Nvidia Patents a Way to Compress Video by Letting AI Pick What Matters
Most image compression treats every pixel as equally important. Nvidia's new patent lets AI models decide which parts of a frame actually need to be high-quality — and compresses the rest harder.
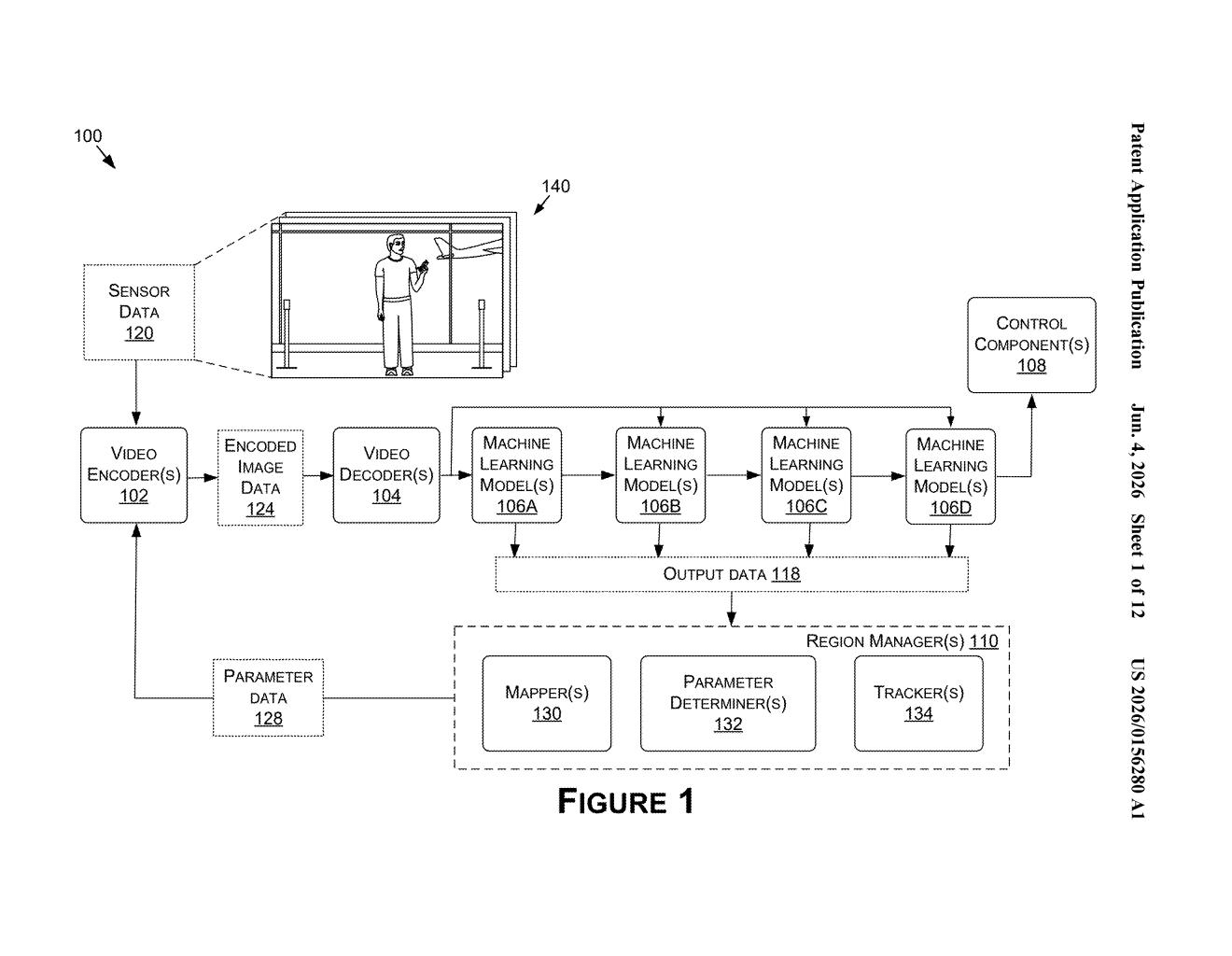
How Nvidia's AI decides which parts of an image to keep sharp
Imagine your car's cameras are sending video to an AI system that watches for pedestrians and stop signs. Most of that frame — the sky, the road surface, a blank wall — doesn't matter much. But the patch of pixels where a person is standing? That part needs to be crisp enough for the AI to work correctly.
Nvidia's patent describes a system where the AI model itself tells the image encoder which regions of a frame are important. The encoder then applies higher quality compression settings to those zones and lower quality to everything else. The result is a smaller file that still gives the AI everything it needs.
The system can also tune itself over time. If the AI starts making mistakes — say, misidentifying objects — the encoding quality for the relevant regions can be bumped up automatically. It's a feedback loop between the compression layer and the intelligence layer, rather than treating the two as completely separate steps.
How the encoder reads ML feedback to set per-region quality
The patent describes a pipeline that sits between image capture and AI inference. Here's the flow:
- Region detection: A machine learning model (MLM) processes incoming sensor data and identifies specific image regions — bounding boxes or segmentation masks around objects of interest.
- Property assignment: Each region gets a set of encoding properties — things like quantization level, bitrate allocation, or resolution — based on how important that region is to the model's output. Importance can be ranked by performance metrics (how much does quality loss here hurt accuracy?) or by explicit priority ordering.
- Adaptive encoding: An encoder generates a compressed image using different quality settings for different regions simultaneously, rather than one uniform setting for the whole frame.
- Feedback loop: When the encoded image is decoded and fed back into the MLM, the system checks whether the model's output on the compressed version matches what it produced on the original. If accuracy drops, the encoding properties for that region are tightened.
The key insight is that compression and inference are treated as a closed loop, not separate stages. The MLM's own performance metrics drive the encoder's decisions, which means quality is allocated where it statistically pays off most.
What this means for autonomous vehicles and edge AI cameras
For autonomous vehicles and robotics, camera feeds are a major source of bandwidth and storage pressure. Systems like these have to transmit or store enormous volumes of image data while running inference in near-real time. A compression scheme that's ML-aware — one that knows a pedestrian's bounding box matters more than the asphalt behind it — could reduce data volume without the accuracy penalties that come from blunt quality reduction.
This also has implications for edge AI deployments more broadly: surveillance cameras, drones, industrial inspection systems. Anywhere you have constrained bandwidth and an AI pipeline downstream, you want your encoder and your model to be talking to each other. Nvidia, which already supplies chips and software for many of these use cases, would be well-positioned to bake this directly into its inference stack.
This is genuinely clever systems work — treating compression as a first-class concern for AI pipelines rather than an afterthought. The feedback loop between model performance and encoder settings is the interesting bit, and it lines up neatly with Nvidia's push into autonomous vehicle and edge inference hardware. Worth watching, especially as Nvidia's DRIVE and Jetson platforms compete on exactly this kind of end-to-end efficiency.
Which company should we read for you?
We track 17 companies here. Pro is the same weekly breakdown for any company you choose, delivered privately. Type a name and we'll scope it and send you a quote.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.