Intel Patents a Reconfigurable Chip Array for Running Neural Network Layers
Running a convolutional neural network efficiently is hard partly because each layer wants a different compute shape. Intel's patent describes a processor array that can reconfigure itself on the fly to match each layer's demands.
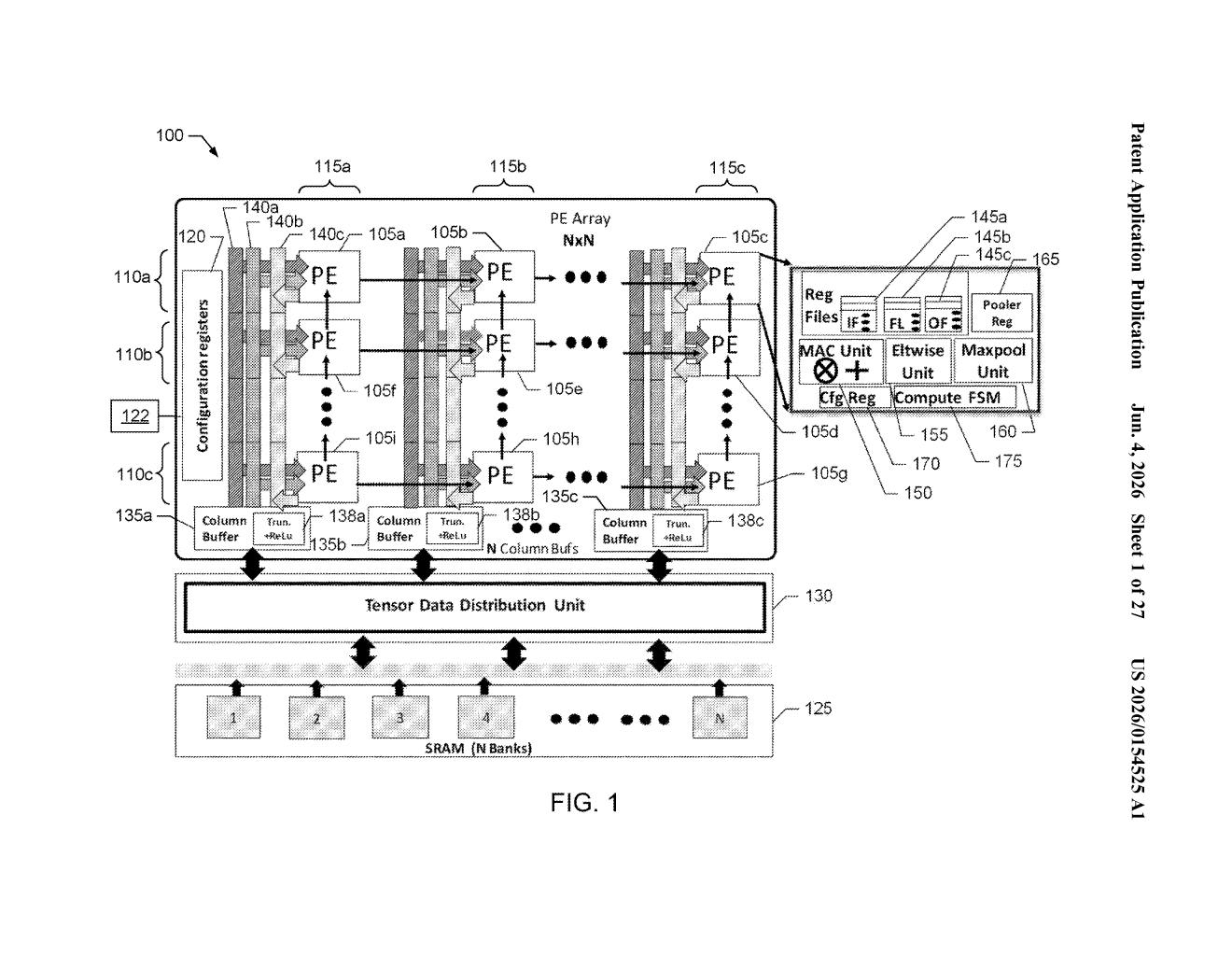
What Intel's shape-shifting processor array actually does
Imagine trying to pour water into a series of containers — each a different shape. You'd want a pitcher that could reshape itself rather than carry a dozen different ones. That's roughly the problem Intel is tackling here.
A convolutional neural network — the kind of AI model that recognizes faces in photos or objects in video — is made up of many layers, and each layer has different computational needs. Most chips either waste resources (too much hardware sitting idle) or bottleneck (not enough of the right hardware at the right time).
Intel's patent describes a grid of small processor elements that can be reconfigured between layers using simple configuration registers — essentially stored instructions that tell each processor element what role to play. The goal is to squeeze more performance and efficiency out of the same physical hardware, rather than building a separate, fixed chip for every possible network shape.
How the configuration registers reprogram the array per layer
The patent describes an array of processor elements organized in rows and columns. Each element is a small, general-purpose compute unit. What makes the design interesting is that the array isn't locked into one topology — it can be reconfigured to match the specific computational pattern, or dataflow schedule (the order and direction in which data moves through the array), required by any given layer of a CNN.
This reconfiguration happens through configuration registers — small, fast storage locations that hold descriptors, which are essentially compact instructions defining how the array should be wired up and what each element should do. Different CNN layers (convolution, pooling, activation) map onto different tensor processing templates — predefined patterns of data movement and computation.
The array operates on three types of data:
- Input activation data — the feature maps coming into a layer
- Filter data — the learned weights that define what the layer detects
- Output activation data — the results passed to the next layer
All three live in on-chip memory tightly coupled to the array, minimizing the costly trips to external DRAM that slow down most AI inference workloads.
What this means for dedicated AI inference hardware
For AI inference chips — the hardware that runs a trained model rather than training it — efficiency is everything. Data centers pay per watt, and edge devices like cameras or drones run on batteries. A chip that can reshape its compute fabric to fit each CNN layer wastes far less silicon and power than one designed around a one-size-fits-all layout.
This patent fits squarely into Intel's broader push to compete in the AI accelerator market against Nvidia, AMD, and custom silicon from Google and Amazon. Whether or not this specific design ships, it signals Intel is investing in flexible, template-driven dataflow architectures — an approach that could show up in future Gaudi or edge-AI products. For you as an end user, the payoff would be faster, more power-efficient AI in everything from cloud services to local devices.
This is solid, unsexy infrastructure work — the kind of deep hardware patent that rarely makes headlines but underpins real competitive advantages. The claims were canceled in this publication, which usually means a continuation or reexamination is in progress, so treat this as a snapshot of Intel's architectural thinking rather than a finished product. It's worth tracking if you follow AI accelerator competition.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.