Salesforce Patents a Self-Verifying Reasoning Pipeline for Vision-Language AI
Salesforce is teaching AI models to show their work — and only keep the answers where the reasoning actually checks out. The result is a self-cleaning training pipeline for visual question-answering that filters bad logic before it can corrupt the model.
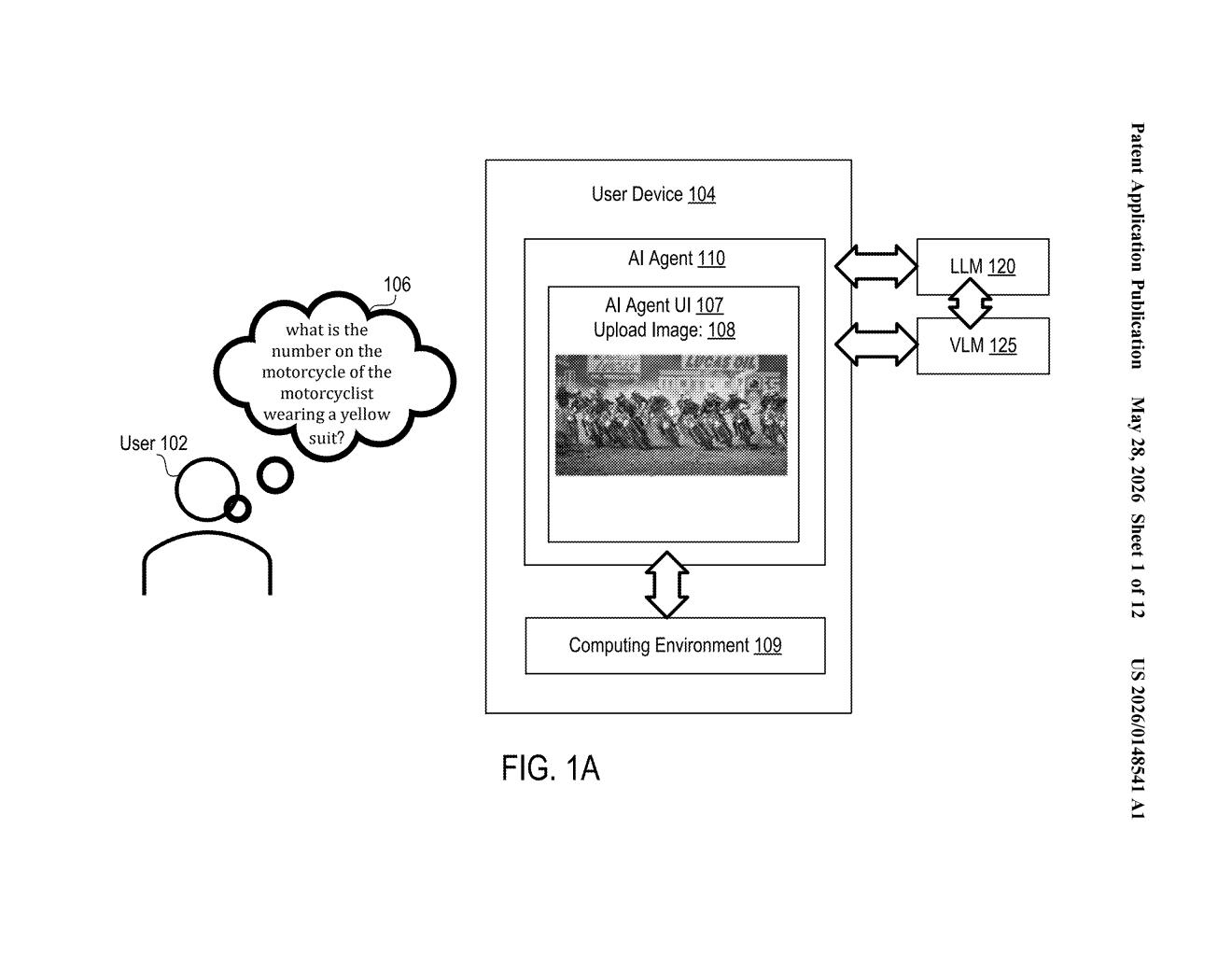
What Salesforce's chain-of-thought vision training actually does
Imagine asking an AI, "What number is on the motorcycle ridden by the person in the yellow suit?" A typical model might just guess. Salesforce's approach forces the model to think out loud first — step by step — before committing to an answer.
The clever part is the verification loop. The model generates a chain of reasoning steps, then uses those steps to try to produce the correct answer. If the answer matches what's known to be right, the reasoning gets kept. If it doesn't, it gets tossed. Only verified reasoning becomes training data.
Over time, the model gets trained on examples where the thinking was demonstrably correct — not just lucky guesses. Salesforce then uses that trained model as the foundation for an AI agent capable of handling complex vision-and-language tasks, like answering detailed questions about images or parsing visual scenes.
How CoTA steps get parsed, verified, and fed back as training data
The patent describes a training framework built around a concept called Chain-of-Thoughts-and-Action (CoTA) — a structured reasoning format where each step is broken into three parts: a thought (what the model is reasoning about), an action (what it decides to do, like crop an image region or run a calculation), and an observation (what it learns from that action).
The pipeline works in stages:
- A multimodal model receives an image, a question, and a known correct answer.
- It generates a CoTA — a sequence of thought/action/observation steps leading toward that answer.
- It then uses the CoTA as additional input context to produce a predicted answer.
- If the predicted answer matches the ground-truth, the CoTA is deemed valid and gets added to the training dataset.
This self-verification step is the key innovation. Rather than assuming generated reasoning is correct, the system empirically tests it by checking whether following the reasoning actually produces the right answer. Faulty chains of logic are discarded automatically.
The verified CoTA data — image, question, answer, and validated reasoning steps — then trains a fresh model, producing an AI agent designed for vision-language tasks that require multi-step inference rather than single-shot guessing.
What this means for AI agents that read images and answer questions
The core problem with training reasoning models at scale is that synthetic reasoning data is often wrong. Models hallucinate plausible-sounding logic that doesn't actually lead to correct answers, and if you train on that noise, you bake the errors in. Salesforce's verification loop is a pragmatic fix: only reasoning that demonstrably works survives into the training set.
For enterprise AI — which is Salesforce's home turf — this matters because visual question-answering over documents, dashboards, and product images is exactly the kind of task CRM and service-cloud customers need. An agent that can look at a chart or a customer photo and reason through a multi-step question reliably is far more useful than one that occasionally guesses right.
This is solid, practical AI research rather than a flashy capability demo. Salesforce isn't claiming to have invented chain-of-thought reasoning — they're building a pipeline that makes it reliable enough to train production models on. Given how much enterprise AI fails on visual reasoning tasks, this kind of unglamorous infrastructure work is exactly what's needed to make multimodal agents actually useful in the real world.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.