Google Patents a Training Method That Teaches Its Image Generator to Match Words More Precisely
Getting an AI image generator to reliably produce what you actually described — not just something plausible — is harder than it sounds. Google's new patent tackles that gap by teaching its model to treat matching text and images like a game of attraction and repulsion.
What Google's text-to-image training trick actually does
Imagine you ask an AI to draw "a red barn at sunset with horses in the foreground." A lot of AI image tools get the gist but miss details — maybe the horses are blurry, or the sunset colors bleed into the wrong places. The core problem is that the AI doesn't have a sharp sense of which words correspond to which parts of the image.
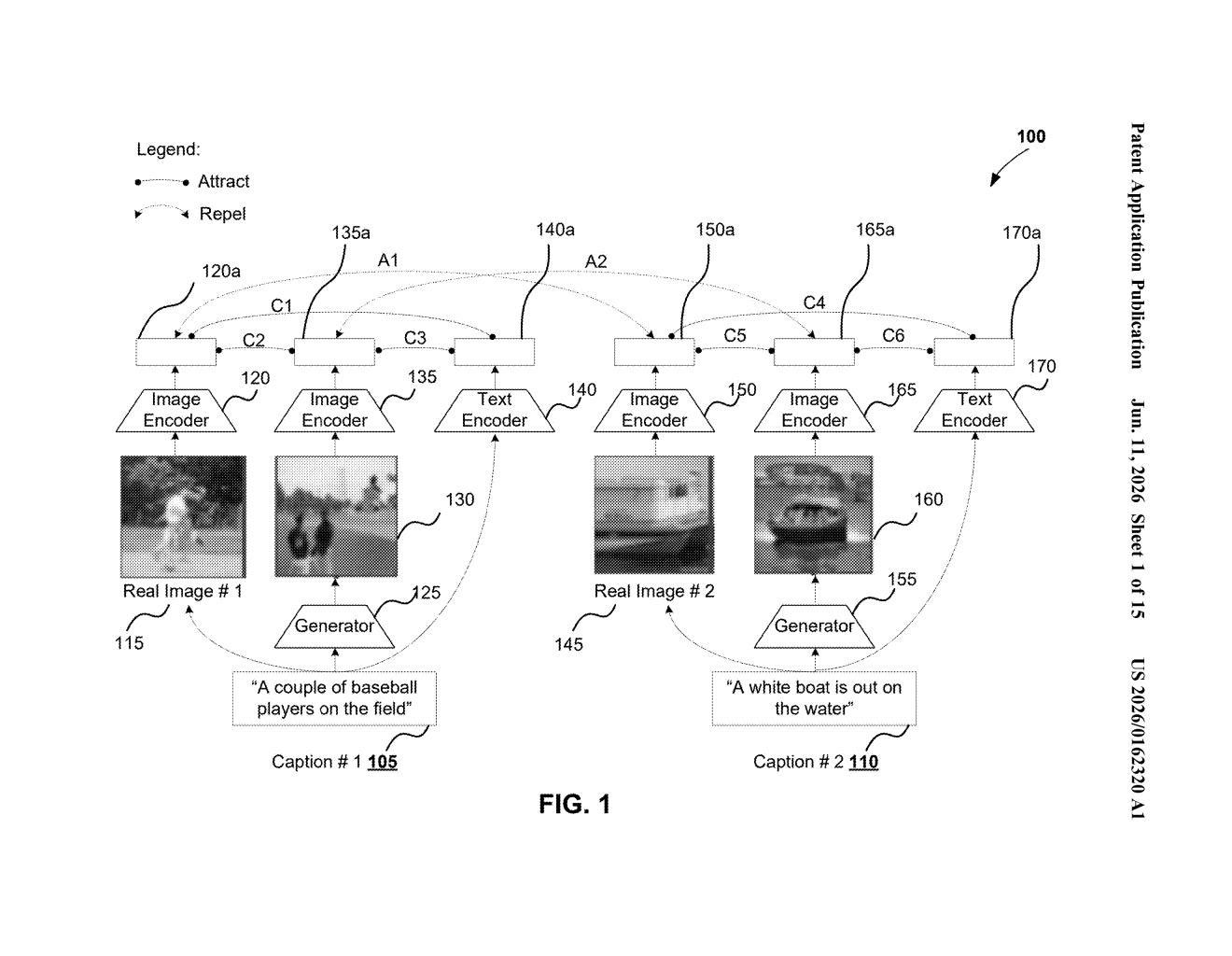
Google's patent describes a training approach that fixes this by teaching the model two lessons at once. First, different AI-generated versions of the same description should look similar to each other. Second, images generated from different descriptions should look clearly distinct. Think of it like a magnet system: same-description images attract, different-description images repel.
To do this, the system pays attention to individual words and links them to specific regions of the image it's building. A "critic" network then grades the result — not just on whether the image looks realistic, but on whether the words and image regions genuinely match. The whole process runs through a single generation step rather than multiple refinement passes.
How the contrastive loss and attention mechanism work together
The patent describes a training framework for a text-to-image synthesis model — an AI that turns written descriptions into pictures.
The key innovation is how the model learns during training. It uses contrastive learning (a technique where the model is rewarded for grouping similar things together and penalized for confusing different things) across two types of comparisons at once:
- Image-to-image pairs: Two different AI-generated images based on the same text description should resemble each other.
- Text-to-image pairs: A generated image should clearly correspond to its source description, not to unrelated ones.
To connect words to the right parts of the image, the model uses an attention mechanism (a technique that lets the AI focus on specific inputs — here, specific words — when generating specific outputs, like a region of a picture). For each sub-region of the image being generated, the model computes a word-context vector (essentially a weighted summary of which words are most relevant to that region) and uses it to shape how that part of the image looks.
Critically, the generator is single-stage — it produces the final image in one pass rather than generating a rough draft and then refining it through multiple upsampling steps. A separate critic network evaluates how well the output satisfies those contrastive objectives and sends penalty signals back to improve the generator's weights.
What this means for AI image generation quality
For people who use AI image tools, better text-image alignment means fewer frustrating mismatches between what you typed and what you got. The more precisely a model can tie individual words to specific image regions during training, the more likely your "red barn at sunset" actually has a red barn — and not a brown shed at noon.
For Google specifically, this kind of training improvement is directly relevant to products like Imagen and any generative AI features baked into Search, Workspace, or Android. The single-stage generator approach also hints at efficiency gains — fewer compute-heavy refinement passes could mean faster generation or lower infrastructure costs at scale.
This is solid, incremental AI research rather than a headline-grabbing leap — the contrastive learning approach it describes is a well-established technique being carefully adapted for image generation. What makes it worth noting is the combination: enforcing both image-to-image and text-to-image consistency simultaneously, in a single-stage generator, is a meaningful architectural choice that could translate into measurably better outputs.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.