Nvidia Patents a Way to Stop AI Chips from Acting on Unfinished Math
Matrix multiplication is the heartbeat of every AI model — and Nvidia is patenting a way for chips to know exactly how far along a calculation is before acting on it.
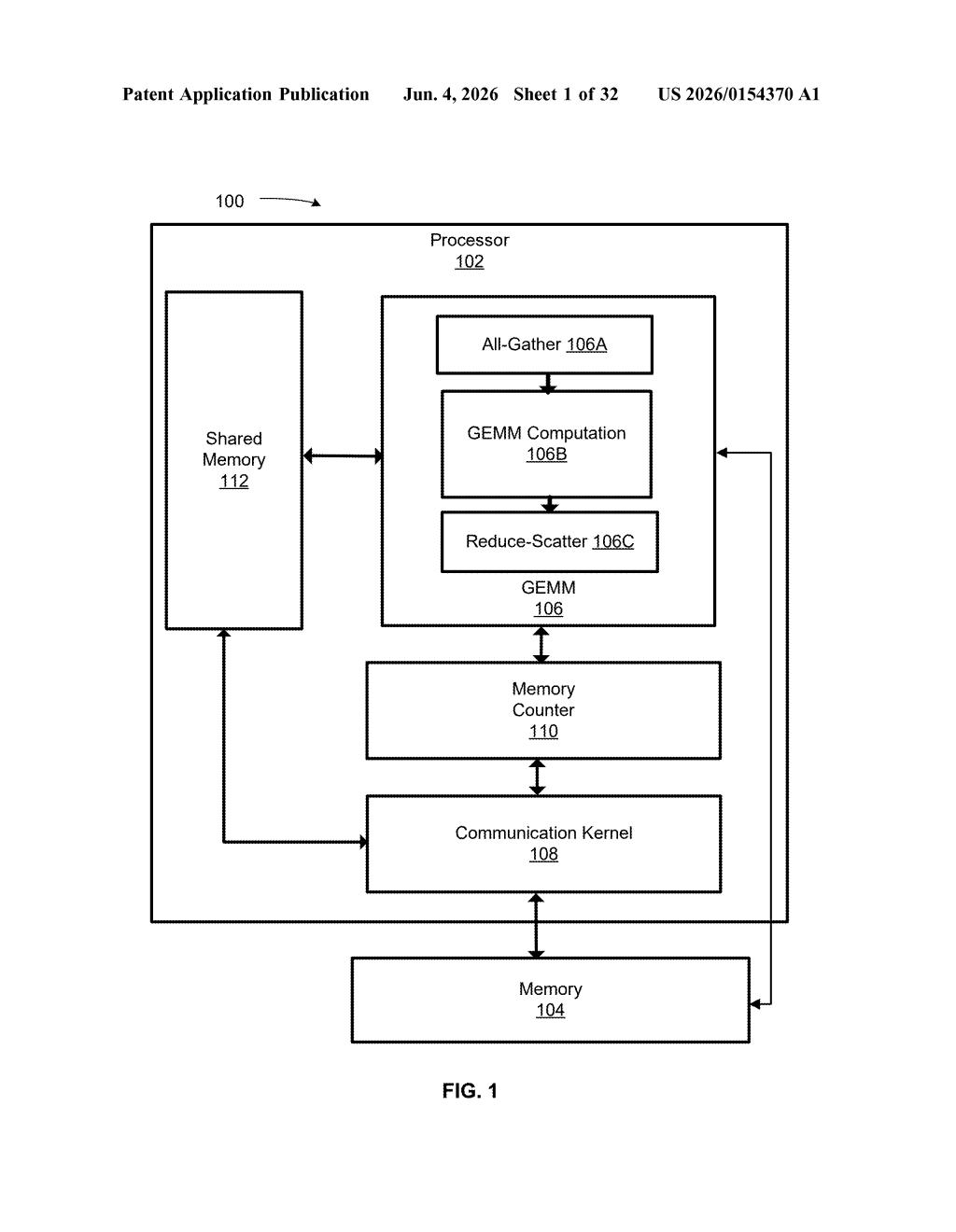
What Nvidia's partial GEMM load signal actually does
Imagine you're baking a cake, but someone keeps asking you to frost it before it's fully out of the oven. Chips running AI models face a similar problem: they need to know whether a block of math is actually ready before they start using the results.
Nvidia's patent describes a simple API — essentially a yes/no signal — that tells a processor whether a matrix multiplication result has been partially loaded into its working memory. Matrix multiplications (called GEMM operations) are the core math behind neural networks, and they produce large intermediate results that flow between units on a chip.
By exposing this status through a formal API, Nvidia gives software and hardware more precise control over when to proceed. That means fewer wasted cycles sitting idle or, worse, acting on incomplete data — a small fix with potentially real gains when you're running billions of these operations per second.
How the API tracks partial matrix multiply results
The patent centers on a processor-level API (Application Programming Interface — here a low-level hardware instruction rather than a web API) that exposes the load status of one or more GEMM (General Matrix Multiply) operations. GEMM is the foundational math routine behind matrix multiplications in neural network layers.
The core idea is straightforward: when a GEMM operation produces a result, that result may be written into an intermediate buffer or register file in stages — partially loaded before the full value is ready. Without visibility into this status, downstream logic must either wait conservatively or risk reading stale data.
The API surfaces a binary or enumerated status flag — essentially answering: has this result been partially loaded yet? Downstream circuits or software threads can query this signal to make smarter scheduling decisions, overlapping work where it's safe to do so.
- GEMM operations: matrix multiplications that power transformer layers, convolutions, and most deep learning math
- Partial load detection: distinguishing between "result not started," "result partially written," and "result fully available"
- API-level exposure: making this status programmable so software schedulers can react to it
What this means for GPU throughput in AI workloads
Modern AI accelerators are bottlenecked not just by raw compute, but by the coordination overhead between compute units and memory. If a GPU's scheduler doesn't know a GEMM result is partially ready, it has to guess — and guessing wrong means either stalling or producing incorrect outputs. An explicit API signal removes that ambiguity, letting hardware and software pipelines overlap more aggressively.
For Nvidia, this fits squarely into the ongoing work of squeezing more utilization out of chips like the H100 and Blackwell series, where GEMM throughput is the single most important performance metric for your LLM training or inference job. Even marginal efficiency gains at this level compound across thousands of GPUs in a data center.
This is a narrow, infrastructure-level patent — not a flashy AI capability, but exactly the kind of low-level plumbing that separates good GPU utilization from great GPU utilization. At Nvidia's scale, a tighter GEMM scheduling primitive is worth filing. It's not a headline product feature, but it's real engineering.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.