Intel Patents a Trick That Cuts Shared Memory Wait Times in Half
When multiple chips share the same pool of memory, the slowest part is often just fetching the data in the first place. Intel's new patent describes a way for devices to say 'I'm going to need that soon' — so the host can have it ready before the request even arrives.
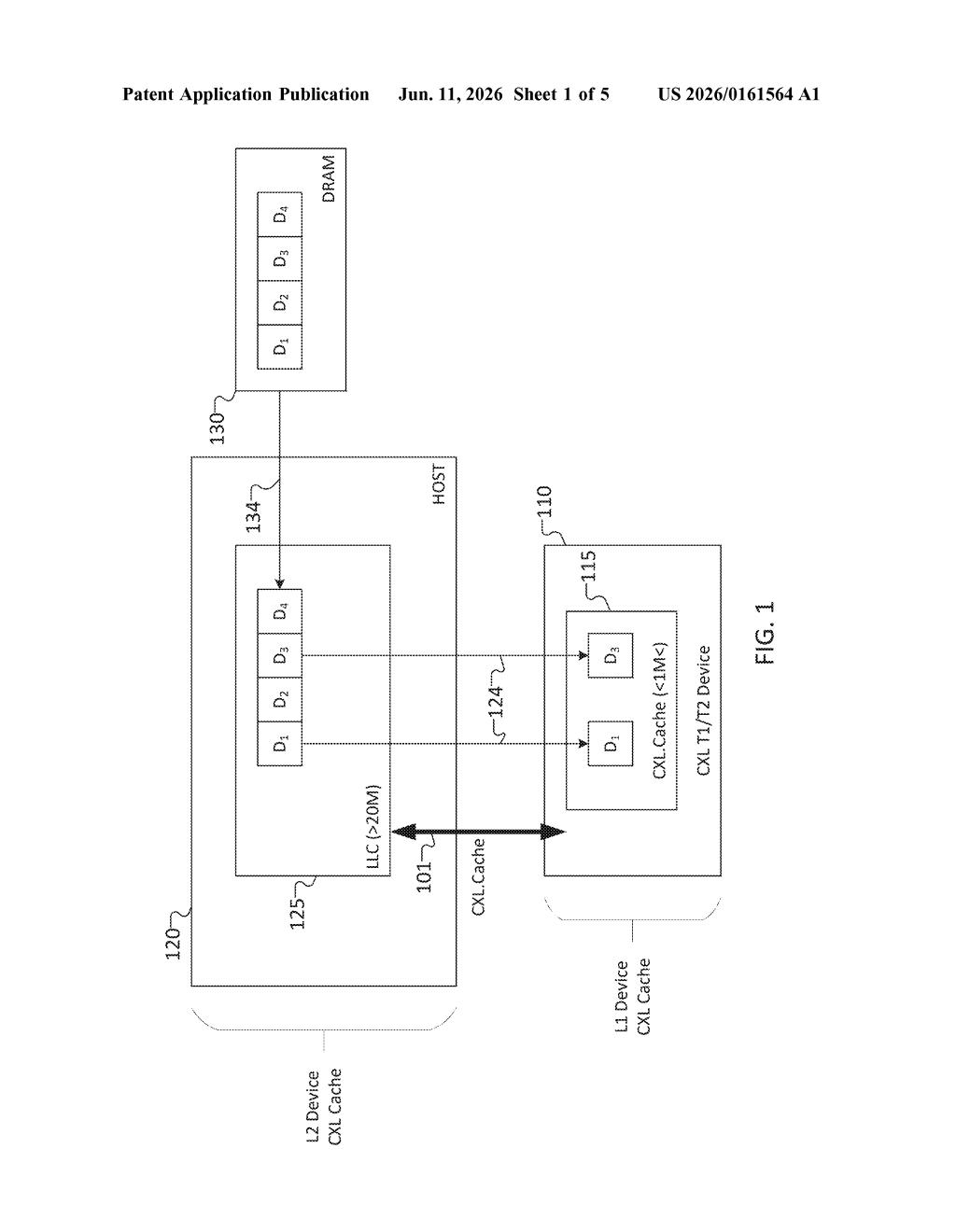
What Intel's cache warm-up system actually does
Imagine a busy restaurant kitchen where every cook has to walk to the walk-in freezer every time they need an ingredient. Now imagine a prep cook who reads the night's menu in advance and stocks the countertop before service starts. Intel's patent is essentially that prep cook, but for computer chips.
In modern data centers, multiple processors or accelerators often share a big pool of memory over a high-speed link called CXL. The problem is that every time a chip needs a piece of data, it has to wait for that data to travel from slow main memory (think: the freezer) into the chip's fast local cache (think: the countertop). That wait adds up.
Intel's idea is to let a device send a "warm-up request" ahead of time — essentially a heads-up to the host chip that says "load this data into your fast cache now, because someone's going to ask for it shortly." When the real request arrives, the data is already waiting, and the delay nearly disappears.
How the warm-up request moves data before it's needed
The patent describes a system built around the CXL.cache protocol — a standard that governs how multiple devices share memory coherently (meaning every chip always sees the same, up-to-date version of any data, with no stale copies causing errors).
Under normal operation, when a device needs a cache line (a small fixed-size chunk of data, typically 64 bytes), it sends a request to a home agent — the host component responsible for keeping all copies of that data in sync. The home agent then fetches it from DRAM (main system memory, which is slower) and hands it back. That round-trip is the bottleneck.
The patent introduces a warm-up request — a new type of message a device can send that says: "please prefetch these specific cache lines into your last-level cache (LLC) now." The LLC is a fast on-chip cache that sits between slow DRAM and the requesting devices. By loading data there proactively, the host can serve the actual data request almost instantly when it arrives.
Key mechanics include:
- The device identifies specific target cache lines in the warm-up request
- The host reads those lines from DRAM into its LLC without waiting for a formal data request
- Coherence rules still apply — the host keeps all copies consistent across all sharing devices
- The approach works with CXL Type 1 and Type 2 devices (accelerators and memory expanders)
What this means for data-center chip interconnects
CXL (Compute Express Link) is shaping up to be the backbone of how next-generation AI accelerators, memory expanders, and CPUs talk to each other inside data centers. Latency — how long it takes data to travel between components — is one of the central engineering challenges of that architecture. A mechanism that lets devices "pre-order" their data before they need it is a straightforward but meaningful tool for squeezing more performance out of shared-memory systems.
For you as an end user, this kind of improvement is invisible but consequential: faster data-center chips mean faster AI inference, faster cloud apps, and lower operating costs that can flow through to pricing. Intel is clearly positioning itself to show that CXL, as a standard it helped create, can be tuned for real-world performance — not just theoretical bandwidth numbers.
This is unglamorous plumbing work, but it's the kind of patent that actually ships. Pre-fetching data before it's explicitly requested is a well-understood technique — what's notable here is Intel applying it specifically to the CXL coherence layer, which is where data-center architects are increasingly focused. Worth watching as CXL adoption accelerates.
Get one Big Tech patent every Sunday
Plain English, intelligent commentary, no hype. Free.
Editorial commentary on a publicly published patent application. Not legal advice.