Samsung Patents a Way to Train Video AI on Deliberately Distorted Frames
Samsung's latest patent describes a training trick for video AI: deliberately mess up a frame, then punish the model if its answers change. The idea is that a truly good AI should recognize the same objects whether the image is clean or slightly scrambled.
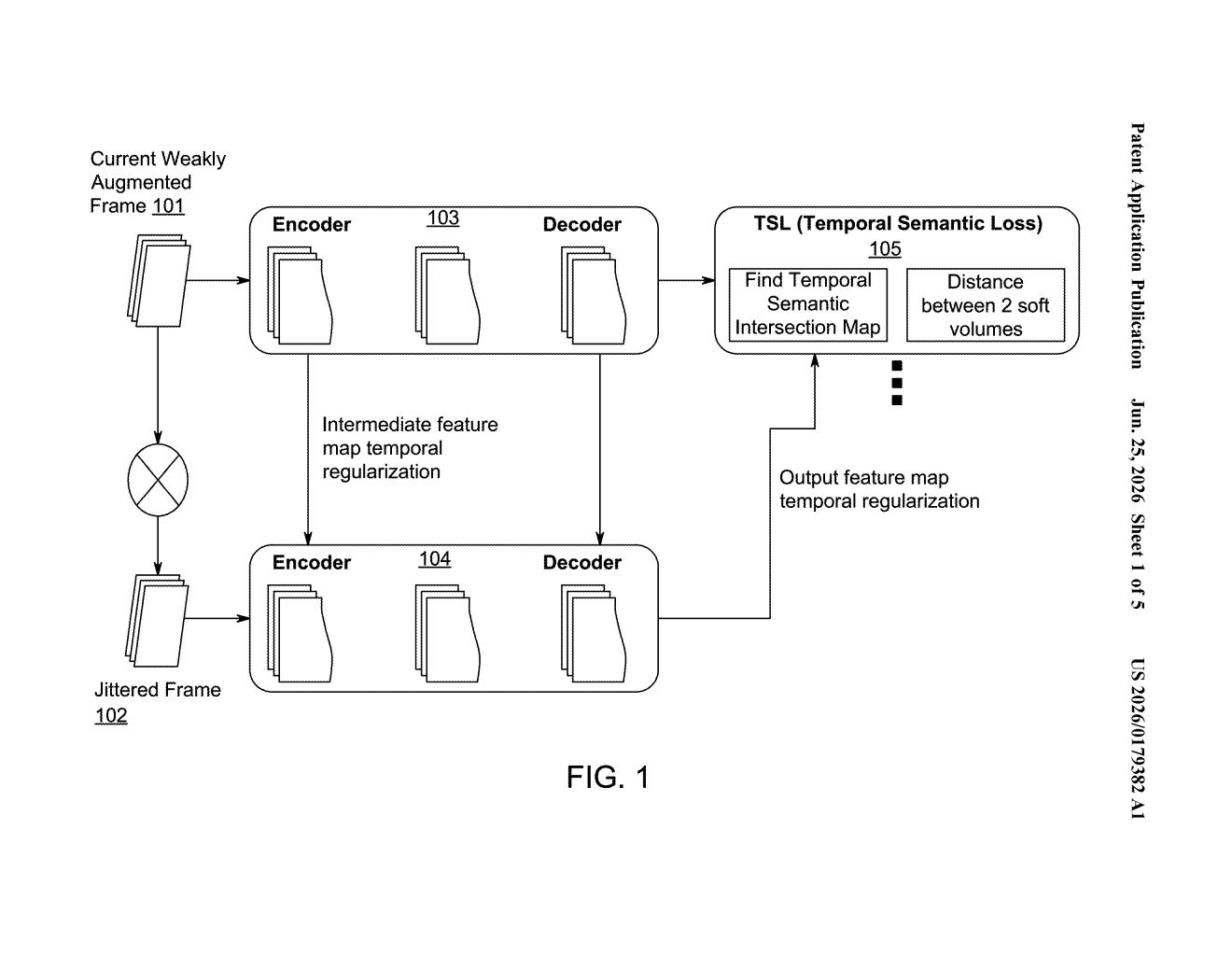
What Samsung's jittered-frame video training actually does
Imagine you're learning to recognize faces. A good teacher might show you a photo, then show you the same photo with the brightness slightly off or the image a little blurry, and ask: 'Is that still the same person?' If your answer changes, you need more practice.
Samsung's patent applies that same logic to video AI. The system takes a single video frame, creates a slightly distorted copy of it (think: minor warping, color shift, or blur), and then checks whether the AI's identification of objects stays the same across both versions. If the AI's answer flips, the training process penalizes it.
The goal is a video AI that labels objects consistently from one moment to the next, even when lighting or camera motion causes each frame to look a little different. That kind of stability is hard to get without labeling thousands of hours of footage by hand, which is exactly what this approach tries to avoid.
How the distortion-comparison loop trains the network
The patent describes a semi-supervised training method for video segmentation, meaning the AI can learn from mostly unlabeled video data rather than requiring every frame to be hand-annotated by a human.
The core step is temporal regularization (a penalty applied during training that pushes the model toward consistent predictions over time). Instead of comparing the current frame to the previous frame in the video, the system generates a jittered version of the same frame by applying a computer-controlled image distortion. The model then produces segmentation predictions (pixel-by-pixel labels like 'this is a car,' 'this is a person') for both the original and the jittered copy.
- If the predictions agree, the model gets a good score.
- If the predictions diverge, a loss penalty is applied and the model's weights are adjusted.
- This loop repeats across training data, nudging the network toward stability.
The result is a frame-level segmentation network that has learned to ignore small visual inconsistencies, the kind that show up constantly in real video due to motion blur, compression, or lighting changes.
What this means for AI video editing and recognition
Video segmentation is the backbone of a wide range of features: background replacement in video calls, object tracking in cameras, scene understanding for autonomous systems, and AI-powered video editing. Getting it to work consistently across frames without expensive labeled data is an ongoing challenge for the whole industry.
For Samsung specifically, this kind of technique could find its way into on-device camera processing, Galaxy AI video tools, or computer vision systems in their broader electronics lineup. The semi-supervised angle is the practical win here: if you can train a reliable model with far fewer hand-labeled frames, you cut the cost and time of building video AI products significantly.
This is solid but unspectacular research. The 'jitter a frame and compare predictions' idea is a clean extension of consistency-based semi-supervised learning, which has been an active research area for several years. Samsung isn't inventing a new category here, but packaging it into a patent around video segmentation training is a reasonable defensive move for a company that ships cameras and AI features at scale.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.