Google Patents a Voice Tool That Formats Your Words While You Dictate
What if you could say 'type this in all caps: meeting is canceled' and your phone just got it — no extra taps, no mode-switching? That's the core idea in Google's latest voice interface patent.
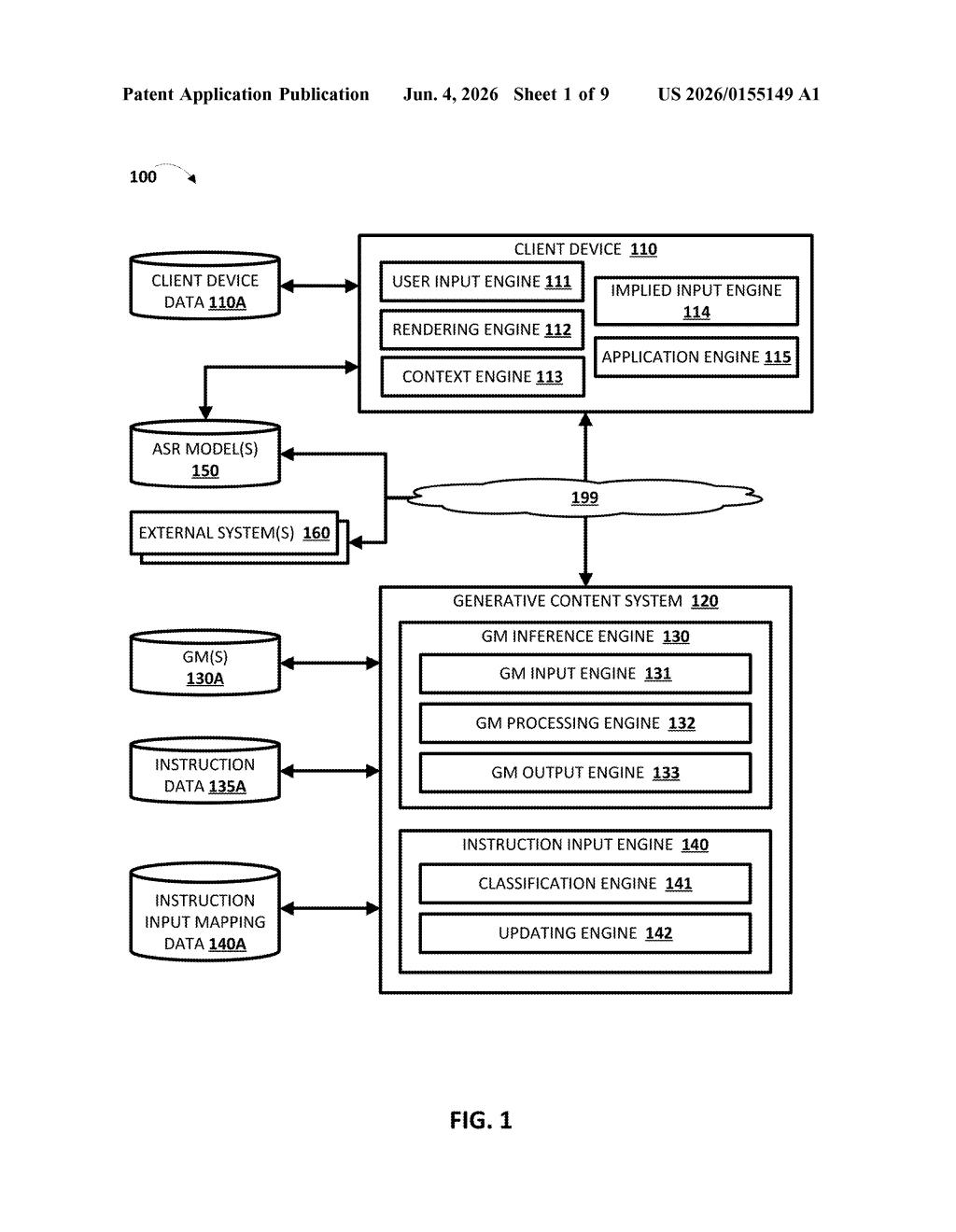
What Google's voice-instruction dictation actually does
Imagine you're driving and want to send a message. You say: "make this formal — I will be unavailable this afternoon." Right now, most dictation tools would transcribe the whole sentence literally, including the instruction. You'd have to clean it up manually.
Google's patent describes a system that uses a large language model to figure out which part of what you said is the actual content you want typed, and which part is a formatting or style instruction. It separates them automatically, then applies the instruction to the content — so "make this formal" shapes the output without ever appearing in the final text.
The result is a voice interface that behaves more like a capable assistant than a simple transcription tool. You don't have to switch modes or use rigid command phrases — you just speak naturally, and the system figures out your intent.
How the LLM splits your words from your formatting commands
The patent describes a two-pass LLM pipeline for processing spoken natural language input. When you speak into a device, the system doesn't just transcribe what it hears — it first routes your input through a first LLM pass to classify and separate the input into two distinct buckets:
- Dictation portion: the actual content you want transcribed or written out
- Instruction portion: any directives you gave about how that content should be rendered — things like tone, casing, formatting, or style
Once the split is made, a second LLM pass (either the same model or a different one) takes both portions together and produces a final transcription that reflects the instructions. So if you say "write this as a bullet point: bring your ID", the output would be a properly formatted bullet, not a literal transcription of your whole utterance.
The patent notably doesn't hard-code specific command words or grammar structures. Because an LLM handles the classification, the system is designed to be flexible — understanding intent from conversational phrasing rather than requiring users to memorize rigid syntax. This is the key architectural difference from traditional voice command systems that depend on fixed keyword grammars.
What this means for hands-free text input on Android and beyond
For everyday users, this is the difference between dictation that demands you speak like a robot and dictation that actually understands what you meant to produce. The ability to embed formatting intent inside a natural sentence — without rigid trigger words — lowers the barrier for hands-free text creation significantly, especially for accessibility use cases.
For Google, this fits squarely into their push to make Gemini-powered features integral to Android's input layer. If voice dictation becomes instruction-aware, it could change how people compose emails, messages, and documents on mobile — and give Google a meaningful edge over simpler transcription approaches baked into competing platforms.
This is a genuinely useful patent — not because it invents something no one imagined, but because it describes a clean, LLM-native architecture for a real frustration that every voice-dictation user has felt. The flexible, grammar-free instruction parsing is the interesting part, and it's the kind of capability that becomes quietly essential once you've used it.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.