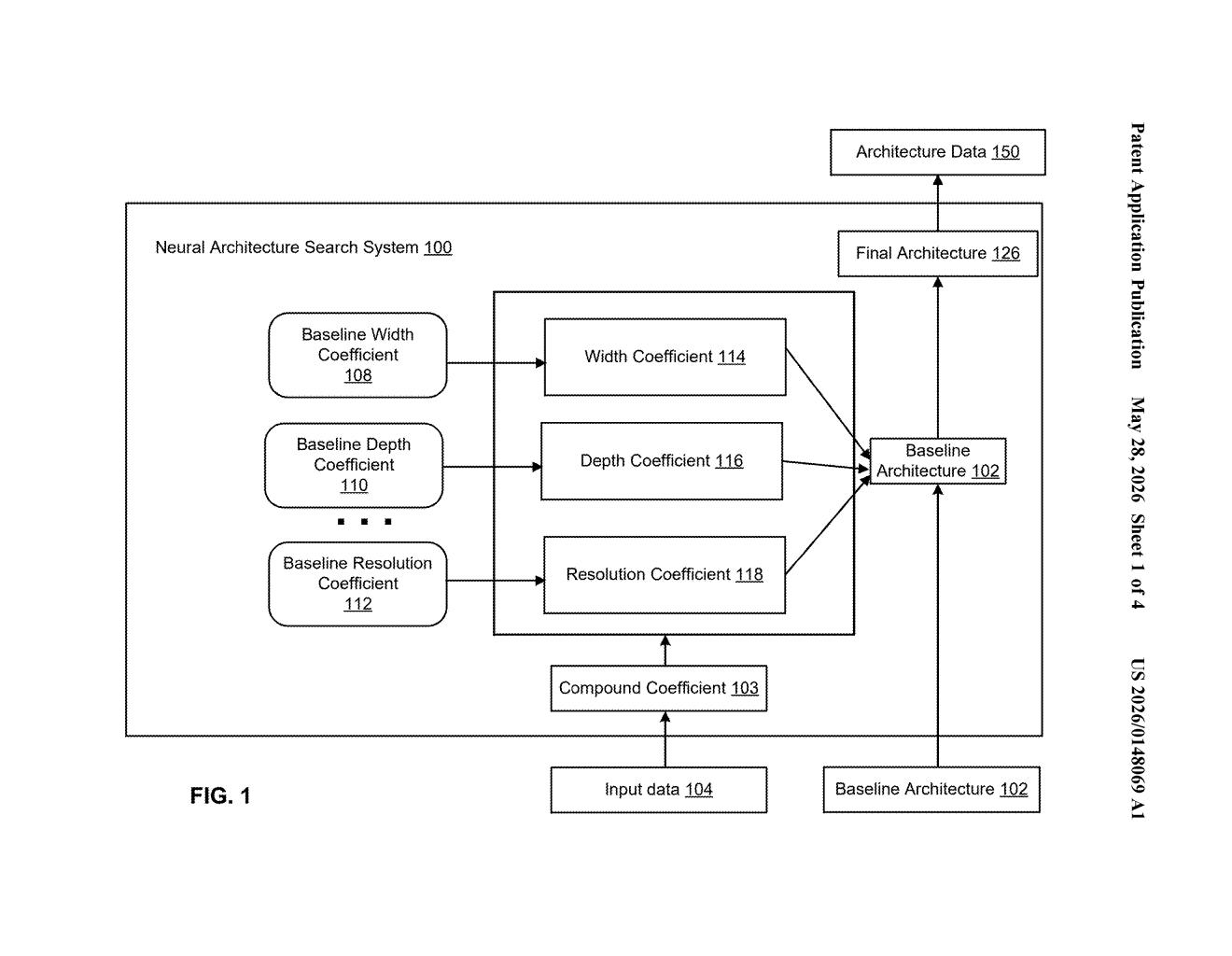
How Google jointly scales width, depth, and resolution
Imagine you're baking a cake and you want to make it bigger. You could make it taller, wider, or use a bigger pan — but doing just one of those usually gives you a lopsided result. Training a neural network has the same problem: you can make it deeper (more layers), wider (more neurons per layer), or feed it higher-resolution images, but cranking just one knob tends to waste resources.
Google's approach, called compound scaling, uses a single number — a "compound coefficient" — to control all three dimensions at the same time. You set how much extra compute you want to spend, and the method figures out the right balance of depth, width, and resolution automatically.
This is the core idea behind the EfficientNet family of models, which became a benchmark for getting strong accuracy without needing a massive amount of compute. This patent is a continuation filing, meaning Google is extending and reinforcing its legal coverage of an idea it originally filed back in 2019.
How the compound coefficient distributes compute across three dimensions
The patent describes a method for finding the final architecture of a neural network given a compute budget. It starts with a baseline architecture — a small, well-behaved model — and then scales it up using three dimensions:
- Network width — how many channels or neurons exist at each layer
- Network depth — how many layers the network has in total
- Input resolution — the size of the images (or other inputs) fed into the network
Rather than scaling these independently, the method performs a search to find baseline coefficients for each dimension — essentially, how much each one should grow relative to the others when compute increases. Once those ratios are fixed, a single compound coefficient (think of it as a "scale dial") uniformly controls how much extra compute gets poured in, and the three dimensions scale together in lockstep.
The result is a family of models at different sizes that all share the same proportional architecture, just magnified. This makes it straightforward to trade accuracy for speed depending on whether you're deploying on a data center GPU or a mobile chip.
What this means for efficient AI model design
This is the foundational IP behind Google's EfficientNet and related efficient model families, which demonstrated that you can match or beat much larger models by scaling architectures more carefully. The method has been widely cited and adapted across the industry, making it one of the more consequential ideas in practical deep learning from the past several years.
For you as a developer or researcher, the broader point is that how you scale a model matters as much as how big you make it. This filing is a continuation patent — the core idea dates to 2019 — so this is Google maintaining and extending its IP position on a technique that's already proven out in production, not announcing something new.
This is a continuation of a well-established, influential patent — not a new idea. Mingxing Tan and Quoc Le's compound scaling work genuinely changed how practitioners think about model efficiency, and Google is right to protect it. But if you're looking for a fresh technical insight here, this filing is more about IP housekeeping than frontier research.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.