Salesforce Patents a System That Trains AI to Catch Its Own Lies
AI systems that confidently state wrong facts are one of the biggest trust problems in enterprise software. Salesforce is patenting a method where one AI deliberately writes bad summaries so another AI can learn to catch the mistakes — before any of it reaches a customer.
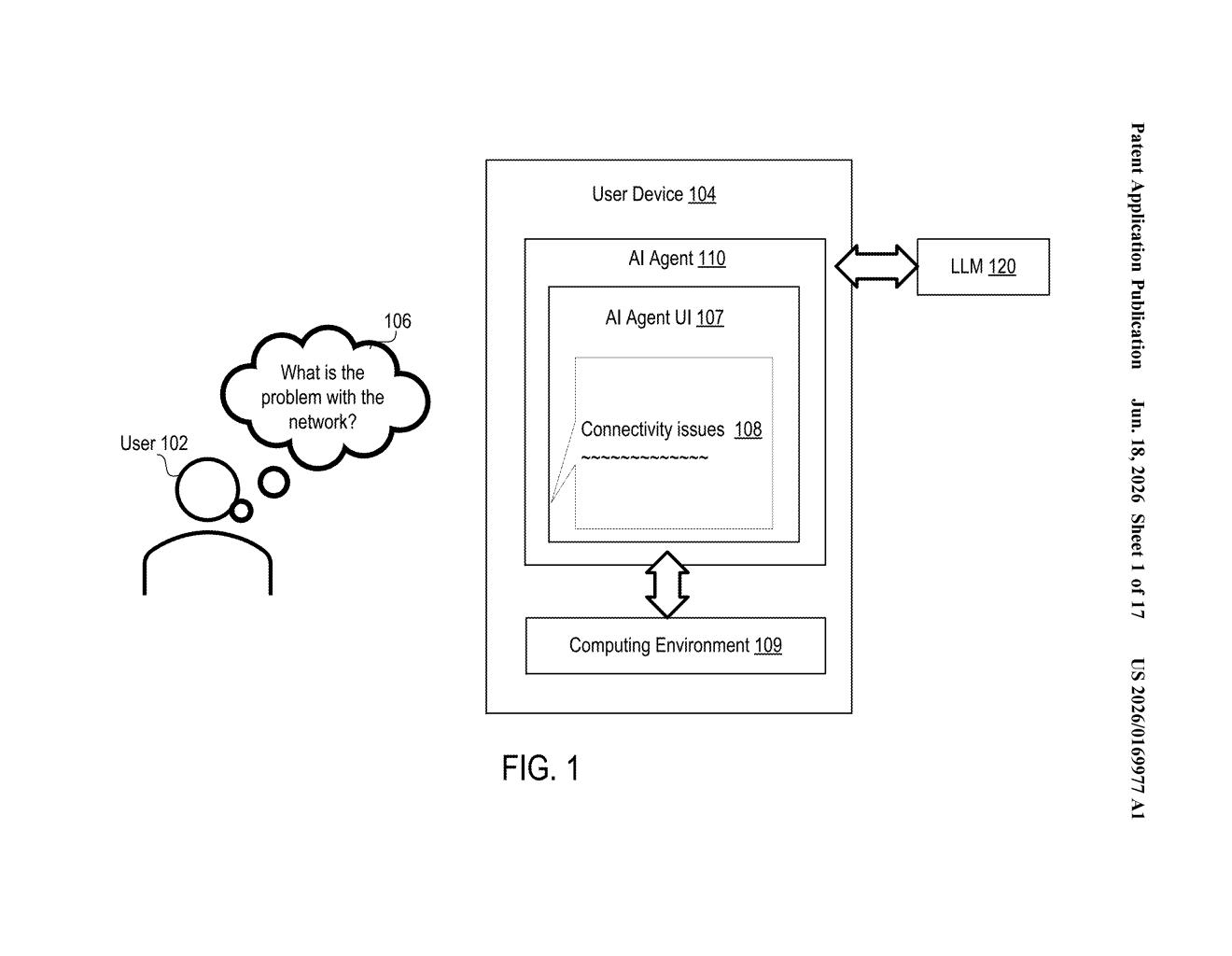
How Salesforce's fact-checking AI trains itself
Imagine your company uses an AI assistant to summarize sales calls or contracts. The AI sounds confident, but it gets a detail wrong — it says a client agreed to a price they never actually confirmed. That kind of quiet error can cost real money.
Salesforce's patent describes a training setup where a first AI is told to deliberately introduce errors into document summaries — swapping out facts, changing names, mixing up numbers. A second AI then reads the original document alongside the flawed summary and has to flag exactly what's wrong and explain why. A third AI grades how good that explanation is.
Only when the fact-checker scores high enough does it get promoted into an actual product. The idea is to produce an AI agent that has been stress-tested against deception it created itself — making it harder to fool with the same kinds of mistakes real AI systems commonly produce.
Inside the three-model pipeline that scores accuracy
The patent describes a three-model pipeline designed to produce an AI agent with strong factual consistency detection.
- Model 1 (the corrupter): Takes real documents and their accurate summaries, then rewrites the summaries to introduce deliberate errors — wrong numbers, swapped entities, fabricated claims — all derived from the source document so the errors are plausible, not random.
- Model 2 (the checker): Receives a document paired with a potentially flawed summary and must detect whether any factual inconsistency exists, then explain what the error is and where it came from.
- Model 3 (the judge): Evaluates the quality of the checker's explanation and assigns an accuracy score. Think of it as an automated grader assessing whether Model 2 understood why something was wrong, not just that it was wrong.
If Model 2's score clears a set threshold, it gets built into the final AI agent. This creates a selection filter: only fact-checkers that can explain their reasoning to a third party's satisfaction make it into production. The approach sidesteps the need for large amounts of human-labeled data about factual errors, which is expensive and slow to produce.
What this means for AI hallucinations in business software
Hallucination — the industry term for an AI stating false information confidently — is one of the main reasons enterprises hesitate to deploy AI in high-stakes workflows like legal document review, financial reporting, or customer contracts. A system that has been specifically trained to detect the kinds of errors AI models actually produce is more useful than a generic accuracy filter.
For Salesforce, whose core business is enterprise software built around customer data and communication records, a deployable fact-checking layer would address a direct sales objection. If this technology ships inside products like Einstein AI, it could give business users more reason to trust AI-generated summaries of deals, support tickets, or emails — which is precisely the use case Salesforce has been building toward.
This is genuinely useful work targeting a real and persistent problem with large language models. The self-generated training data approach — using one AI to create the errors another must learn to catch — is an efficient way to build evaluation capability without drowning in manual annotation. It's not glamorous, but factual consistency is exactly the unglamorous problem that determines whether enterprise AI actually gets used.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.