Nvidia Patents a Neural Network System That Compresses Video by Reading Images at Two Depths
Nvidia is patenting a video compression approach where neural networks analyze each frame twice — once for big-picture content, once for fine detail — before deciding what to keep and what to throw away.
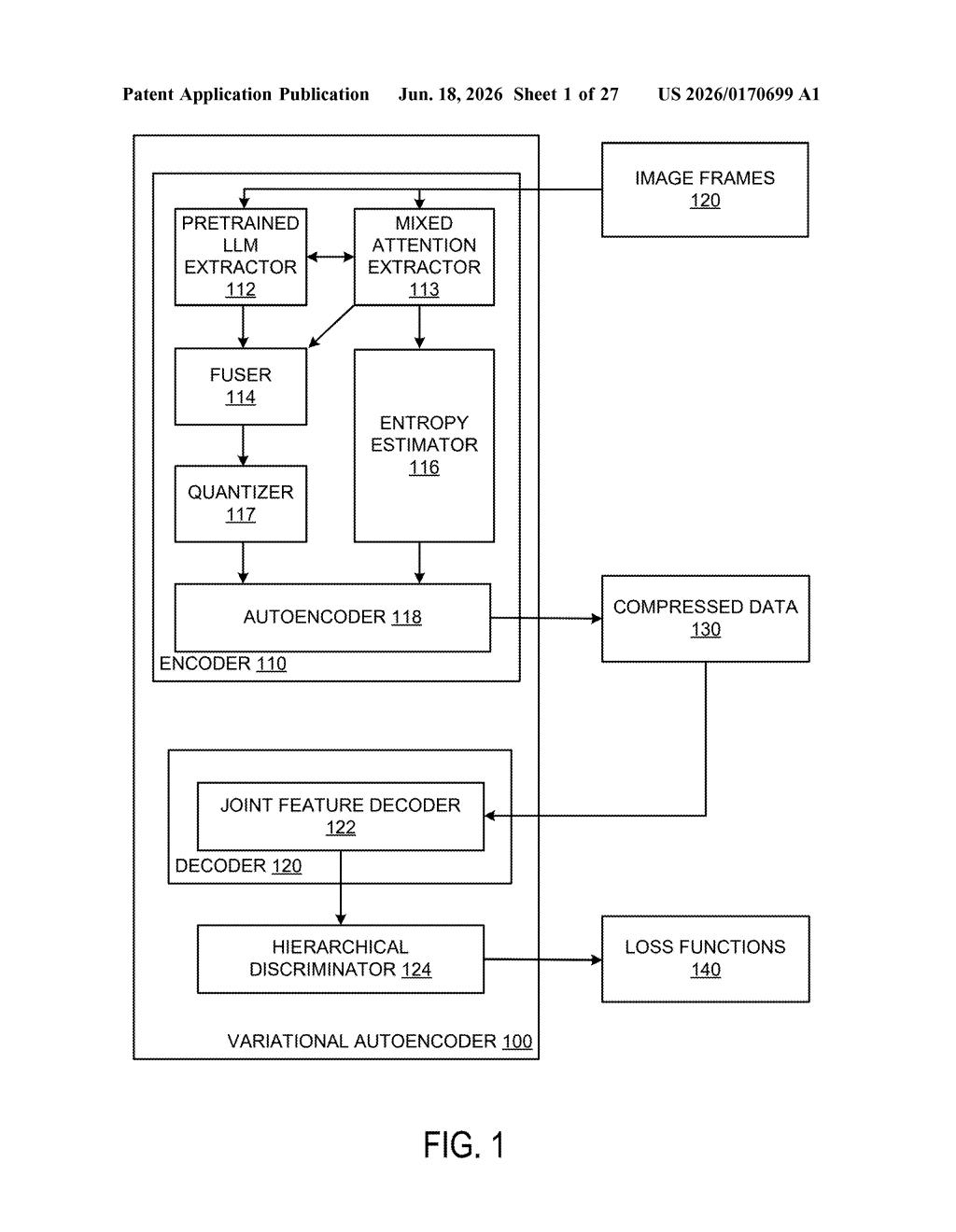
How Nvidia's two-layer image reading cuts video file size
Imagine you're packing a suitcase. A bad packer throws everything in at random. A good packer folds the big bulky items first, then tucks the small ones into gaps. Nvidia's patent describes something similar for video files.
When your phone or laptop stores or streams a video, it has to compress the footage — shrinking the file without making it look terrible. Nvidia's idea is to run each video frame through two separate neural networks at once: one that looks at broad, high-level features (what's in the scene, where objects are) and one that captures fine, low-level details (edges, textures, subtle gradients). The two outputs get merged into a single combined description, which is then compressed.
The goal is a compression system that doesn't have to choose between keeping the big picture or the small details — it keeps both, packaged together efficiently. That's the pitch, at least.
How the dual-level feature extractor feeds the encoder
The patent describes a processor and accompanying neural network pipeline designed to compress video frames more efficiently by extracting features at multiple levels of abstraction simultaneously.
In traditional video codecs (the software engines that compress video — think H.264 or AV1), compression decisions are largely hand-crafted by engineers. Nvidia's approach delegates those decisions to neural networks — AI models trained to identify what information matters most in an image. The twist here is running two separate networks in parallel: one focused on high-level features (semantic content — what objects are present, how they relate) and one on low-level features (pixel-level detail — sharpness, color gradients, fine textures).
The outputs of both networks are then combined into joint feature information — a single merged representation that captures both layers of detail. That merged output is what gets compressed and stored or transmitted.
The first independent claim is notably broad: it covers any processor that causes "object feature information" inferred by neural networks to be compressed alongside "descriptive information" about those features. That breadth could cover a wide range of AI-driven encoding implementations, though how courts would interpret it is a separate question entirely.
What this means for video streaming and AI pipelines
Video compression is one of the most computationally expensive things data centers and consumer devices do every day. If Nvidia can show that a neural-network-based encoder outperforms traditional codecs on quality per bit — especially at the high resolutions its GPUs are often rendering — there's a real commercial angle here for its data center and media-processing businesses.
For everyday users, better compression means higher-quality video at the same bandwidth, or the same quality at lower storage costs. It also fits into Nvidia's broader push to embed AI inference into every layer of the media pipeline, from capture to playback. Whether this specific architecture clears the bar over existing learned-compression research (which is already a busy academic and industry field) is the real open question.
This is a solid but not surprising entry from Nvidia into the learned video compression space — academic labs and companies like Google have been working on neural codecs for years. The dual-level feature extraction idea is a legitimate engineering approach, but the first claim is written so broadly that its real value will depend heavily on prosecution history and prior art. Worth tracking as a signal of where Nvidia wants its GPU-accelerated encoding to go, but don't expect a product announcement tomorrow.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.