Google Patents a Passage-Scoring Filter for Multimodal AI Search
When you ask Google a question using both a photo and some text, how does the AI know which search results are actually relevant to your image? This patent describes Google's answer: a dedicated scoring model that reads your image and the candidate results simultaneously, then filters out the noise before the response generator ever sees them.
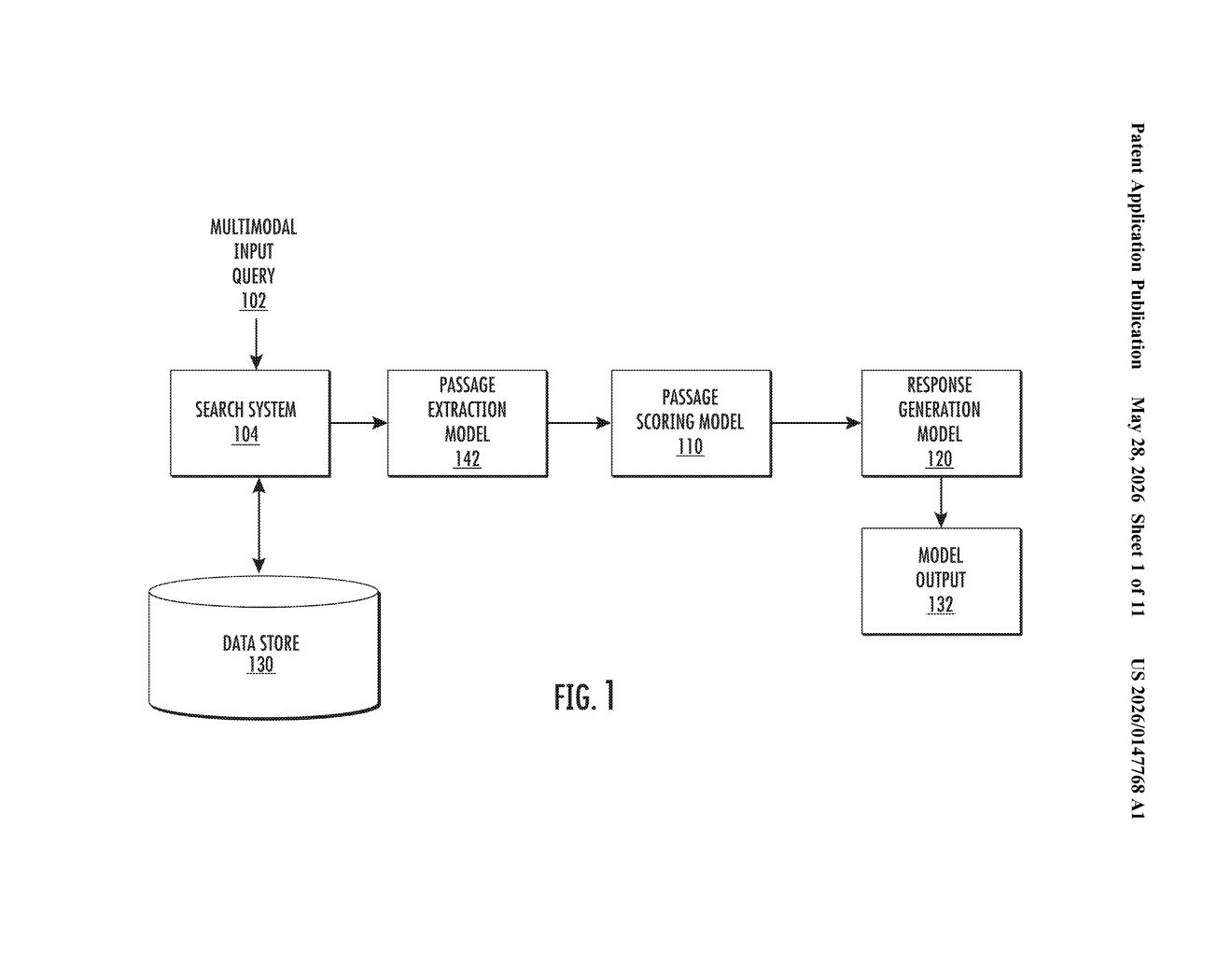
What Google's image-aware search filter actually does
Imagine you snap a photo of a weird rash on your arm and type 'is this serious?' into Google. The search engine might return dozens of results — dermatology guides, forums, product pages — but most of them won't be relevant to your specific image. The challenge is making sure the AI that writes your answer only reads the good stuff.
Google's patent describes a two-stage pipeline to solve exactly that. First, a passage-scoring model looks at both your image and each search result at the same time, giving every result a relevance score. Only the top-scoring results get passed forward.
The filtered shortlist then goes to a separate response generation model — the part that actually writes the natural language answer you see. By keeping these two jobs separate, Google can swap in better scorers or generators independently, and avoid stuffing the response model with irrelevant context that could confuse it or waste compute.
How the passage-scoring model ranks and trims results
The patent describes a pipeline with two distinct machine-learned components working in sequence.
The first is a passage-scoring model — a multimodal model (meaning it handles both images and text, not just one or the other) that takes your full query, including any image content, and simultaneously processes it alongside the text of each candidate search result. It outputs a result score for every result, essentially answering: 'how useful is this passage for answering this specific visual question?'
The second component is the response generation model, which only ever sees the high-scoring subset selected by the scorer. This model generates a natural language answer based on the filtered context. The separation matters: without a pre-filter, a large language model tasked with reading 50 search results might get confused by irrelevant ones, a problem often called context pollution.
Key design choices from the claim language include:
- The scoring model must process image content and textual content simultaneously — not separately then merged
- The subset selection is score-driven, not just positional (it's not simply 'top 5 results')
- The natural language response is generated from a model input that bundles both the original query and the selected passages as context
What this means for Google's AI Overviews pipeline
This patent sits squarely inside the plumbing of AI Overviews — Google's system that generates synthesized answers at the top of search results. One of the known failure modes of retrieval-augmented generation (where an AI reads web content before answering) is that low-quality or off-topic passages can corrupt the final answer. A dedicated multimodal scorer that filters before the generator ever runs is a sensible architectural fix.
For users, the payoff is more accurate AI answers to queries that include images — think reverse image search questions, product identification, visual troubleshooting, or medical photo queries. The broader signal here is that Google is investing in purpose-built filtering infrastructure rather than just prompting a single large model to 'do its best' with raw search results.
This is solid, unglamorous infrastructure work — the kind of thing that rarely makes headlines but quietly determines whether AI search answers are trustworthy or hallucination-prone. The two-stage scorer-then-generator architecture is well-established in research, but patenting a production-grade multimodal version of it tells you where Google is putting engineering effort inside AI Overviews. Worth paying attention to if you care about how retrieval-augmented generation actually gets deployed at scale.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.