IBM Patents a System for Auditing How Well Pre-Trained AI Models Adapt to New Tasks
Pre-trained AI models are everywhere, but knowing whether one has actually learned the right things for your specific task is surprisingly hard. IBM's new patent describes a way to measure that — by scanning the model's internal representations for meaningful structure.
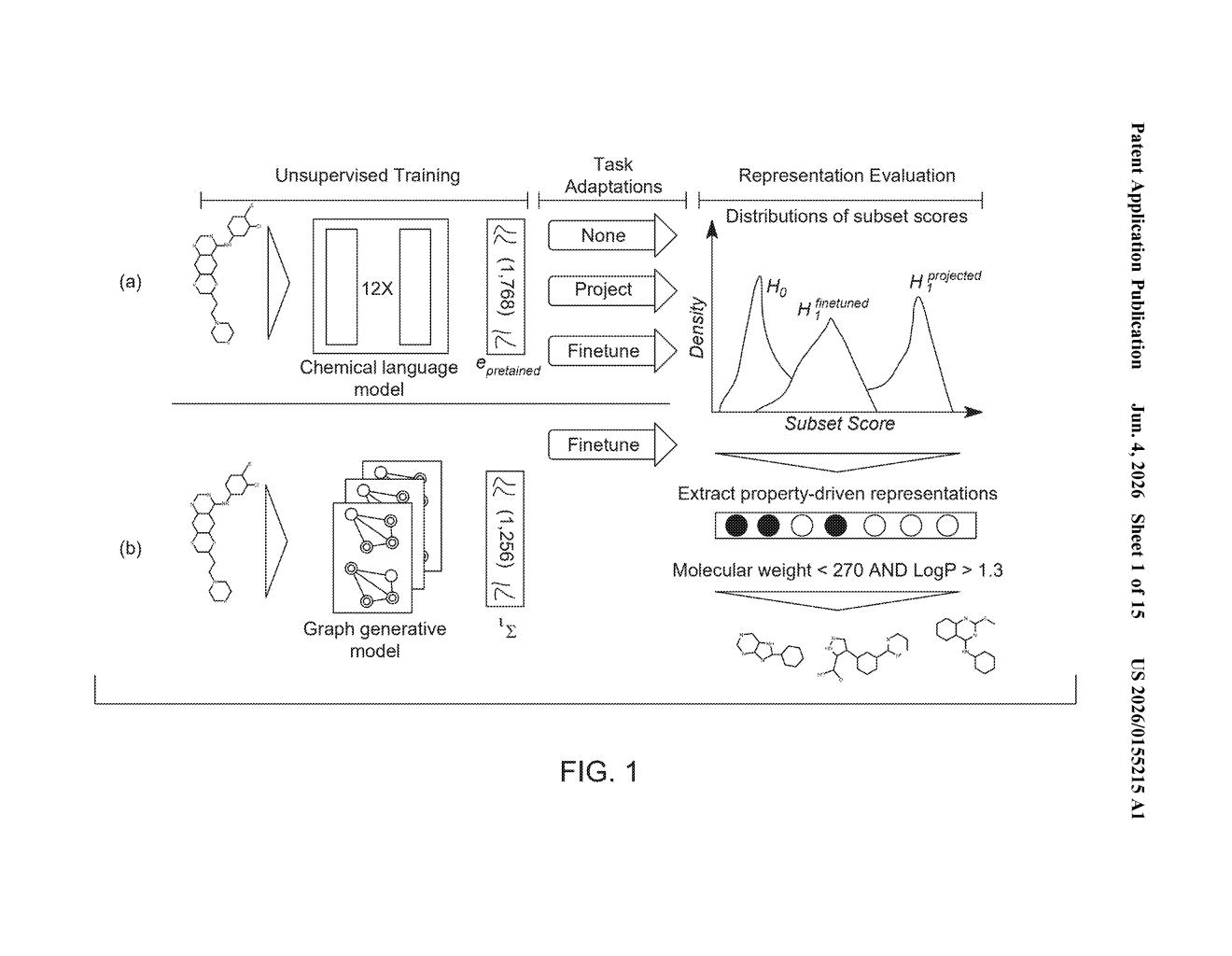
What IBM's AI model auditing system actually does
Imagine you hire someone who trained as a general engineer and you want to know if their skills will transfer well to, say, designing bridges specifically. You'd want a test that reveals whether their mental models of the problem are actually useful — not just whether they sound confident.
That's roughly what IBM's patent addresses for AI. When you take a large pre-trained AI model and fine-tune it for a specific job (say, predicting how a molecule behaves in the body), it's not always clear whether the model has genuinely learned the right internal concepts or just memorized surface patterns. IBM's approach trains a secondary, unsupervised model — one that doesn't rely on labeled examples — to scan the first model's internal "embeddings" (its numeric representations of data) for statistically meaningful clusters and anomalies.
The result is a metric you can use to compare different ways of adapting a pre-trained model, helping researchers pick the approach that actually works best for their domain.
How subset scanning scores an AI's internal embeddings
The patent centers on a technique called non-parametric property-driven subset scanning — a statistical method (originally developed for detecting anomalous clusters in data) that here gets repurposed to characterize the structure of a neural network's embeddings. Embeddings are the high-dimensional numeric vectors a deep learning model uses to represent inputs internally; they're essentially the model's learned "vocabulary" about the world.
The process works in two steps:
- Characterization: An unsupervised secondary model (one that needs no labeled training data) uses subset scanning to identify which subsets of the embedding space have statistically unusual properties — essentially finding where the model has formed meaningful internal structure versus where it's noisy or uninformative.
- Evaluation: Those characterizations are turned into a quantitative metric that lets you compare multiple domain adaptation methods (techniques for fine-tuning a general model to a specific task) head-to-head.
The claim specifically mentions improving interpretability of deep molecular representations — embeddings learned from molecular data, which suggests the primary application IBM has in mind is computational chemistry or drug discovery, where understanding why a model makes a prediction is as important as the prediction itself.
Why this could matter for AI models used in drug discovery
For anyone working in AI-assisted drug discovery or materials science, choosing the right fine-tuning strategy for a large pre-trained model is a major practical bottleneck — and today there's no widely accepted, principled way to compare options. IBM's metric-driven approach could give research teams a more objective benchmark instead of relying on downstream task performance alone, which can be noisy and expensive to measure.
More broadly, the ability to audit what a model has actually learned — rather than just what it outputs — is a growing concern in enterprise AI deployments. If this approach generalizes beyond molecular data, it could become a useful tool in IBM's broader AI governance and explainability portfolio.
This is a niche but genuinely useful idea aimed squarely at researchers who fine-tune large pre-trained models for scientific applications. It's not a consumer-facing invention, and it won't ship as a product you'll ever directly interact with — but IBM's Watson and watsonx platforms are exactly the kind of place where an embedding-auditing tool like this would quietly add real value for enterprise AI teams.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.